It’s well-known that science appears to be getting substantially more expensive on the margin. I’ll call this science friction.
The studies which reach this conclusion operationalize “scientific progress” in two broad ways:
Scientific progress = total factor productivity.
Changes in scientific progress can be detected using science-internal metrics of change (e.g. networks of citation).
Explanations of science friction fall into three categories:
Institutional explanations.
The low-hanging fruit has already been plucked.
There is a burden of knowledge which grows as science advances.
Science is cumulative in explanatory power, so some burden of knowledge is inevitable as long as explanatory power is not orthogonal to computational complexity.
That being the case, shouldering the burden of knowledge will cost more research effort over time. In the long run, unless the total available research capacity grows at a faster rate, this will consume asymptotically all research effort. The total available research capacity would seem to be able to continue growing indefinitely only if:
Scientific knowledge is infinitely modularizable (there’s no limit to specialization as a proportion of total knowledge) and the population of available researchers keeps growing, or
Scientific knowledge can be offloaded to non-human entities, e.g. books, databases, and AI, without losing its utility for future innovation.
The burden of knowledge is a bigger problem if you think that science is intrinsically valuable, rather than just a means to technological capacity enhancement.
All of this being said, the institutional problems of science deserve more attention than the burden of knowledge because they’re more tractable.
Epistemic Status
This is an introductory and speculative post which I wrote for my blog. It’s less strictly organized and more narrative-y than something I’d have written specifically for the EA Forum. It’s also the result of a shallow investigation, and not on a topic that I’m anywhere close to an expert on. Nonetheless I think it contains a few vague ideas which those of you who are interested in metascience and/or longtermism might find interesting. I think it’s especially relevant to conversations about stagnation.
The first two sections after the intro (“What is Scientific Progress?” and “Three hypotheses about science friction”) can be skipped by people who know the first few things about this topic.
Introduction
Science seems to be getting harder. The evidence supporting this claim has been summarizedelsewhere, so for the sake of argument this post takes it for granted. On average, every unit of “scientific progress” costs more researcher-hours than the one before it. The marginal cost of scientific progress is increasing. Call it science friction.
One explanation of this phenomenon posits a “burden of knowledge” which causes educational costs to grow as science advances. Recently, I read two thought-provoking blogposts by Maxwell Tabarrok which took issue with this explanation. I began drafting comments containing a bit of pushback on some of the arguments Tabarrok raised, but the subject came to feel worthy of a full-length post. In particular, I’d like to disentangle the intuition behind the burden of knowledge, offer a few key conceptual obstacles to proposed solutions, and argue that the magnitude of the problem depends on what you think the purpose of science is.
But first, 150 seconds of context.
What is Scientific Progress?
Scientific progress is a slippery concept, so I’m not going to offer a definition. To ground the conversation, however, here are two general ways it gets operationalized in metascience research:
To an economist, scientific progress is anything that allows our economy to do more with the same quantity of resources. “Resources” are all the tangible inputs to economic growth: labor, land, materials, tools, and the rest. Scientific progress is then anything which increases total factor productivity (TFP), the intangible component of economic growth models. In the coarsest possible terms, GDP = F(TFP, (labor input), (capital input)), an an increase in TFP counts as scientific progress. The famous 2020 paper “Are Ideas Getting Harder to Find?” compares TFP growth to scientific inputs:
The upshot? Yup, ideas are getting harder to find.
We can also try to measure scientific progress by looking at data internal to science: scientific publications themselves, for instance, and the way that they cite each other. The 2023 article “Papers and patents are becoming less disruptive over time,” published in Nature, introduces a metric of the impact that papers and patents have on networks of citation, with the result that “papers and patents are increasingly less likely to break with the past in ways that push science and technology in new directions.” This blog post from metascience researcher Matt Clancy presents a grab-bag of such science-internal metrics, all of which show increasing scientific friction (my favoritemethods use linguistic cues from article titles and author-supplied keywords).
Three hypotheses about science friction
The proposed explanations of science friction seem to fall into three main categories.
The low-hanging fruit has already been plucked: I won’t spend a lot of time on this explanation, but it’s popular and intuitively appealing, if rather hard to pick apart. We’ve already discovered the easiest stuff to discover, so we should expect finding out new, important things to be increasingly difficult.
The burden of knowledge: this idea is related to, but distinct from, #2. Basically: the more we learn about science, the more effort it takes to get aspiring researchers up to speed, leaving fewer resources available to push the boundaries of knowledge forward. This could manifest in an older average age of discovery, more expensive or time-consuming education, or (as in the paper which popularized the burden of knowledge idea) increasing specialization and larger teams. In some sense, future ideas may be no more intrinsically “complicated” or “challenging” than past ones, once you’ve got the prerequisite knowledge. Let’s say many of them are just a matter of putting a few previous ideas together in a process of combinatorial innovation. But even if that were the case, understanding previous research to the point where one is capable of recombining it into something new might take longer and longer.
Knowledge doesn’t grow monotonically, but it is cumulative
Tabarrok compares studying science friction to studying a car:
“[Jones et al] explain [science friction] by positing some inherent drag on idea exploration that gets more burdensome as we learn more. Something like inertia which makes it harder to double the speed of a car that’s already going fast than a car that starts slower.
But without knowing the underlying kinetics of science and economic growth, this inertia model is just a guess. There are lots of other explanations which are consistent with the observation of diverging fuel use and acceleration. Our car could be going up a hill, or over a rough and rocky road. Or our engine could be depreciating or using the extra fuel inefficiently. Similarly, the ideas we produce might face growing barriers before they can materialize as physical products and buildings which affect productivity. Or our institutions of science are squandering the extra resources they receive with inefficient institutional designs.”
This is a good analogy. It’s true that we really don’t have a good handle on the “underlying kinetics” of scientific progress. But it’s not the case that we don’t know anything about them. I’d like to argue that one important feature of science—which Tabarrok seems to deny and which is the key intuition behind the burden of knowledge idea—is that it is an essentially cumulative enterprise. Science seeks to accumulate good explanations of phenomena which we observe in the world, up to some criteria of “goodness” involving things like explanatory accuracy, predictive power, and model parsimony. Science is about buildingknowledge, and is therefore cumulative almost by definition.
Tabarrok acknowledges this: “It’s hard to imagine a model of scientific progress without accumulating knowledge.” But later, under the header “Knowledge is Often Not Cumulative,” Tabarrok offers an example which seems to contradict this property. By putting the sun (rather than the earth) at the center of our astronomical neighborhood, Copernicus dramatically simplified orbital mechanics, thereby apparently making knowledge simpler, more elegant, and altogether rather smaller. Many scientific advances look something like this, where new models seem to distill those that they are replacing in a simpler, more unified way.
These instances do reduce the amount of breath we need to expend to explain all of the details of our scientific models. But it is explanatory power, not model complexity, that we’re trying to accumulate; individual models are merely a means to that end. After Copernicus, science still explained just as much of the world as before, and it did so more accurately. Scientific knowledge did continue to accumulate, it just did so along a dimension orthogonal to the complexity of that particular model. Ultimately, the goal is to explain ever more of our universe’s workings ever better. “More” and “better” are the operative words there. That being the case, it seems very hard to envisage an underlying scientific dynamic in which the overall trend is not for knowledge to get gradually larger over time.
It’s a bit like we’re trying to fill a computer hard drive with simulations which can be used to approximate all of the empirical phenomena that we’re interested in. Given some practical setting, then, we can load the relevant program and answer questions about it. The scientific endeavor gradually loads more files on our hard drive, while breakthroughs like Copernicus’ occasionally come along and compress these files in a more efficient way. The bottom line, though, is that if we want to explain more stuff, we will eventually need more storage space for all of our explanations.
(Image creds to DALL-E 2)
Note that this account relies on “explanatory power” being at least somewhat dependent on computational complexity. This claim, in turn, relies on the assumption that the objects of scientific study contain a certain level of intrinsic complexity, or computational irreducibility. One might hope that a few very parsimonious descriptions might do the trick: that we might be able to load just one or two programs on our hard drive and use them to explain everything we care about. In a very specific way, this might be right. It’s kind of what physics is trying to do by reducing all of nature to just a few fundamental components. In a rather truer way, however, there appears to be a certain amount of computational irreducibility inherent in many of the phenomena we care about. Even if all processes are fundamentally physical, in practice we need to break them into groups and delegate them to sciences other than physics.
(Stephen Wolfram has noted that some very simple cellular automata display computational irreducibility: their evolution cannot be precisely predicted in a faster way than by running each step of their computation.)
But if explaining more ultimately means carrying a heavier burden of pre-existing knowledge, then absent countervailing forces, more and more of our scientific resources will have to go towards education. Pessimistically, this view seems to entail that asymptotically all of scientists’ efforts will be eventually be taken up by knowledge maintenance—educating the next generation of scientists—rather than by knowledge creation. Is there a way out of this?
Shouldering the Burden of Knowledge: Long-Run Cruxes
So the more phenomena we describe and explain with science, the more storage space our existing scientific knowledge will require. “Storage space” means room in the brains of human scientists, and the process of maintaining that stored knowledge involves repeatedly educating successive generations of scholars. This dynamic puts an intrinsic cap on the amount of knowledge which the scientific apparatus can maintain, and the closer we are to that cap, the less efficiently science will create new knowledge. The observation that science is getting harder can thus be at least partly explained by the burden of knowledge. The subjective experience that the frontiers of scientific inquiry seem so very far away to most people lends this explanation a rather visceral appeal.
But there are a few ways we can imagine lightening the load—that is, decreasing the portion of our scientific resources going towards knowledge maintenance. Perhaps we could lower the volume of knowledge by compressing it into more parsimonious theories. Surely knowledge handoff could be made more efficient: why do math and physics need to be taught in order of historical discovery? Could students specialize at a younger age? Maybe the structure and content of curricula could be refined to put more people at the frontiers of inquiry faster. Anyways, adding more scientists seems like it will always be a reliable way to increase our scientific capacity. And as Tabarrok points out, the burden of knowledge can often be offloaded to tools used as black boxes.
I’d like to raise two interrelated, very abstract subsidiary questions to how inevitable the burden of knowledge will turn out to be. They feel like cruxes in the sense that their resolution would say a lot about the viability of the proposals above, and about the direction of science in general.
Can we keep breaking knowledge into (proportionally, if not absolutely) smaller and smaller chunks? To what extent is scientific knowledge modularizable?
To what extent does scientific knowledge that has been put in cold storage—written in text, built into tools whose function nobody understands, internalized by AI—retain its use for future innovation? To what extent is scientific knowledge shelf-stable?
But even if affirmative answers to the questions above let us overcome the logistical constraints imposed by the burden of knowledge, we might start bumping into limits similar to the low-hanging fruit problem that I mentioned in an earlier section. Modularization, compartmentalization, and tooling might let us overcome the finite cognitive bandwidth of individuals. But there are other reasons it could get harder to expand an explanatory base which only gets wider.
If knowledge were infinitely modularizable, one could imagine continuing scientific progress indefinitely by piling on ever-more-specialized scientists. But if breaking new ground requires combining old ideas from diverse fields, the difficulty of innovation—or at least groundbreaking innovation—may grow with the degree of specialization. See this essay for some interesting discussion relevant to this point; there are a number of different ways one can take the observation (or assumption) that innovation is at least partly a combinatorial process. On the other hand, it’s possible that there are some systems which contain indivisible networks of interaction so complex that that their study cannot be fruitfully broken down into chunks small enough for any human scientist.
Delegating knowledge to tools might let us circumvent even limits of population and system complexity. To a great extent we already rely on doing this, of course, via written resources, search engines, and tools. But the more we rely on knowledge hosted outside of human brains, the less accessible it might be as a resource for future innovation. One can use a tool that they don’t understand. But it’s hard to improve a conceptual structure which you find largely inscrutable.
At this point, the conversation becomes rather too vague and speculative to feel particularly useful. Matt Clancy puts it well: “By definition, innovation is the creation of things that are presently unknown. How can we say anything useful about a future trajectory that will depend on things we do not presently know about? In fact, I think we can say very little about the long-run outlook of technological change, and even less about the exact form such change might take.” To some degree, we have no choice but to forge ahead and see what happens. But even if we ignore the practical issues, the burden of knowledge raises certain axiological questions. Does it still count as knowledge if it is distributed in tiny chunks across the brains of billions of people, or stored in boxes for nobody to see? Why do we value science in the first place?
Science versus Technology: is Knowledge Intrinsically Valuable?
The two analogies described earlier—accelerating a car versus accumulating simulations on a hard drive—correspond to two different ways of motivating the scientific project. On the one hand, science can be viewed as a means of producing technologies which enhance our capacities. This endeavor is well represented by the car analogy: trying to get the car to go faster corresponds to getting our society to serve our wants and needs better. If that means throwing out superfluous parts or turning components into inscrutable black boxes, so be it. It’s not about understanding the universe, it’s about controlling the phenomena which affect our quality of life. And in many ways, this is a useful way to look at science. It is certainly the perspective favored by economists. Science has made the twenty-first century healthier and more prosperous than any which came before it, and that’s a good thing.
But science, one might contend, is also concerned with a kind of understanding above and beyond mere instrumental supremacy. Explicit knowledge about the nature of reality could be seen as intrinsically valuable. Doesn’t knowing something about the structure of reality make life richer in some way? If it’s all about technological progress, why do we spend billions studying the origins of the universe and taking photographs of distant galaxies?
Of these two ways of looking at science—as oriented to technological progress versus explicitly understanding the universe and our place in it—the second pursuit appears to be more deeply afflicted by the burden of knowledge, since modularization and idea storage seem to cut against its very purpose. It forces us to choose which things are worth knowing about. But the first pursuit also requires us to prioritize for strategic reasons: which areas of study produce the most instrumentally useful knowledge?
The upshot of all this is that scientific prioritization grows more important every year, on both individual and collective levels. The burden of knowledge draws attention to the questions: in a world with limited cognitive resources, how do we choose what to study? What do we care about understanding, and why?
In Favor of Practical Problem-Solving: Why the Institutional View is Still the Best One
Recall the three explanations for science friction which I laid out in an earlier section. The purpose of this piece has been to argue that the problem of the burden of knowledge cannot be so easily dismissed. I don’t think the low-hanging fruit problem can be either. It’s most likely that the scientific friction we observe results from a combination of all of the suggested causes: institutional inefficiency, the burden of knowledge, and the low-hanging fruit problem. But one of these possible explanations is not like the others: institutional problems are not caused by the nature of knowledge itself. It is implied, and seems perfectly likely, that there are alternative institutional structures which would do the job better, and which we might be able to attain in real life. Therefore, having just said everything I said, I do think it is these institutional interventions that are the most worthy of study. With any luck, we’ll be able to keep our science cranking along for a long time to come just by improving the way we conduct it.
It seems hard to avoid scientific stagnation due to the burden of knowledge in the long run
Link post
Summary
It’s well-known that science appears to be getting substantially more expensive on the margin. I’ll call this science friction.
The studies which reach this conclusion operationalize “scientific progress” in two broad ways:
Scientific progress = total factor productivity.
Changes in scientific progress can be detected using science-internal metrics of change (e.g. networks of citation).
Explanations of science friction fall into three categories:
Institutional explanations.
The low-hanging fruit has already been plucked.
There is a burden of knowledge which grows as science advances.
Science is cumulative in explanatory power, so some burden of knowledge is inevitable as long as explanatory power is not orthogonal to computational complexity.
That being the case, shouldering the burden of knowledge will cost more research effort over time. In the long run, unless the total available research capacity grows at a faster rate, this will consume asymptotically all research effort. The total available research capacity would seem to be able to continue growing indefinitely only if:
Scientific knowledge is infinitely modularizable (there’s no limit to specialization as a proportion of total knowledge) and the population of available researchers keeps growing, or
Scientific knowledge can be offloaded to non-human entities, e.g. books, databases, and AI, without losing its utility for future innovation.
The burden of knowledge is a bigger problem if you think that science is intrinsically valuable, rather than just a means to technological capacity enhancement.
All of this being said, the institutional problems of science deserve more attention than the burden of knowledge because they’re more tractable.
Epistemic Status
This is an introductory and speculative post which I wrote for my blog. It’s less strictly organized and more narrative-y than something I’d have written specifically for the EA Forum. It’s also the result of a shallow investigation, and not on a topic that I’m anywhere close to an expert on. Nonetheless I think it contains a few vague ideas which those of you who are interested in metascience and/or longtermism might find interesting. I think it’s especially relevant to conversations about stagnation.
The first two sections after the intro (“What is Scientific Progress?” and “Three hypotheses about science friction”) can be skipped by people who know the first few things about this topic.
Introduction
Science seems to be getting harder. The evidence supporting this claim has been summarized elsewhere, so for the sake of argument this post takes it for granted. On average, every unit of “scientific progress” costs more researcher-hours than the one before it. The marginal cost of scientific progress is increasing. Call it science friction.
One explanation of this phenomenon posits a “burden of knowledge” which causes educational costs to grow as science advances. Recently, I read two thought-provoking blog posts by Maxwell Tabarrok which took issue with this explanation. I began drafting comments containing a bit of pushback on some of the arguments Tabarrok raised, but the subject came to feel worthy of a full-length post. In particular, I’d like to disentangle the intuition behind the burden of knowledge, offer a few key conceptual obstacles to proposed solutions, and argue that the magnitude of the problem depends on what you think the purpose of science is.
But first, 150 seconds of context.
What is Scientific Progress?
Scientific progress is a slippery concept, so I’m not going to offer a definition. To ground the conversation, however, here are two general ways it gets operationalized in metascience research:
To an economist, scientific progress is anything that allows our economy to do more with the same quantity of resources. “Resources” are all the tangible inputs to economic growth: labor, land, materials, tools, and the rest. Scientific progress is then anything which increases total factor productivity (TFP), the intangible component of economic growth models. In the coarsest possible terms, GDP = F(TFP, (labor input), (capital input)), an an increase in TFP counts as scientific progress. The famous 2020 paper “Are Ideas Getting Harder to Find?” compares TFP growth to scientific inputs: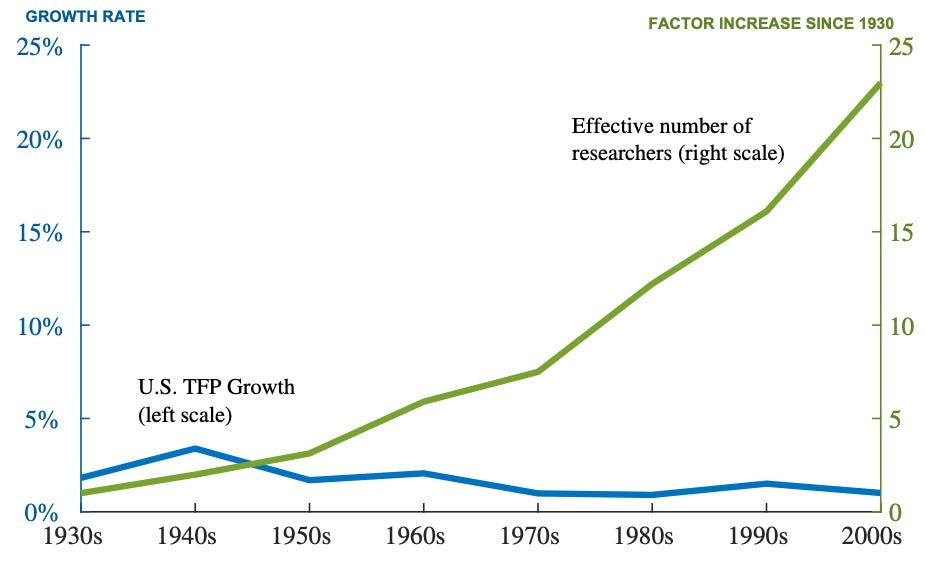
We can also try to measure scientific progress by looking at data internal to science: scientific publications themselves, for instance, and the way that they cite each other. The 2023 article “Papers and patents are becoming less disruptive over time,” published in Nature, introduces a metric of the impact that papers and patents have on networks of citation, with the result that “papers and patents are increasingly less likely to break with the past in ways that push science and technology in new directions.” This blog post from metascience researcher Matt Clancy presents a grab-bag of such science-internal metrics, all of which show increasing scientific friction (my favorite methods use linguistic cues from article titles and author-supplied keywords).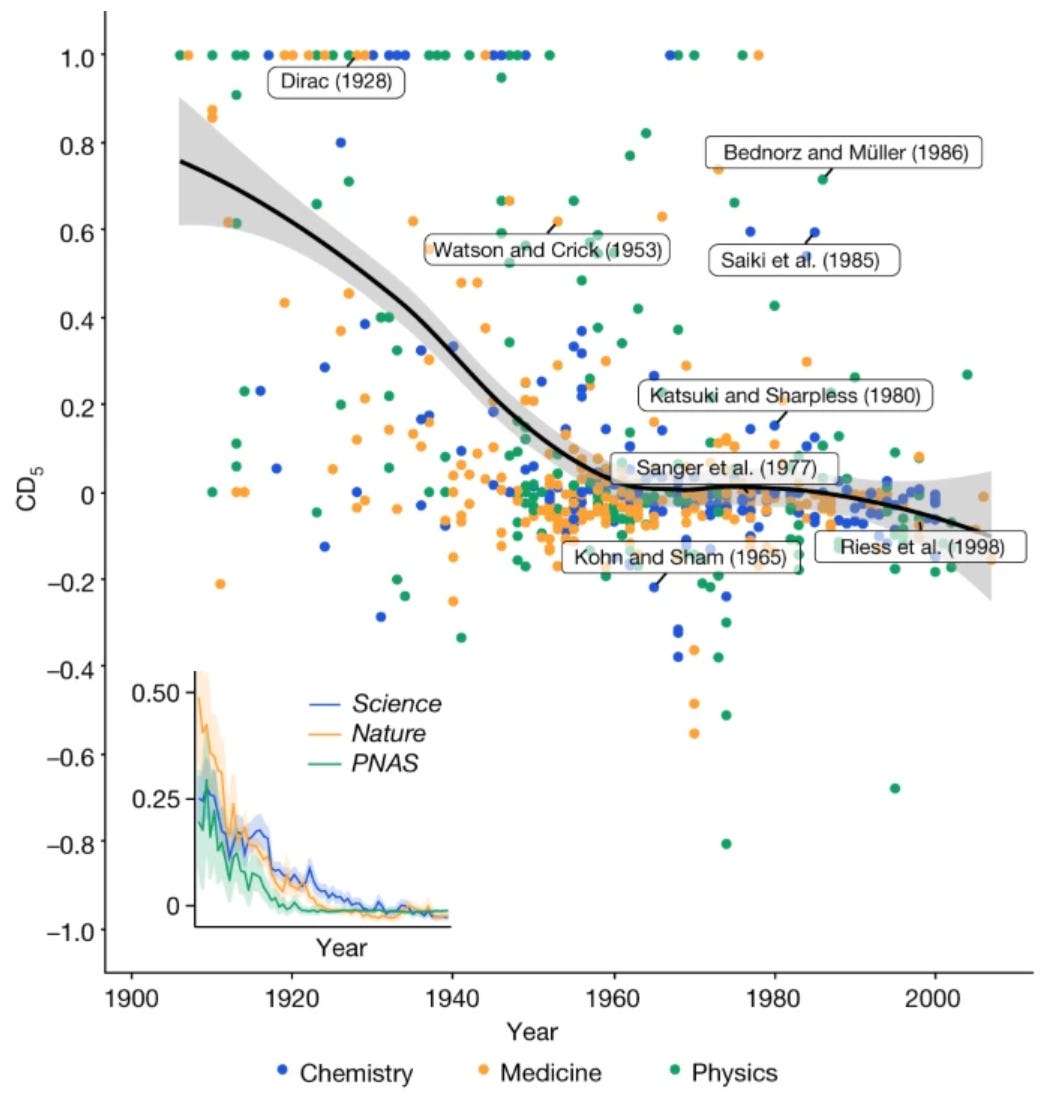
Three hypotheses about science friction
The proposed explanations of science friction seem to fall into three main categories.
Institutional explanations: something is wrong with the way science is conducted. Researchers spend too much time writing grants. Disciplinary silos discourage interdisciplinary work. Questionable research practices (read: fraud) are incentivized, replication is discouraged, and the intellectual environment stifles creativity. Pressure to publish discourages long, risky, high-payoff projects. Researchers are just getting too old. As one of the blog posts I mentioned in the introduction points out, “Risk averse funders and reviewers… reward incremental, labor intensive research. A business model based on exclusivity that requires more and more hurdles as the initial pool of applicants grows.” I’ll add that cultural homogenization in and out of science could reduce the number of independent chances that humanity has to innovate. There are a lot of ways scientific institutions seem sub-optimal.
The low-hanging fruit has already been plucked: I won’t spend a lot of time on this explanation, but it’s popular and intuitively appealing, if rather hard to pick apart. We’ve already discovered the easiest stuff to discover, so we should expect finding out new, important things to be increasingly difficult.
The burden of knowledge: this idea is related to, but distinct from, #2. Basically: the more we learn about science, the more effort it takes to get aspiring researchers up to speed, leaving fewer resources available to push the boundaries of knowledge forward. This could manifest in an older average age of discovery, more expensive or time-consuming education, or (as in the paper which popularized the burden of knowledge idea) increasing specialization and larger teams. In some sense, future ideas may be no more intrinsically “complicated” or “challenging” than past ones, once you’ve got the prerequisite knowledge. Let’s say many of them are just a matter of putting a few previous ideas together in a process of combinatorial innovation. But even if that were the case, understanding previous research to the point where one is capable of recombining it into something new might take longer and longer.
Knowledge doesn’t grow monotonically, but it is cumulative
Tabarrok compares studying science friction to studying a car:
This is a good analogy. It’s true that we really don’t have a good handle on the “underlying kinetics” of scientific progress. But it’s not the case that we don’t know anything about them. I’d like to argue that one important feature of science—which Tabarrok seems to deny and which is the key intuition behind the burden of knowledge idea—is that it is an essentially cumulative enterprise. Science seeks to accumulate good explanations of phenomena which we observe in the world, up to some criteria of “goodness” involving things like explanatory accuracy, predictive power, and model parsimony. Science is about building knowledge, and is therefore cumulative almost by definition.
Tabarrok acknowledges this: “It’s hard to imagine a model of scientific progress without accumulating knowledge.” But later, under the header “Knowledge is Often Not Cumulative,” Tabarrok offers an example which seems to contradict this property. By putting the sun (rather than the earth) at the center of our astronomical neighborhood, Copernicus dramatically simplified orbital mechanics, thereby apparently making knowledge simpler, more elegant, and altogether rather smaller. Many scientific advances look something like this, where new models seem to distill those that they are replacing in a simpler, more unified way.
These instances do reduce the amount of breath we need to expend to explain all of the details of our scientific models. But it is explanatory power, not model complexity, that we’re trying to accumulate; individual models are merely a means to that end. After Copernicus, science still explained just as much of the world as before, and it did so more accurately. Scientific knowledge did continue to accumulate, it just did so along a dimension orthogonal to the complexity of that particular model. Ultimately, the goal is to explain ever more of our universe’s workings ever better. “More” and “better” are the operative words there. That being the case, it seems very hard to envisage an underlying scientific dynamic in which the overall trend is not for knowledge to get gradually larger over time.
It’s a bit like we’re trying to fill a computer hard drive with simulations which can be used to approximate all of the empirical phenomena that we’re interested in. Given some practical setting, then, we can load the relevant program and answer questions about it. The scientific endeavor gradually loads more files on our hard drive, while breakthroughs like Copernicus’ occasionally come along and compress these files in a more efficient way. The bottom line, though, is that if we want to explain more stuff, we will eventually need more storage space for all of our explanations.
(Image creds to DALL-E 2)
Note that this account relies on “explanatory power” being at least somewhat dependent on computational complexity. This claim, in turn, relies on the assumption that the objects of scientific study contain a certain level of intrinsic complexity, or computational irreducibility. One might hope that a few very parsimonious descriptions might do the trick: that we might be able to load just one or two programs on our hard drive and use them to explain everything we care about. In a very specific way, this might be right. It’s kind of what physics is trying to do by reducing all of nature to just a few fundamental components. In a rather truer way, however, there appears to be a certain amount of computational irreducibility inherent in many of the phenomena we care about. Even if all processes are fundamentally physical, in practice we need to break them into groups and delegate them to sciences other than physics.
(Stephen Wolfram has noted that some very simple cellular automata display computational irreducibility: their evolution cannot be precisely predicted in a faster way than by running each step of their computation.)
But if explaining more ultimately means carrying a heavier burden of pre-existing knowledge, then absent countervailing forces, more and more of our scientific resources will have to go towards education. Pessimistically, this view seems to entail that asymptotically all of scientists’ efforts will be eventually be taken up by knowledge maintenance—educating the next generation of scientists—rather than by knowledge creation. Is there a way out of this?
Shouldering the Burden of Knowledge: Long-Run Cruxes
So the more phenomena we describe and explain with science, the more storage space our existing scientific knowledge will require. “Storage space” means room in the brains of human scientists, and the process of maintaining that stored knowledge involves repeatedly educating successive generations of scholars. This dynamic puts an intrinsic cap on the amount of knowledge which the scientific apparatus can maintain, and the closer we are to that cap, the less efficiently science will create new knowledge. The observation that science is getting harder can thus be at least partly explained by the burden of knowledge. The subjective experience that the frontiers of scientific inquiry seem so very far away to most people lends this explanation a rather visceral appeal.
But there are a few ways we can imagine lightening the load—that is, decreasing the portion of our scientific resources going towards knowledge maintenance. Perhaps we could lower the volume of knowledge by compressing it into more parsimonious theories. Surely knowledge handoff could be made more efficient: why do math and physics need to be taught in order of historical discovery? Could students specialize at a younger age? Maybe the structure and content of curricula could be refined to put more people at the frontiers of inquiry faster. Anyways, adding more scientists seems like it will always be a reliable way to increase our scientific capacity. And as Tabarrok points out, the burden of knowledge can often be offloaded to tools used as black boxes.
I’d like to raise two interrelated, very abstract subsidiary questions to how inevitable the burden of knowledge will turn out to be. They feel like cruxes in the sense that their resolution would say a lot about the viability of the proposals above, and about the direction of science in general.
Can we keep breaking knowledge into (proportionally, if not absolutely) smaller and smaller chunks? To what extent is scientific knowledge modularizable?
To what extent does scientific knowledge that has been put in cold storage—written in text, built into tools whose function nobody understands, internalized by AI—retain its use for future innovation? To what extent is scientific knowledge shelf-stable?
But even if affirmative answers to the questions above let us overcome the logistical constraints imposed by the burden of knowledge, we might start bumping into limits similar to the low-hanging fruit problem that I mentioned in an earlier section. Modularization, compartmentalization, and tooling might let us overcome the finite cognitive bandwidth of individuals. But there are other reasons it could get harder to expand an explanatory base which only gets wider.
If knowledge were infinitely modularizable, one could imagine continuing scientific progress indefinitely by piling on ever-more-specialized scientists. But if breaking new ground requires combining old ideas from diverse fields, the difficulty of innovation—or at least groundbreaking innovation—may grow with the degree of specialization. See this essay for some interesting discussion relevant to this point; there are a number of different ways one can take the observation (or assumption) that innovation is at least partly a combinatorial process. On the other hand, it’s possible that there are some systems which contain indivisible networks of interaction so complex that that their study cannot be fruitfully broken down into chunks small enough for any human scientist.
Delegating knowledge to tools might let us circumvent even limits of population and system complexity. To a great extent we already rely on doing this, of course, via written resources, search engines, and tools. But the more we rely on knowledge hosted outside of human brains, the less accessible it might be as a resource for future innovation. One can use a tool that they don’t understand. But it’s hard to improve a conceptual structure which you find largely inscrutable.
At this point, the conversation becomes rather too vague and speculative to feel particularly useful. Matt Clancy puts it well: “By definition, innovation is the creation of things that are presently unknown. How can we say anything useful about a future trajectory that will depend on things we do not presently know about? In fact, I think we can say very little about the long-run outlook of technological change, and even less about the exact form such change might take.” To some degree, we have no choice but to forge ahead and see what happens. But even if we ignore the practical issues, the burden of knowledge raises certain axiological questions. Does it still count as knowledge if it is distributed in tiny chunks across the brains of billions of people, or stored in boxes for nobody to see? Why do we value science in the first place?
Science versus Technology: is Knowledge Intrinsically Valuable?
The two analogies described earlier—accelerating a car versus accumulating simulations on a hard drive—correspond to two different ways of motivating the scientific project. On the one hand, science can be viewed as a means of producing technologies which enhance our capacities. This endeavor is well represented by the car analogy: trying to get the car to go faster corresponds to getting our society to serve our wants and needs better. If that means throwing out superfluous parts or turning components into inscrutable black boxes, so be it. It’s not about understanding the universe, it’s about controlling the phenomena which affect our quality of life. And in many ways, this is a useful way to look at science. It is certainly the perspective favored by economists. Science has made the twenty-first century healthier and more prosperous than any which came before it, and that’s a good thing.
(From “The short history of global living conditions and why it matters that we know it,” Our World in Data, December 2016)
But science, one might contend, is also concerned with a kind of understanding above and beyond mere instrumental supremacy. Explicit knowledge about the nature of reality could be seen as intrinsically valuable. Doesn’t knowing something about the structure of reality make life richer in some way? If it’s all about technological progress, why do we spend billions studying the origins of the universe and taking photographs of distant galaxies?
Of these two ways of looking at science—as oriented to technological progress versus explicitly understanding the universe and our place in it—the second pursuit appears to be more deeply afflicted by the burden of knowledge, since modularization and idea storage seem to cut against its very purpose. It forces us to choose which things are worth knowing about. But the first pursuit also requires us to prioritize for strategic reasons: which areas of study produce the most instrumentally useful knowledge?
The upshot of all this is that scientific prioritization grows more important every year, on both individual and collective levels. The burden of knowledge draws attention to the questions: in a world with limited cognitive resources, how do we choose what to study? What do we care about understanding, and why?
In Favor of Practical Problem-Solving: Why the Institutional View is Still the Best One
Recall the three explanations for science friction which I laid out in an earlier section. The purpose of this piece has been to argue that the problem of the burden of knowledge cannot be so easily dismissed. I don’t think the low-hanging fruit problem can be either. It’s most likely that the scientific friction we observe results from a combination of all of the suggested causes: institutional inefficiency, the burden of knowledge, and the low-hanging fruit problem. But one of these possible explanations is not like the others: institutional problems are not caused by the nature of knowledge itself. It is implied, and seems perfectly likely, that there are alternative institutional structures which would do the job better, and which we might be able to attain in real life. Therefore, having just said everything I said, I do think it is these institutional interventions that are the most worthy of study. With any luck, we’ll be able to keep our science cranking along for a long time to come just by improving the way we conduct it.