Cross-posted from LessWrong after a friend finally convinced me. Lighter reading here.
Update: appreciating Scott Alexander’s humble descriptions in his recent Criticism of Criticism of Criticism post. A clarification I need to make is that the blindspot-brightspot distinctions below are not about prescribing ’EAs’ to be eg. less individualistic (although there is an implicit preference, with non-elaborated-on reasoning, which Scott also seems to have in the other direction). The distinctions are attempts at categorising where (covering aspects of the environment) people in involved in our broader community incline to focus on more (‘brightspots’) relative to other communities, as well as what corresponding representational assumptions we are making in our mental models, descriptions, and explanations. The distinctions also form a basis for prescribing the community to not just make hand-wavy gestures of ‘we should be open to criticism’, but to actually zone in on different aspects other communities notice and could complement our sensemaking in, if we manage to build epistemic bridges to their perspectives. Ie. listen in a way where we do not keep misinterpreting what they are saying within our default frames of thinking (criticism is not useful if we keep talking past each other). I highlighted where we are falling short and other communities could contribute value.
Last month, Julia Galef interviewed Vitalik Buterin. Their responses to Glen Weyl’s critiques of the EA community struck me as missing perspectives he had tried to raise.
So I emailed Julia to share my thoughts. Cleaned-up text:
Personally, I thought Vitalik’s and your commentary on Glen Weyl’s characterisation of the EA and rationality community missed something important.
Glen spent a lot of time interacting with people from the black community and other cultural niches and asking for their perspectives. He said that he learned more from that than from the theoretical work he did before.
To me, Glen’s criticism came across as unnuanced (eg. EAs also donate to GiveDirectly, and it’s not like we force people to take what we give them). I also resonate with that critiques of rationality and EA often seem unfair and devoid of reason. They lack specific examples and arguments relating to what the community actually does, and come across as a priori judgements of our community being cold, reductionist and weird. It’s also frustrating that such critiques can constrain EA efforts to improve the lives of others.
But Glen’s criticism hit an important point: our community wields usefully biased styles of thinking to comprehend the world and impact the lives of beneficiaries far removed from us. But we overlook the perspectives held by persons we affect, perspectives which are adapted to the contexts they live in (with ‘adapted’ I roughly mean that their perspectives are useful for navigating their surrounding environment in ways that allow them to reach opportunities and avoid hazards).
It’s hard though to discern these perspectives without hanging out and talking. Most rationalists, me included, have spent little time travelling overseas and immersing themselves in local cultures different from theirs. It’s also hard for Glen (or Tyler) to convey perspectives unfamiliar to listeners in x minutes.
If it’s helpful, I could try and share a summary with you of views and styles of thinking that the rationality community is not much in touch with. I read about 150 psychology papers in my spare time to try and form a better understanding of our blindspots (and complementary ‘brightspots’).
Julia graciously replied that she was interested in a summary of what I think EAs might be missing, or how in particular our views on philanthropy might be biased due to lack of exposure to other cultures/communities.
I emailed her a summary of my upcoming sequence (edit: instead writing up new AGI-misalignment arguments that very much fall in attentional blindspot 1 to 6) – about a tool I’m developing to map group blindspots. It was tough to condense 75 pages of technical explanation clearly into 7 pages, so bear with me (comment)! I refined the text further below:
Here are brightspots (vs. blindspots) that EAs and rationalists might hold in common, ie. areas we notice (vs. miss) that map to relevant aspects of reality.
Common brightspots: We often focus on analysing how an abstract thing will function.
This focus is narrow (compared to the portion of hypothetical space that humans are able to perceive and meta-learn from). This is because we are mapping the territory at the intersection of several views.
I think we especially focus on viewing...
future(vs. past),
far(vs. near vs. centrally present),
precisely (vs. imprecisely)sorted
structures (vs. processes) of
independent individuals (vs. the interdependent collective) that are
externally(vs. internally) present.
A group lights up a brightspot, near vs. far. (kudos to my mum for this sketch)
Different-minded groups can illuminate the aspects we miss in viewing our brightspots:
1. We reference future possibilities
We seem to neglect past case studies or historical accounts somewhat in predicting the effects our philanthropic actions have on beneficiaries. Some conservative cultures attach more value to passing on and studying past accounts and practices. Our community has a progressive leaning. We seem more open to letting go of past learnings and to reimagine the future. As a result, we also reinvent the wheel more (comment).
Complicating factors: – Over the years, EA orgs fixated more on upholding established paradigms. Community building practices are have especially become more conservative. Unconventional entrepreneurs receive less support. – I’m confusing different meanings of conservatism. Is this about being closed to unfamiliar people or things, a need to maintain purity and order, deferring to authority or tradition, preventing the loss of what you acquired in the past, updating less on novel inferences, referencing past experiences in planning..?
I. Far across more far-fetched scenarios, sequenced over time. eg. existential risk ends society’s long-term trajectory (vs. current civic issue) II. Far across places stitched into space. eg. global poverty (vs. local homelessness) III. Separated from the bounded entities that neighbour us: inanimate objects, goal-directed beings, social partners. eg. pandemic containment (vs. on-the-ground fieldwork) IV. Decoupled from the context of individual identities we sort entities into: things, agents, persons. eg. LW on game-theoretic agents (vs. activists on rescuing a caged animal)
Since we aim to impact the lives of persons far removed from us, we get loose or no feedback on how our actions affected our supposed beneficiaries. Instead, we rely on feedback from our social circle to correct our beliefs. We talk with trusted collaborators who understand what we aim to do. But people close to us share similar backgrounds and use similar mental styles to map and navigate their environment.
Worryingly, contexts to which EAs were exposed in the past (W.E.I.R.D. academia, coding, engineering, etc), and later generalised arguments from, are very dissimilar to the contexts in which their supposed beneficiaries reside (villages in low-income countries, non-human animals in factory farms, cultural and ethnic groups who will be affected by technology developments).
Many of us seem motivated to focus and act on beliefs for doing good by a Calvinistic sense of responsibility that was impressed on us through social interactions since our childhood. We later generalised it to other hypothetical humans, out of a need to have a coherent ontology, as well as to assess value and pursue our derived goals consistently. Such underlying motivations are different from actually caring, and therefore drive a subtle wedge between the information we seek and act on, and what’s actually true, relevant, and helpful for the persons we claim to be trying to improve the lives of.
Going by projects I’ve coordinated, EAs often push for removing paper conflicts of interest over attaining actual skin in the game (comment).
3. We sort entities precisely into identities
When rationalists detachedly and coolly model the external world (vs. say nature-loving hippies who feel warm and close to their surroundings), they are guided by an aesthetic preference, is my sense:
We distill individual identities into abstract types that are elegant and ordered, based on primary features held in common (your interview on beauty in physics highlighted these aesthetics). Distillation allows us to block out context-specific features that appear messy and noisy.
Perhaps, we perceive contexts as more messy because we sort more precisely. Rationalists have, on average, more pronounced autistic traits. People diagnosed with autism tend to precisely sort entities they notice around them within a narrower confidence band of identity. They need tighter coherence amongst instances to feel certain about them being the same. So their threshold for perceiving ambiguity is lower: a smaller deviation in an entity’s features (superficial or essentialised) will trigger ambiguity as to which identity that entity belongs to.
Upon entering a new context, they fixate on sorting out all these special instances. They get overwhelmed, missing the proverbial forest for the trees. But if they’re able to select primary features individuals hold in common, they can extract a signal from the noise. By distilling individuals as general elements of an ordered system, they can draw neat lines of inference between them.
When we describe that representation of the world to a non-STEM group, it may come across as clinical, segregated, barren, and impoverished of meaning (look into how this post or Brave New World is worded). They struggle with ambiguity of a different kind – about which real-life concrete features embody such an abstract concept (what the hell does a ‘game-theoretic agent’ mean?).
Decoupling conflicts with their motivation to read into concrete nuances. They want to get close to, and be part of, a context that is rich, alive and interwoven. Glen’s personal quote: ❝I work to imagine, build and communicate a pluralistic future for social technology truer to the richness of our diverselysharedlives.
EAs and rationalists tend to be context-blind. We are more likely to miss subtle social cues. We are also more naively confident about our models fitting uniformly across various contexts (vs. say the peasants Luria interviewed who were hesitant to speculate about places they hadn’t seen before).
One pattern: early EA thinkers proposing explicit arguments that were elegant and ordered. Their analysis of causes and interventions was idealised – only refined later by new entrants who considered concrete applications.
In hindsight, judgements read as simplistic and naive in similar repeating ways (relying on one metric, study, or paradigm and failing to factor in mean reversion or model error there; fixating on the individual and ignoring societal interactions; assuming validity across contexts):
Eliezer Yudkowsky’s portrayal of a single self-recursively improving AGI (later overturned disputed by some applied ML researchers)
Will MacAskill’s claim that you can do 100x more good by giving to low-income countries
Toby Ord’s analysis of DCP2: ‘the best of these interventions is estimated to be 1,400 times as cost-effectiveness as the least good’
ACE researchers’ estimate of 1.4 animals saved per vegan leaflet
CEA staff recommending community building models derived from Oxford settings to all local organisers (fortunately opened up to criticism and adapted)
Current EA arguments still tend to build on mutually exclusive categorisations (unlike this email :), generalise across large physical spaces and timespans (comment), and assume underlying structures of causation that are static. Authors figure out general scenarios and assess the relative likelihood of each, yet often don’t disentangle the concrete meanings and implications of their statements nor scope out the external validity of the models they use in their writing (granted, the latter are much harder to convey). Posts usually don’t cover variations across concrete contexts, the relations and overlap between various plausible perspectives, or the changes in underlying dynamics much.
RadicalxChange, on the other hand, emphasises combining relevant perspectives in their modelling, and co-creating solutions with stakeholders who are working from different contexts. I could make a case say for GiveWell doing the former (eg. cluster thinking), but not much of the latter.
4. Our views are built out of structures
We (more EAs, see comment)perceive the world as consisting of locatable parts
A. We represent + recognise an observation to be a fixed cluster (a structure). eg. an observation’s recurrence, a place, a body, a stable identity
B. We predict + update on the possible location of this structure. eg. how likely it ends up present within some linear sequence, geographic surface, physical boundaries, or levels of feature abstraction
Our structure-based view is a reflection of our Westernised culture. English sentence descriptions centre around the subject, object, and adjectives. Westerners also often perceive active causation as the inherent causal feature of something or someone (eg. a mechanical function, a growth gene, or an aggressive personality).
Conversely, some traditional cultures foster a process-based view. Things are perceived as impermanent and ever-changing (see (action) verb-based Native American languages, or this wacky interpretation of Dzogchen philosophy).
A. They represent + recognise an observed change to be a trajectory in presence (a process). eg. a transition, movement, interaction, relation
B. They predict + update on whenever, wherever, and so forth, this process may initiate again.
Update: Some readers said they were confused by this distinction, or its relevance. → See cases of focussing on (interpreting and forecasting) processes vs. structures.
5. We view individuals as independent
Since we prefer sorting different things into ordered and mutually exclusive categories, we aren’t as aware of the relations between them (besides maybe endorsing this as a fact of reality upon reflection). In our attempts to carve nature at its joints, we neglect the ways persons and things are causally interdependent. That is, we do this even more strongly than broader Western individualist society (vs. say Asian collectivist cultures).
Quoting from the paper Culture and the Self: ❝Western view of the individual as an independent, self-contained, autonomous entity who (a) comprises a unique configuration of internal attributes (eg., traits, abilities, motives, and values) and (b) behaves primarily as a consequence of these internal attributes
❝Experiencing interdependence entails seeing oneself as part of an encompassing social relationship and recognizing that one’s behavior is determined, contingent on, and, to a large extent organized by what the actor perceives to be the thoughts, feelings, and actions of others in the relationship.
The RadicalxChange community recognises the interdependence of people as part of a collective whole. They attract members who often take up a more interdependent culture or mindset (social scientists, artists, African-Americans, women). To be fair, this might also be because RxC engages minority groups more, who in turn feel empowered to contribute to mechanisms that can overcome systemic exploitation. Update: minorities are less represented than I thought.
Revisiting Glen’s critiques, I interpret one basis to be our neglect of social interconnectedness: ❝We’re not going to pay that much attention to getting feedback from the people whose lives that affects or being in conversation with them. ❝cloistering themselves into a room ❝You have to think of the things you’re doing as speech acts and not purely intellectual acts… They condition a certain sort of a society. ❝a lot of the overly field experiment driven, effective ways of charitable giving that didn’t think about broader social structures and effects of that sort of stuff ❝the actual power that people derive in a decentralized way almost always comes from their ability to act collectively. It’s almost never possible on your own to exercise much power.
Update: Climate change is a case I think where noticing causal interdependencies can be especially insightful (if you don’t rely on a priori notions of interconnectedness). – Carbon emissions are not ‘one global thing’ but downstream from eg. farming animals intensively, cutting trees to expand farmland and to supply firewood for cooking, burning biomass that releases air pollutants, and subsidising polluting industries over investing in lower-cost clean alternatives. These activities harm local residents too through respiratory illness, self-reinforcing poverty cycles, estrangement from their surroundings, etc. Since these localised harms intertwine with global emissions,overlapping interventions can address both. – Carbon emissions are upstream from gases released into the atmosphere trapping heat, inducing anomalous weather patterns that further harm citizens worldwide, and also suck up their representatives’ attention and coordinated use of resources to mitigate other human-originated threats. (comment on how this is not simply about flow-through effects)
6. We view things as being external to us
In conversations, EAs and rationalists often attempt to convey a more impartial or objective view of the external world. This leads us to disregard personal interpretations when those are actually relevant (eg. for supporting a collaborator, or considering a friend’s needs and constraints when advising them on their career options).
In terms of individual persons, we could do worse though. Though people can be socially awkward, they do check in and consider how their conversation partner is feeling. Some of us are also really into introspection techniques and self-awareness (eg. rationalists writing about meditation experiences, Qualia Research Institute).
But since we focus more on the individual than the interdependent collective, we’re particularly unaware of the cultural feeling of our community, as well as any broader social repercussions of our actions.
Examples:
cases where 80,000 Hours staff didn’t catch on to the effects that their general career recommendations were having on the broader EA community (they’ve now more clearly specified the scope of their goals and whom they can serve)
LessWrong members who felt unwelcome and lonely, prompting Project Hufflepuff’s start (effective animal advocacy meetups though are more warm and cozy in my experience; one organiser shared more or less with me that outsiders see them as cutesy Hufflepuffs)
A. Interpret: recognise + represent aspects eg. classical archaeologists focus on differentiated recognition of artefacts, linguistic anthropologists on representing differentiated social contexts
B. Forecast: sample + predict aspects eg. development economists focus more on calibrated sampling of metrics, global prio scholars on calibrating their predictions of distilled scenarios
Our forecasting style focuses on calibrating likelihoods of a minimal set of aspects we deem to be primary or most important. eg. AI existential safety researchers who seek to improve the accuracy of their AGI timeline forecasts, rather than seek out other complementary interpretations relevant to developing beneficial AI.
A ‘reader of technological landscapes’ like Kevin Kelly can tell various trends or possibilities that others can’t (like an urbanite can’t tell the rich signs of natural landscapes). Similarly, venture capitalists focus less on fine-tuning their predictions of start-up exit scenarios and more on reading into the markers of performance (eg. founders ‘living in the future’ who confidently pursue their alternative vision for future products) that competing VCs and tech corps neglect.
Even to judge hits and misses, there’s a trade-off between calibrating likelihoods of a clean reference class (B), and differentiating which aspects to reference (A). Dialectic between the views: A: VCs anticipated tech trends before others did. B: Those VCs were overconfident; it rarely turned out as they specifically claimed. A: But they identified new frontiers and gaps to invest in, giving them an edge. B: An impartial sample of VC investors shows they got sub-par returns on average. A: A subpopulation of some geographical & intellectual origin got high returns. B: Those are spurious correlations you cherry-picked after the fact.
8. Gain vs. loss focus
To attain more positive valence vs. remove more negative valence.
Personal motivation matters because it guides how people frame their focus, pursue strategies, and assess aims. For example, x-risk leaders and s-risk managers may be predisposed to and socially reinforced to set goals differently, going by my stereotyped impressions:
Eliezer and Nick – to eagerly leap towards attaining their ideal for a more positive world state (powering over obstacles, towards the possible presence of a gain). Each originally led the start-up phase of a techno-optimistic institute. But they realised they needed to go pioneer research to prevent AGI misalignment in order to not sadly miss out on utopia.
Center on Long-Term Risk – to vigilantly maintain their responsibility to prevent a more negative world state (contain the intrusion of any potential loss, to control its absence). Founders originally met through discussions of moral philosophy, infused with German Weltschmerz. Managing secure, incremental charity operations is their core competence (update: an ops employee said CLT’s processes are more loose and exploratory than I let on). But they’re prepared to promote innovative start-up practices in order to relieve the universe from pessimistic scenarios of suffering.
9. (Sensory groundedness vs.) representational stability of beliefs
Markers of perception: 0. Present I. Time-bound II. Stitched III. Enclosed IV. Categorised
observation’s recurrence vs. sorted identity observed transition vs. analogised relation
0. Arising I. Follows II. Moves III. Crosses IV. Links
If you got this far, I’m interested to hear your thoughts! Do grab a moment to call so we can chat about and clarify the concepts. Takes some back and forth.
I found it immensely refreshing to see valid criticisms of EA. ... I think I disagree on the degree to which EA folks expect results to be universal and generalizable …
The way I’ve tended to think about these sorts of questions is to see a difference between the global portfolio of approaches, and our personal portfolio of approaches …
Comment 5: (a bunch of counterarguments and counterexamples)
Going by projects I’ve coordinated, EAs often push for removing paper conflicts of interest over attaining actual skin in the game.
Copying over my responses:
re: Conflicts of interest:
My impression has been that a few people appraising my project work looked for ways to e.g. reduce Goodharting, or the risk that I might pay myself too much from the project budget. Also EA initiators sometimes post a fundraiser write-up for an official project with an official plan, that somewhat hides that they’re actually seeking funding for their own salaries to do that work (the former looks less like a personal conflict of interest *on paper*).
re: Skin in the game:
Bigger picture, the effects of our interventions aren’t going to affect us in a visceral and directly noticeable way (silly example: we’re not going to slip and fall from some defect in the malaria nets we fund). That seems hard to overcome in terms of loose feedback from far-away interventions, but I think it’s problematic that EAs also seem to underemphasise skin in the game for in-between steps where direct feedback is available. For example, EAs seem sometimes too ready to pontificate (me included) about how particular projects should be run or what a particular position involves, rather than rely on the opinions/directions of an experienced practician who would actually suffer the consequences of failing (or even be filtered out of their role) if they took actions that had negative practical effects for them. Or they might dissuade someone from initiating an EA project/service that seems risky to them in theory, rather than guide the initiator to test it out locally to constrain or cap the damage.
To clarify the independent vs. interdependent distinction Julia suggested that EA thought about negative flow-through effects are an example of interdependent thinking. IMO EAs still tend to take an independent view on that. Even I did a bad job above of describing causal interdependencies in climate change (since I still placed the causal sources in a linear ‘this leads to this leads to that’ sequence).
So let me try to clarify again, at the risk of going meta-physical:
EAs do seem to pay more attention to causal dependencies than I was letting on, but in a particular way:
When EA researchers estimate impacts of specific flow-through effects, they often seem to have in mind some hypothetical individual who takes actions, which incrementally lead to consequences in the future. Going meta on that, they may philosophise about how an untested approach can have unforeseen and/or irreversible consequences, or about cluelessness (not knowing how the resulting impacts, spread out across the future, will average out). Do correct me if you have a different impression!
An alternate style of thinking involves holding multiple actors / causal sources in mind to simulate how they conditionally interact. This is useful for identifying root causes for problems, which I don’t recall EA researchers doing much of (e.g. the sociological/economic factors that originally made commercial farmers industrialise their livestock production).
To illustrate the difference, I think gene-environment interactions provide a neat case:
Independent ‘this or that’ thinking:
Hold one factor constant (e.g. take the different environments in which adopted twins grew up in as a representative sample) to predict the other (e.g. attribute 50% of variation of a general human trait to their genes).
Interdependent ‘this and that’ thinking:
Assume that factors will interplay, and therefore probabilities are not strictly independent.
Test nonlinear factors together to predict outcomes.
e.g. on/off gene for aggression × childhood trauma × teenagers playing violent video games
“A represents a set of possible ways the agent can be, E represents a set of possible ways the environment can be, and ⋅ : A × E → W is an evaluation function that returns a possible world given an element of A and an element of E”
Under the interdependent framing, the environment affords certain options perceivable by the agent, which they choose between.
A notion of Free Will loses its relevancy under this framing. Changes in the world were caused neither by the settings of the outside environment nor the embedded agent ‘willing’ an action, but rather as contingent on both.
You might counter: isn’t the agent’s body constituted of atomic particles that act and react deterministically over time, making free will an illusion?
Yes, and somehow in parts interacting across parts, they come to view the constitution of a greater whole, an agent, that makes choices.
None of these (admittedly confusing) framings have to be inconsistent with each other.
Overlap between ‘interdependent thinking’ and ‘context’ and ‘collective thinking’.
When individuals with their own distinct traits are constrained in the possible ways they can interact by surrounding others (i.e. by their context), they will behave predictably within those constraints:
e.g. when EAs stick to certain styles of analysis that they know comrades will grasp and admire when gathered at a conference or writing a post for others to read.
Analysis of the kind ‘this individual agent with x skills and y preferences will take/desist from actions that are more likely to lead to z outcomes’ falls flat here.
e.g. to paraphrase Critch’s Production Web scenario, which typical AI Safety analysis tends to overlook the severity of:
Take a future board that buys a particular ‘CEO AI service’ to ensure their company will be successful. The CEO AI elicits trustees for their inherent categorical preferences, but what they express at any given moment is guided by their recent interactions with influential others (e.g. the need to survive tougher competition by other CEO AIs). A CEO AI that plans company actions based on preferences elicited by board members’ preferences at any given point in time, will by default not account for actions bringing into existence processes that actually change the preferences board members state. That is, unless safety-minded AI developers design a management service that accounts for this circuitous dynamic, and boards are self-aware enough to buy the less-profit-optimised service that won’t undermine their personal integrity.
The risk emerges from how the AI developers and company’s board introduce assumptions of structure:
i.e. That you can design an AI to optimise for end states based on its human masters’ identified intrinsic preferences. That AI would fail to use available compute to determine whether a chosen instrumental action reinforces a process through which ‘stuff’ contingently gets flagged in human attention, expressed to the AI, received as inputs, and derived as ‘stable preferences’.
I left out nuances to keep the blindspot summary short and readable. But I should have specifically prefaced what fell outside the scope of my writing. Not doing so made claims come across more extreme than I meant for the more literal/explicit readers amongst us :)
So for you who still happens to read this, here’s where I was coming from:
To describe blindspots broadly across the entire rationality and EA community. In actual fact I see both communities more as loose clusters of interacting and affiliated people. Each gathered group somewhat diverges in how it attracts members who are predisposed towards focussing on (and reinforce each other to express) certain aspects as perceived within certain views.
I pointed out how a few groups diverge in the summary above (e.g. effective animal advocacy vs. LW decision theorists, thriving vs suffering-focussed EAs), but left out many others. Responding to Christian Kl’s earlier comment, I think how the ‘CFAR alumni’ cluster frames aspects meaningfully diverges from the larger/overlapping ‘long-time LessWrong fans’ cluster.
Previously, I suggested that EA staff could coordinate work more through non-EA-branded groups with distinct yet complementary scopes and purposes, so the general overarching tone of this post runs counter to that.
To aggregate common views within which our members seemed to most often frame problems (as expressed to others involved in the community they knew also aimed to work on those problems), and to contrast those with the foci held by other purposeful human communities out there.
Naturally, what an individual human focusses on in any given moment depends on their changing emotional/mental makeup and the context they find themselves (incl. the role they then identify as having) in. I’m not e.g. claiming that when someone who aspires to be a rational researcher at work focusses on brushing their teeth at home while glancing at their romantic partner, they must nevertheless be thinking real abstract and elegant thoughts.
But for me, the exercise of mapping ouringroup’s brightspots onto each listed dimension – relative to the focus of outside groups on – has provided some overview. The dimensions are from a perceptual framework I gradually put together and that is somewhat internally coherent (but predictably overwhelms anyone whom I explain it to, and leaves them wondering how it’s useful; hence this more pragmatic post).
I hope though no reader ends up using this as a personality test – say for identifying their or their friend’s (supposedly stable) character traits to predict their resulting future behaviour (or god forgive, to explain away any confusion or disagreement they sense about what an unfamiliar stranger says).
To keep each blindspot explanation simple and to the point: If I already mix in a lot of ‘on one hand in this group...but on the other hand in this situation’, the reader will gloss over the core argument. I appreciate people’s comments with nuanced counterexamples though. Keeps me intellectually honest.
Hope that clarifies the post’s argumentation style somewhat. I had those three starting points at the back of my mind while writing in March. So sorry I didn’t include them.
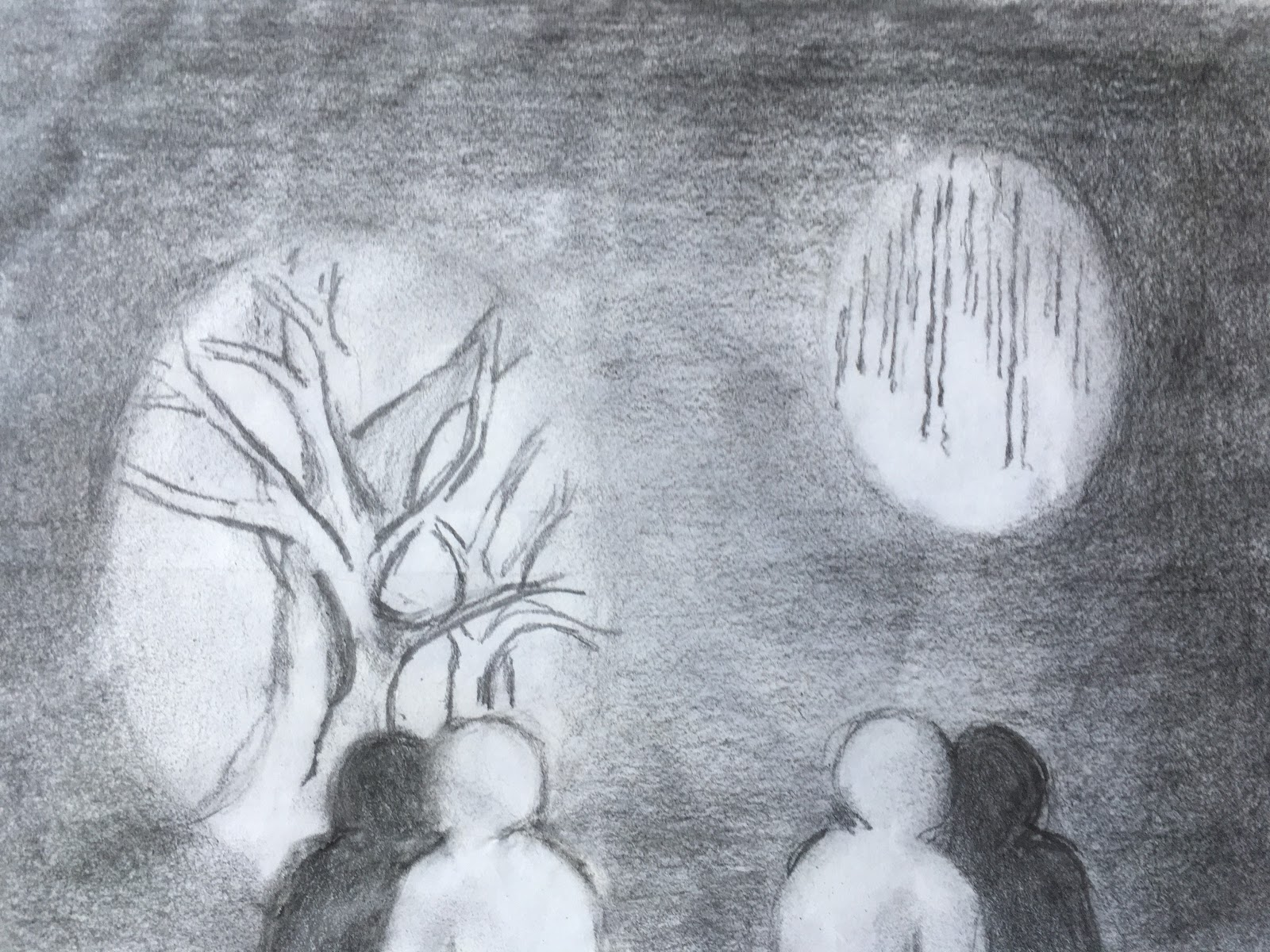
See also LessWrong Forum:
Comment 1 (on my portrayal of Eliezer’s portrayal of AGl):
Comment 2:
Comment 3:
Comment 4:
Comment 5:
(a bunch of counterarguments and counterexamples)
Two people asked me to clarify this claim:
Copying over my responses:
re: Conflicts of interest:
My impression has been that a few people appraising my project work looked for ways to e.g. reduce Goodharting, or the risk that I might pay myself too much from the project budget. Also EA initiators sometimes post a fundraiser write-up for an official project with an official plan, that somewhat hides that they’re actually seeking funding for their own salaries to do that work (the former looks less like a personal conflict of interest *on paper*).
re: Skin in the game:
Bigger picture, the effects of our interventions aren’t going to affect us in a visceral and directly noticeable way (silly example: we’re not going to slip and fall from some defect in the malaria nets we fund). That seems hard to overcome in terms of loose feedback from far-away interventions, but I think it’s problematic that EAs also seem to underemphasise skin in the game for in-between steps where direct feedback is available. For example, EAs seem sometimes too ready to pontificate (me included) about how particular projects should be run or what a particular position involves, rather than rely on the opinions/directions of an experienced practician who would actually suffer the consequences of failing (or even be filtered out of their role) if they took actions that had negative practical effects for them. Or they might dissuade someone from initiating an EA project/service that seems risky to them in theory, rather than guide the initiator to test it out locally to constrain or cap the damage.
This interview with Jacqueline Novogratz from Acumen Fund covers some practical approaches to attain skin in the game.
I’m actually interested to hear your thoughts!
Do throw them here, or grab a moment to call :)
To clarify the independent vs. interdependent distinction
Julia suggested that EA thought about negative flow-through effects are an example of interdependent thinking. IMO EAs still tend to take an independent view on that. Even I did a bad job above of describing causal interdependencies in climate change (since I still placed the causal sources in a linear ‘this leads to this leads to that’ sequence).
So let me try to clarify again, at the risk of going meta-physical:
EAs do seem to pay more attention to causal dependencies than I was letting on, but in a particular way:
When EA researchers estimate impacts of specific flow-through effects, they often seem to have in mind some hypothetical individual who takes actions, which incrementally lead to consequences in the future. Going meta on that, they may philosophise about how an untested approach can have unforeseen and/or irreversible consequences, or about cluelessness (not knowing how the resulting impacts, spread out across the future, will average out). Do correct me if you have a different impression!
An alternate style of thinking involves holding multiple actors / causal sources in mind to simulate how they conditionally interact. This is useful for identifying root causes for problems, which I don’t recall EA researchers doing much of (e.g. the sociological/economic factors that originally made commercial farmers industrialise their livestock production).
To illustrate the difference, I think gene-environment interactions provide a neat case:
Independent ‘this or that’ thinking:
Hold one factor constant (e.g. take the different environments in which adopted twins grew up in as a representative sample) to predict the other (e.g. attribute 50% of variation of a general human trait to their genes).
Interdependent ‘this and that’ thinking:
Assume that factors will interplay, and therefore probabilities are not strictly independent.
Test nonlinear factors together to predict outcomes.
e.g. on/off gene for aggression × childhood trauma × teenagers playing violent video games
Cartesian frames seem an apt theoretical analogy
“A represents a set of possible ways the agent can be, E represents a set of possible ways the environment can be, and ⋅ : A × E → W is an evaluation function that returns a possible world given an element of A and an element of E”
Under the interdependent framing, the environment affords certain options perceivable by the agent, which they choose between.
A notion of Free Will loses its relevancy under this framing. Changes in the world were caused neither by the settings of the outside environment nor the embedded agent ‘willing’ an action, but rather as contingent on both.
You might counter: isn’t the agent’s body constituted of atomic particles that act and react deterministically over time, making free will an illusion?
Yes, and somehow in parts interacting across parts, they come to view the constitution of a greater whole, an agent, that makes choices.
None of these (admittedly confusing) framings have to be inconsistent with each other.
Overlap between ‘interdependent thinking’ and ‘context’ and ‘collective thinking’.
When individuals with their own distinct traits are constrained in the possible ways they can interact by surrounding others (i.e. by their context), they will behave predictably within those constraints:
e.g. when EAs stick to certain styles of analysis that they know comrades will grasp and admire when gathered at a conference or writing a post for others to read.
Analysis of the kind ‘this individual agent with x skills and y preferences will take/desist from actions that are more likely to lead to z outcomes’ falls flat here.
e.g. to paraphrase Critch’s Production Web scenario, which typical AI Safety analysis tends to overlook the severity of:
Take a future board that buys a particular ‘CEO AI service’ to ensure their company will be successful. The CEO AI elicits trustees for their inherent categorical preferences, but what they express at any given moment is guided by their recent interactions with influential others (e.g. the need to survive tougher competition by other CEO AIs). A CEO AI that plans company actions based on preferences elicited by board members’ preferences at any given point in time, will by default not account for actions bringing into existence processes that actually change the preferences board members state. That is, unless safety-minded AI developers design a management service that accounts for this circuitous dynamic, and boards are self-aware enough to buy the less-profit-optimised service that won’t undermine their personal integrity.
The risk emerges from how the AI developers and company’s board introduce assumptions of structure:
i.e. That you can design an AI to optimise for end states based on its human masters’ identified intrinsic preferences. That AI would fail to use available compute to determine whether a chosen instrumental action reinforces a process through which ‘stuff’ contingently gets flagged in human attention, expressed to the AI, received as inputs, and derived as ‘stable preferences’.
I left out nuances to keep the blindspot summary short and readable. But I should have specifically prefaced what fell outside the scope of my writing. Not doing so made claims come across more extreme than I meant for the more literal/explicit readers amongst us :)
So for you who still happens to read this, here’s where I was coming from:
To describe blindspots broadly across the entire rationality and EA community.
In actual fact I see both communities more as loose clusters of interacting and affiliated people. Each gathered group somewhat diverges in how it attracts members who are predisposed towards focussing on (and reinforce each other to express) certain aspects as perceived within certain views.
I pointed out how a few groups diverge in the summary above (e.g. effective animal advocacy vs. LW decision theorists, thriving vs suffering-focussed EAs), but left out many others. Responding to Christian Kl’s earlier comment, I think how the ‘CFAR alumni’ cluster frames aspects meaningfully diverges from the larger/overlapping ‘long-time LessWrong fans’ cluster.
Previously, I suggested that EA staff could coordinate work more through non-EA-branded groups with distinct yet complementary scopes and purposes, so the general overarching tone of this post runs counter to that.
To aggregate common views within which our members seemed to most often frame problems (as expressed to others involved in the community they knew also aimed to work on those problems), and to contrast those with the foci held by other purposeful human communities out there.
Naturally, what an individual human focusses on in any given moment depends on their changing emotional/mental makeup and the context they find themselves (incl. the role they then identify as having) in. I’m not e.g. claiming that when someone who aspires to be a rational researcher at work focusses on brushing their teeth at home while glancing at their romantic partner, they must nevertheless be thinking real abstract and elegant thoughts.
But for me, the exercise of mapping our ingroup’s brightspots onto each listed dimension – relative to the focus of outside groups on – has provided some overview. The dimensions are from a perceptual framework I gradually put together and that is somewhat internally coherent (but predictably overwhelms anyone whom I explain it to, and leaves them wondering how it’s useful; hence this more pragmatic post).
I hope though no reader ends up using this as a personality test – say for identifying their or their friend’s (supposedly stable) character traits to predict their resulting future behaviour (or god forgive, to explain away any confusion or disagreement they sense about what an unfamiliar stranger says).
To keep each blindspot explanation simple and to the point:
If I already mix in a lot of ‘on one hand in this group...but on the other hand in this situation’, the reader will gloss over the core argument. I appreciate people’s comments with nuanced counterexamples though. Keeps me intellectually honest.
Hope that clarifies the post’s argumentation style somewhat.
I had those three starting points at the back of my mind while writing in March. So sorry I didn’t include them.