Are New Ideas in AI Getting Harder to Find?
GitHub for RCode is here; R Markdown (which includes plots/tables) is here.
Summary
This post looks at how the ‘burden of knowledge’ (i.e. how cumulative knowledge is required to make progress) has changed for the field of AI, from 1983 to 2023.
Using the Semantic Scholar API, I look at AI-related journal articles and conferences papers from 12 long standing AI journals papers as well as prominent papers on ArXiv (>15 citations)
The average number of citations and number of co-authors per year have increased over time, with a higher slope for ArXiv papers.
These trends are consistent with findings for maths and economics, and suggest that the burden of knowledge is increasing.
The Semantic Scholar API is user-friendly, there are options to extend this analysis within AI and into other disciplines.
If this trend continues, human-driven progress might be increasingly resource-intensive; it may also indicate that we are understating the potential transformative effects of AGI.
Introduction
I became interested in this area reading a post on Matt Clancy’s blog. He starts his post by writing:
Innovation appears to be getting harder. At least, that’s the conclusion of Bloom, Jones, Van Reenen, and Webb (2020). Across a host of measures, getting one “unit” of innovation seems to take more and more R&D resource
He goes on to say: one explanation for why innovation is getting harder is because the ‘burden of knowledge’ is increasing. As more problems have been solved in the world, the cumulative amount of knowledge required to solve the next problem increases. So, for any would-be-Newton or Einstein, the amount of training required to push back the frontier is increasing.
There is a range of circumstantial evidence for the increasing burden of knowledge:
People start to innovate later in life: individuals increasingly publish their first solo academic paper, win a Nobel prize, or make a great invention when they are older.
Increasing specialization within a field: it is becoming rarer for solo inventors to patent in multiple fields or for academics to publish across various disciplines.
Burden of Knowledge is Split Across heads: the average team size for a patent or a paper is increasing.
Increasing depth of knowledge: the number of citations per academic paper is increasing.
Matt Clancy’s review of the literature suggests that the evidence for 1-4 is fairly strong (although the evidence for 1 is more mixed for patent data). This fits with a general model of innovation, in which ideas are getting harder to find/productivity per researcher is falling.
In this blog post, I apply some of these methods to the field of Artificial Intelligence. I look at the average team size (3) and number of citations (4) for academic papers from 1983-2023, using data collected from the Semantic Scholar API. I find that the average team size and number of citations increased in the time period, both for publications in selected AI journals. This is consistent with findings for mathematics and economics (from Brendel and Schweitzer (2019, 2020), These upward trends were even greater for prominent AI publications on ArXiv in the last decade or so.
Feel free to skip the Findings section, if you’re less interested in the methods.
Methods
Initial Search
I used Semantic Scholar’s API to bulk search for Journal Articles or Conference Papers from 1980 to 2023, which Semantic Scholar’s algorithm classified as belonging to AI-related fields (Computer Science, Maths, AI, or ML). I used a very broad query to cover many fields within AI. This gave around 328,000 results.
Filtering for Journals
The aim here is to compare the ‘burden of knowledge’ within a particular field. However, there might be differences in standards across different publication locations: e.g. one journal might be particularly fastidious about referencing, for example. So, the idea is to look at papers from particular journals, whose standards presumably don’t change much over time.
These journals should be longstanding. I chose journals which had a high number (generally above 50) publications before the year 2000. Many AI journals have been founded recently, or had few publications before 2,000. I excluded several AI journals which scored highly on Google Scholar’s metrics for this reason.
I also excluded non-technical AI journals (e.g. AI & Society or journals related to AI-communication.)
Some long-standing journals had a specially low number of old publications: e.g. NIPs, founded in 1987, only had 48 publications. So, many papers were either (1) missing from the original dataset or; (2) excluded by the classifier. Annoyingly, the Semantic Scholar API doesn’t allow you to search for specific journals. However, I don’t think either (1) or (2) should lead to a biased sample of publications from these AI journals.
This final list (give in the appendix) comprised 12 journals, and included well-known venues like AAAI Conference and others.
Figure 1: Data Used
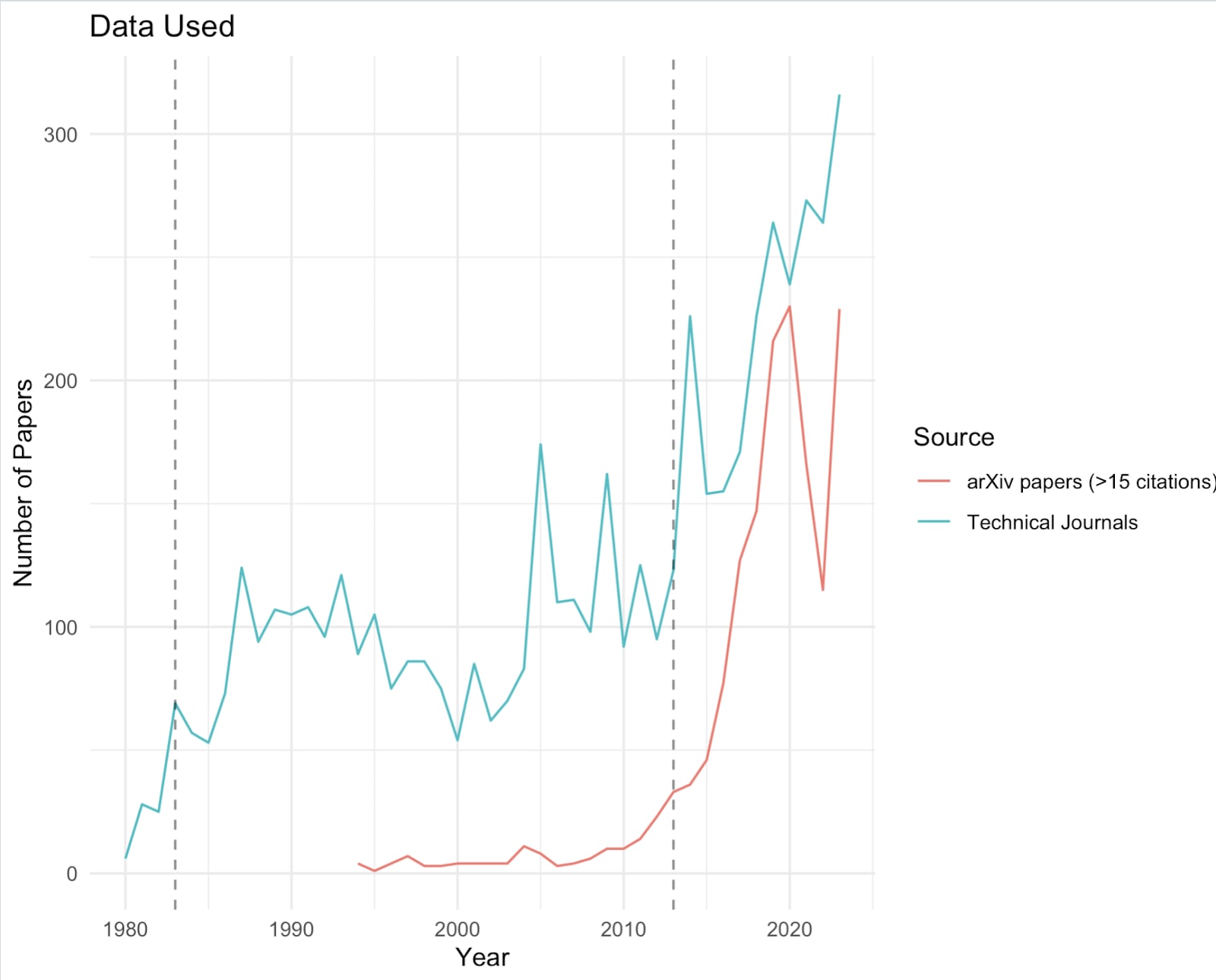
The number of journal publications before 1980 and ArXiv papers before 2012 was small (less than 30 papers found annually), so I excluded these years for each respective category.
This gave a total of 5186 technical papers, and 1422 prominent ArXiv papers.
Findings
Brendel and Schweitzer (2019, 2020) found that average team size were increasing for top mathematics and economics articles respectively.
I found a similar shape for AI papers. (Slopes were significant for both Journals and arXiv papers, but confidence intervals are not given here.) The slope for arXiv papers was high, relative to papers from academic journals.
All this is also true for the average number of references.
Brendel & Schweitzer (2019) – Top Mathematics Articles
One difference here is that Brendel and Schweitzer looked only at first-time publications – presumably trying to control for changes as academics get more senior. I don’t do this here, and this would be a useful extension.
Discussion
I believe these findings provide good evidence that the burden of knowledge is increasing for the field of AI, both for papers in academic journals and ArXiv. New publications within AI require more background knowledge, leading to higher average team sizes and citation counts.
How else might we explain these findings?
Another explanation might be that academic standards within academic journals or on ArXiv are becoming more rigorous, leading academics to cite papers more. Alternatively, AI academics might be becoming more sociable – i.e. citing their friends’ papers more, and collaborating more on papers. I don’t find either of the explanations particularly convincing.
A more serious objection is that these trends could be that recent publications reflect a greater influence of more established academics, who tend to collaborate and reference more extensively. The evidence here is weaker than Brendel and Schweitzer (2019, 2020) who look at mathematics/economics. These papers filter for first time publications, look at levels of specialization, and the ages of authors when they first publish. There is much more work to extend this analysis. (See below).
Nonetheless, I would suspect (80%?) that even after filtering for first-time AI publications, the same trends observed here would be found. I wouldn’t suspect that more senior academics reference or collaborate any more than younger academics. The opposite might even be true.
Thus, I think this provides decent evidence that the burden of knowledge is increasing for AI. This finding is relevant for forecasting AI progress and/or its economic effects.
First, trivially, if this trend continues – i.e. the burden of knowledge increases – we might expect innovation in AI to be increasingly harder to find. This is not to say that aggregate productivity in AI will fall, as increasing burden of knowledge could be offset by the increasing amount of resources thrown at the field.
Secondly, this trend might mean that we are understating the potential effects of AGI. (Thank you to Tom Houlden for this idea. I may not have parsed it right.) Some models (e.g. Davidson?) assume that AI could substitute for a human AI researcher. The increasing burden of knowledge would presumably lead to decreased research productivity for a human. However, this constraint would not affect an AGI which could instantaneously read all relevant publications.
There might be other implications to draw here… I’d be interested to hear them.
Further Work
Extending the Method to Other Fields
The Semantic Scholar API is pretty easy to use. There are a lot of helpful resources online and even a Slack Channel. You can request a passkey very easily on the website – it took around an hour for mine to be approved. A similar method could be applied for Synthetic Biology or Nanotechnology (assuming there are good, longstanding journals).
Extending this method for AI
I only looked at team size and number of references.
Brendel and Schweitzer (2019, 2020) also look at the age of a researcher – when they first publish in a journal. They then run a regression to see how team size (alongside other controls, including sex) affect age of first publication. I didn’t do this here, as it would require manually finding dates of birth for different authors.
They also filter for first time publications. This could be a good move, but would also reduce the sample size and increase noise.
Additionally, they look at the fields of citations – i.e. are economics papers referencing different fields, such as mathematics or biology? A similar method could be done through Semantic Scholar, although this might be quite computationally difficult. (You might need to download the entire dataset, I believe.)
Alternatively, a similar method could be used for AI patent data, although this might be harder to access.
Appendix
List of AI Journals
International Joint Conference on Artificial Intelligence
Robotica (Cambridge. Print)
International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems
IEEE Transactions on Systems, Man and Cybernetics
AAAI Conference on Artificial Intelligence
International Conference on Scientific Computing
Applied Artificial Intelligence
Computer
Artificial Intelligence Review
Artificial Intelligence
Annals of Mathematics and Artificial Intelligence
International Journal of Intelligent Systems
FWIW, I find this somewhat convincing. I think the collaborating on papers part seems like it could be downstream of the expectations of # of paper produced being higher. My sense is that grad students are expected to write more papers now than they used to. One way to accomplish this is to collaborate more.
I expect if you compared data on the total number of researchers in the AI field and the number of papers, you would see the second rising a little faster than the first (I think I’ve seen this trend, but don’t have the numbers in front of me). If these were rising at the same rate, I think it would basically indicate no change in the difficulty of ideas, because research hours would be scaling with # papers. Again, I expect the trend is actually papers rising faster than people, which would make it seem like ideas are getting easier to find.
I think other explanations, like the norms and culture around research output expectation, collaboration, how many references you have to have, are more to blame.
Overall I don’t find the methodology presented here, of just looking at number of authors and number of references, to be particularly useful for figuring out if ideas are getting harder to find. It’s definitely some evidence, but I think there’s quite a few plausible explanations.
Hi Aaron,
I’m sorry it’s taken me a little while to get back to you.
In hindsight, the way I worded this was overly strong. Cultural explanations are possible, yes.
I guess I see this evidence as a weak update on a fairly strong prior that the burden of knowledge (BOK) is increasing – given the range of other variables (e.g., age of innovation, levels of specialisation), and similar trends within patent data. For example, you couldn’t attribute increasing collaboration on patents to norms within academia.
I’d be interested to compare # researchers with # papers. The ratio of these two growth rates is key, for the returns to research parameter from Bloom et al. Do send me this, if you have remembered in the intervening time.
Charlie
I don’t have the time right now to find exactly which comparison I am thinking of, but I believe my thought process was basically “the rate of new people getting AI PhDs is relatively slow”; this is of course only one measure for the number of researchers. Maybe I used data similar to that here: https://www.lesswrong.com/s/FaEBwhhe3otzYKGQt/p/AtfQFj8umeyBBkkxa