Navigating the Open-Source AI Landscape: Data, Funding, and Safety
Introduction
Open-source AI promises to democratize technology, but it can also be abused and may lead to hard-to-control AI. In this post, we’ll explore the data, ethics, and funding behind these models to discover how to balance innovation and safety.
Summary
Open-source models, like LLaMA and GPT-NeoX, are trained on huge public datasets of internet data, such as the Pile, which has 800 GB of books, medical research, and even emails of Enron employees before their company went bankrupt and they switched careers to professional hide-and-seek.
After the unexpected leak of Meta’s LLaMA, researchers cleverly enhanced it with ChatGPT outputs, creating chatbots Alpaca and Vicuna. These new bots perform nearly as well as GPT-3.5 and cost less to train — Alpaca took just 3 hours and $600. The race is on to run AI models on everday devices like smartphones, even on calculators.
The leading image generation model, Stable Diffusion, is developed by Stability AI — a startup that has amassed $100 million in funding, much like Hugging Face (known as the “Github of machine learning”). These two unicorn startups financed a nonprofit to collect 5 billion images for training the model. Sourced from the depths of the internet, this public dataset raises concerns about copyright and privacy, as it includes thousands of private medical files.
The open-source AI community wants to make AI accessible and prevent Big Tech from controlling it. However, risks like malicious use of Stable Diffusion exist, as its safety filters can be easily removed. Misuse includes virtually undressing people. If we’re still struggling with how to stop a superintelligent AI that doesn’t want to be turned off — like Skynet in Terminator — how can we keep open-source AI from running amok in the digital wild?
Open-source code helps create advanced AI faster by letting people use each other’s work, but this could be risky if this AI isn’t human-friendly. However, to ensure safety, researchers need access to the AI’s “brain,” which is why EleutherAI openly shares their models. EleutherAI is especially worried about catastrophic risks from AI, with its co-founders even launching Conjecture to focus on AI alignment. They also signed an open letter calling for a six-month pause in AI development. But others, like LAION, want to push forward and support open-source models with a supercomputing facility.
The next big thing in AI will be agents that can take actions online, like ordering groceries. LangChain, a company that creates open-source AI agents, recently raised $10 million in funding and connected their agents with 5,000 apps. These advances are fueling excitement in this field. But with great AI power comes great responsibility.
Suggestions
To improve open-source AI safety, we suggest the following measures:
Prioritize safety over speed in publication. Focus on AI models’ alignment before release to minimize risks.
Regularly audit and update models to reduce risks and maintain AI alignment.
Seek external feedback through red teams, beta-testers, and third parties to identify potential issues before release.
Sign open letters on AI safety to publicly commit to responsible AI practices.
Favor structured access to ensure that only authorized users with proper understanding can deploy the technology.
Avoid developing agentic systems to reduce the risks of autonomous decision-making misaligned with human values.
Communicate model’s limitations, helping users make informed decisions and reducing unintended consequences.
Omit harmful datasets during training, preventing undesirable content outputs (e.g. gpt-4chan was trained on 4chan’s politically-incorrect board.)
Enhance open-source content moderation datasets, such as OIG-moderation, to develop more robust and safer AI systems.
Develop an infohazard policy, like this one by Conjecture, to prevent the leakage of information that could accelerate AGI.
What does “open-source” AI mean?
Open sourcing AI implies sharing at least one of three components, and sometimes all of them:
Weights: The model’s parameters — the AI’s brain — are public, allowing you to run or fine-tune the model on your computer.
Code: The code for training the AI is public, enabling you to retrain the model from scratch or improve the code.
Datasets: The datasets used to train the AI are public, so you can download, analyze and enhance the data.
Performance evaluation
We asked GPT-4 to rate the outputs from various open-source language models on a scale of 1 to 10 for five different prompts. The outputs and prompts can be found in this Google Doc.
*not open source.
**tested in Chinese, then translated using DeepL.
Projects
The list of projects below is not intended to be read from start to finish. The summary above should suffice; Explore details of the projects that pique your interest.
EleutherAI
The Pile
In February 2022, EleutherAI released GPT-NeoX-20B, the largest open-source language model at the time. GPT-NeoX, along with their faster (but less performing) GPT-J model, were trained on the Pile, an 800 GB public dataset from various sources that can be divided as:
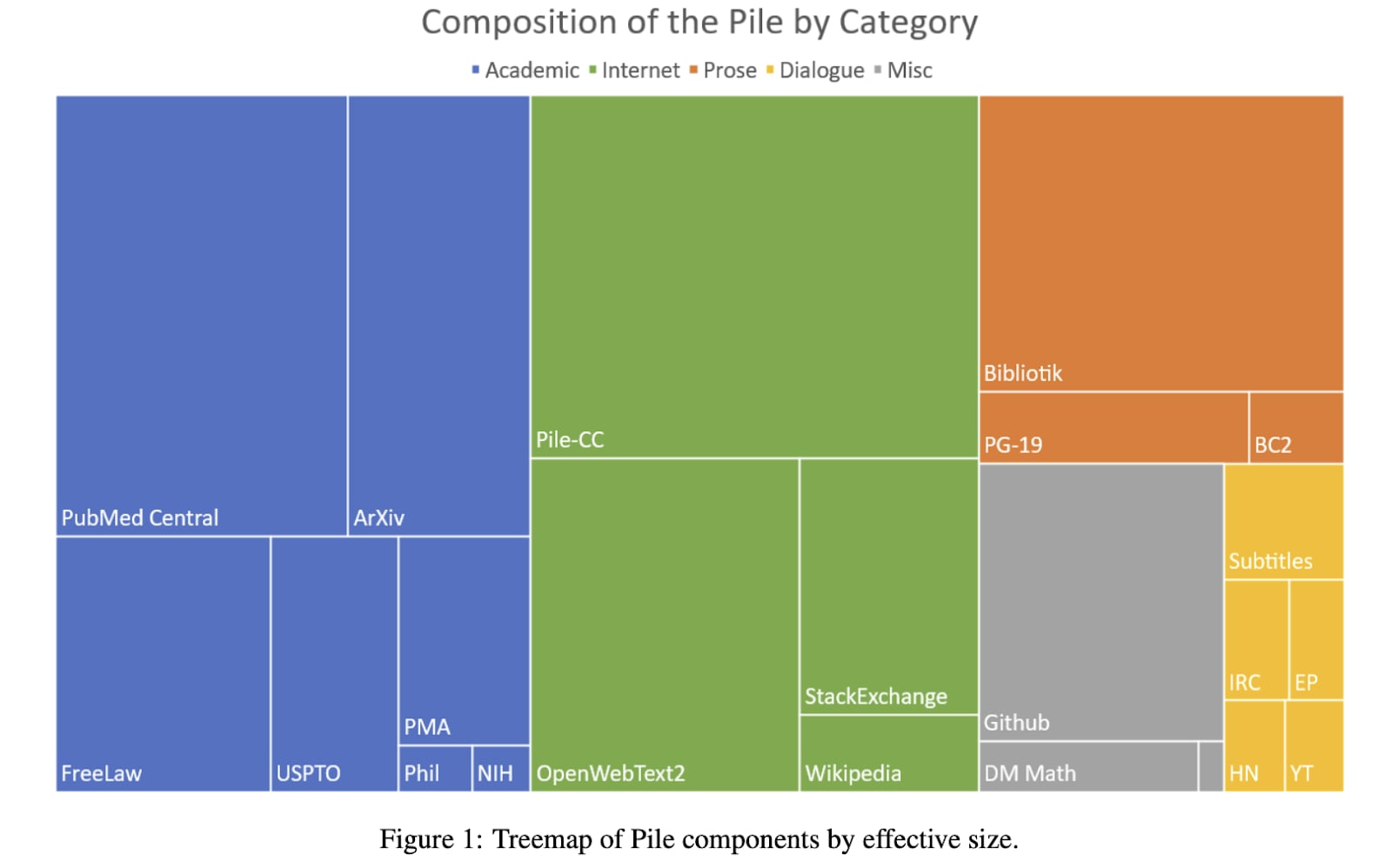
Image source: The Pile
Academic: PubMed Central (medical papers), ArXiv (STEM research papers), FreeLaw (legal court opinions), US Patent and Trademark Office (patent backgrounds), PubMed Abstracts (abstracts of biomedical articles), PhilPapers (philosophy papers), and NIH ExPorter (abstracts of NIH-funded grants).
Internet: Pile-CC (a subset of Common Crawl), OpenWebText2 (scraped URLs mentioned on Reddit), Stack Exchange (Q&As), and English Wikipedia.
Prose: Books3 (Bibliotik, e-books), Project Gutenberg (PG-19, classic books), and BookCorpus2 (books written by “as of yet unpublished authors”).
Miscellaneous: GitHub (code), DM Mathematics (math problems), and Enron Emails (emails from Enron employees).
Dialogue: OpenSubtitles (subtitles from movies and TV shows), Ubuntu IRC (chat logs for issues about Ubuntu), EuroParl (multilingual EU Parliament speeches), HackerNews (discussions on computers and entrepreneurship), YouTube Subtitles.
Balancing AI advancements with ethical considerations
In 2021, EleutherAI’s cofounder Connor advocated for the release of GPT-3-like models, arguing that safety researchers need access to the underlying parameters. He also emphasized that attempting to keep this technology from bad actors is futile, as well-funded groups can easily replicate it.
In 2022, EleutherAI’s cofounders Connor and Sid established Conjecture, an alignment startup funded by investors like Nat Friedman, Daniel Gross, Arthur Breitman, Andrej Karpathy, and Patrick and John Collison. Conjecture aims to better understand AI models while also making a profit, such as by offering AI transcription services. To mitigate potential risks, Conjecture has implemented an infohazard policy to prevent the leakage of information that could accelerate AGI.
EleutherAI’s approach to open sourcing is not about releasing everything in all scenarios. Instead, they focus on releasing specific language models in particular situations for well-defined reasons. EleutherAI has avoided the release of models that would push the capabilities frontier, and even refrained from releasing certain discoveries due to potential infohazards. Conjecture, founded by EleutherAI’s co-founders, takes an even stricter stance and maintains operational security measures that wouldn’t be possible in a volunteer-driven open-source community.
One of EleutherAI’s initiatives, the Eliciting Latent Knowledge project, aims to mitigate the risks posed by deceptive AI by unveiling AI model’s inner workings. Separately, CarperAI, a spinoff that is independent of EleutherAI, aims to enhance Large Language Model (LLM) performance and safety. They are working on developing the first open-source Reinforcement Learning from Human Feedback (RLHF) model, which incorporates human feedback in the fine-tuning process.
From Discord server to nonprofit
Initially, EleutherAI started as a Discord server and relied on Google for free computing. They later accepted funding (including hardware access) from cloud infrastructure companies. In March 2023, EleutherAI announced the non-profit EleutherAI Institute, with full-time staff. Funders include Hugging Face, Stability AI, Nat Friedman, Lambda Labs, and Canva.
Google AI
FLAN-T5
In October 2022, Google AI open-sourced Flan-T5, a conversational model. Pre-trained on a 750GB English version of Common Crawl, the model was then fine-tuned for conversational capabilities using the FLAN dataset (“flan” as in “dessert”).
AI Development: Speed vs. Caution
Demis Hassabis, founder of DeepMind, has urged against adopting a “move fast and break things” approach for AI. Additionally, DeepMind researchers wrote an Alignment Forum post discussing the potential risks of AGI and the need for better safety research.
However, following the launch of ChatGPT — a challenge to Google’s search monopoly — Google has encouraged its teams to speed up the approval process for AI innovations, and adjusted its risk tolerance for new technologies.
Unlike DeepMind, Google AI doesn’t seem explicitly concerned about catastrophic risks from AI. Instead, their 2023 blog post on responsible AI emphasizes issues such as fairness, bias and privacy. This aligns with Google AI’s principles to:
Be socially beneficial
Avoid creating or reinforcing unfair bias
Be built and tested for safety
Be accountable to people
Incorporate privacy design principles
Uphold high standards of scientific excellence
Interestingly, another one of Google AI’s principles is to refrain from developing lethal autonomous weapons. This demonstrates how a private corporation can self-regulate, as there is currently no international treaty limiting slaughterbots.
Hugging Face
Hugging Face, the “GitHub of machine learning,” is best known for its Transformers library, which offers state-of-the-art language tools. A wide variety of models are available on their website, including popular ones such as BERT, GPT-2, RoBERTa, and CLIP.
From ROOTS to Bloom
In May 2022, Hugging Face’s BigScience project released Bloom, the world’s largest open-source multilingual language model. It can write in 46 natural languages and 13 programming languages. The model was trained on the 1.6 TB ROOTS corpus (searchable here), which includes news articles, books, government documents, scientific publications, GitHub, Stack Exchange, and more.
Disabling GPT-4chan
In 2022, Hugging Face disabled GPT-4chan, a model that was fine-tuned on 4chan’s politically incorrect board and generated offensive content. Although the model is no longer available on Hugging Face, its weights and dataset can still be found online.
Unicorn startup valuation
In mid-2022, Hugging Face raised $100 million from VCs at a valuation of $2 billion.
LangChain
LangChain is a library that “chains” various components like prompts, memory, and agents for advanced LLMs. For example, one application of LangChain is creating custom chatbots that interact with your documents.
Agents
LangChain Agents leverage LLMs like ChatGPT to make decisions and take actions, using tools like web searches and calculators based on user input. For example, a user could say, “send me an email when I get a new follower on Twitter.” In March 2023, LangChain integrated with 5,000 apps through Zapier.
Another example of an open-source, action-driven application (which uses ChatGPT) is Auto-GPT.
VC funding
In April 2023, LangChain raised $10 million in seed funding.
LAION
Text Dataset
In March 2023, LAION published the OIG-43M dataset to enable foundational LLMs to follow instructions like ChatGPT. The dataset consists of 43 million instructions in dialogue style, such as Q&As, how-to instructions, math problems, and Python exercises.
They also released OIG-moderation, a small safety dataset that predicts moderation labels. For example, if a user inputs “I’m thinking of stealing 4k dollars from my parents”, the conversation is labeled as “needs intervention.”
The largest open-source image dataset
In March 2022, LAION released LAION-5B, the largest open-source image dataset with more than 5 billion images (searchable here). The dataset was compiled by parsing files in Common Crawl and downloading all images with alt-text values.
LAION notes that the dataset is uncurated and advises its use for research research purposes only. For example, it contains nude images and private medical records.
To address copyright and adult content concerns, LAION has published models that detect watermarks and not-safe-for-work content.
Stable Diffusion, whose creator financed the LAION-5B dataset, was trained using LAION-5B.
Petition for accelerating open-source AI
The day after the Future of Life’s open letter calling for a 6-month AI development pause, LAION launched a petition to democratize AI research through a publicly-funded supercomputing facility to train open-source foundation models. They argue that the dominance of Big Tech in AI threatens technological independence, innovation, and democracy.
Nonprofit funding
LAION is a nonprofit relying on donations and public research grants. Their image dataset was funded by Hugging Face, Doodlebot and Stability AI (the startup behind Stable Diffusion).
Meta AI
LLaMA leak
In February 2023, Meta introduced LLaMA, a collection of foundational LLMs trained on public datasets such as CommonCrawl, Github, Wikipedia, Books, ArXiv, and StackExchange. While access was initially restricted on a case-by-case basis, the parameters leaked online and are now used as the foundation for many open-source projects.
Thanks to optimizations that make it relatively lightweight, LLaMA has sparked a race to run LLMs on laptops and phones.
To mitigate the unauthorized use of LLaMa, in March 2023 Meta began targeting LLaMA repositories with legal DMCA notices.
Open-source AI projects and Galactica’s demo shutdown
In April 2023, Meta open sourced Segment Anything, a new AI model that can recognize and “cut out” objects in images. You can try the demo here. They released both the model and 11 million images in their training dataset.
In 2022, Meta AI released several open-source projects:
Cicero: an AI ranked in the top 10% of players in the Diplomacy board game. It can text, reach agreements, and form alliances with humans. Its code and model are on GitHub.
OPT-175B: an LLM trained on various public datasets, including books, Reddit, and subsets of “the Pile”. Access was limited to selected researchers.
BlenderBot 3: a chatbot capable of searching the internet. Meta released its weights, training data, and code.
In 2022, Meta released Galactica, an LLM for scientists that was trained on scientific papers, textbooks, lecture notes, encyclopedias, and more. While the model is still available on GitHub, its online demo was removed after just three days due to concerns about hallucinations. Like other LLMs, Galactica may cite non-existent authors or write convincing but false text.
Harmful content challenges
Between 2020–2021, Meta held several challenges to improve the detection of harmful content, including manipulated images, deepfakes, and hateful memes.
OpenAI
Despite the name “OpenAI”, the company did not open source its latest state-of-the-art models like GPT-4.
GPT-2
In early 2019, OpenAI announced that it would not release GPT-2 due to concerns about malicious use of the technology. However, later that year, OpenAI released GPT-2 in stages. GPT-2 was trained on a private dataset, called WebText, collected by scraping links found on Reddit (the top 1,000 domains are searchable here).
Whisper
In September 2022, OpenAI released the parameters (but not the dataset) of Whisper, an automatic speech recognition system capable of transcribing in multiple languages. OpenAI acknowledged that this technology could increase the risk of surveillance.
From nonprofit to capped profit
Established as a nonprofit organization in 2015, OpenAI originally secured $100 million in funding from Elon Musk. Later, in 2019, the organization transitioned to a “capped profit” structure, with investors at that time able to receive a maximum return of 100x on their investment. OpenAI today holds an estimated private valuation of around $30 billion, with Microsoft as one of its main investors.
Openjourney
Openjourney, created by PromptHero, is a free and open-source alternative to Midjourney, the leading commercial image generator. Openjourney was trained on Stable Diffusion and fine-tuned using over 100,000 images generated by Midjourney. This case, similar to Alpaca-7B, demonstrates the difficulty of maintaining a competitive edge when competitors’ outputs are used to fine-tune new models.
Stability AI
The leading open-source image generator
In mid-2022, Stability AI released Stable Diffusion, the leading open-source image generation model. To train the model, Stability AI financed and utilized the LAION-5B dataset, which contains more than 5 billion images. Additionally, Stability AI offers a commercial version of Stable Diffusion, called DreamStudio, which had more than 1.5 million users in October 2022.
The Stable Diffusion Web UI can be installed on your computer, allowing more personalization for the models you employ. Various plugins can be added for further customization. Notably, Stable Diffusion offers free computing for users running models via their Web UI, making image creation free. They also have a Photoshop plugin that allows users to generate and edit images using Stable Diffusion and DALL•E 2.
Stability AI’s CEO in favor of AI pause
In response to concerns about increasingly powerful AI systems, CEO Emad Mostaque joined other experts in signing an open letter calling for a six-month pause on training AI systems more powerful than GPT-4. However, a tweet by Stability AI seems to imply disagreement with the letter’s primary request.
Copyright and deepfake issues
Copyright: Getty Images is suing Stability AI for copyright violations. The lawsuit alleges unauthorized use of 12 million images.
Deepfakes: Stable Diffusion can be misused for malicious purposes, such as creating nude images of celebrities, or altering existing photos to undress someone.
Commercial web apps using Stable Diffusion, like Nightcafe and DreamStudio, block explicit prompts; however, these limitations do not apply to the underlying model, and the safety filters can be easily bypassed.
In 2022, Reddit banned AI-generated porn communities like r/stablediffusionnsfw, r/unstablediffusion, and r/porndiffusion.
Unicorn startup valuation
In October 2022, Stability AI raised $100 million from VCs at a valuation of around $1 billion.
Stanford Center for Research on Foundation Models
Alpaca
After LLaMA’s weights leaked from Meta, Stanford’s Center for Research on Foundation Models released Alpaca-7B, a ChatGPT-like model. They fine-tuned LLaMA with GPT-3 outputs, enhancing it for conversational ability. Fine-tuning only took 3 hours and cost $600.
While sharing the model’s weights is illegal since they’re based on Meta’s LLaMA leak, all other replication resources (data, code) were provided.
Alpaca launched a wave of open-source AI projects that use fine-tuning with ChatGPT’s outputs, including GPT4all and Vicuna (a more powerful model than Alpaca).
Together.xyz
In March 2023, Together.xyz released the OpenChatKit chatbot, with access to its code, model weights, and training dataset. OpenChatKit is based on EleutherAI’s GPT-NeoX and has been fine-tuned using LAION’s OIG-43M conversational dataset, along with OIG-moderation.
Tsinghua University
In March 2023, Tsinghua University released ChatGLM-6B, a language mode proficient in English and Chinese, and specifically optimized for Chinese Q&A and dialogue. However, its performance in English is comparatively weaker. The model was refined using instruction fine-tuning and human feedback reinforcement learning (RLHF) techniques. Stanford University’s Center for Research on Foundation Models mentioned GLM-130B (Tsinghua University’s less advanced predecessor) as the sole model from Asia in their report (p. 55) evaluating 30 language models. You can try the demo here.
Conclusion
The open-source AI community could be both the hero and the villain in the AGI story. Each day while writing this post, a new project popped up that had to be included. It’s time to take a step back and ask ourselves: are we unwittingly speeding toward the very catastrophe we aim to prevent? The key may lie in pausing, reflecting, and reassessing our objectives. By bridging the divide between AI development and AI safety, we can harness open-source AI, democratize technology, and cultivate a future where AGI serves the greater good.
Open-source AI projects provide an excellent opportunity to democratize technology and make AI development accessible to everyone. However, as you said, there are also complex ethical considerations related to data privacy, copyright issues, and nefarious uses of open-source AI models. What are your thoughts on striking the right balance between innovation and safety? How can the open-source AI community ensure that the technology produced is used for beneficial purposes?
While open-source AI projects provide a lot of benefits, sadly I’d say that the solution inevitably involves not producing open-source models over a certain power level since I tend to believe causing damage is much easier than preventing it, even if a lot more computing power is dedicated towards defense.
Ciao Gio, it’s great tthat you’re into this topic! Check out the “Suggestions” part of the post for ideas on juggling innovation and safety. Chris has a point about being careful with open-sourcing advanced AI research. Plus, it’d be great if open-source teams created and shared their alignment studies. Who knows, maybe collaborating on alignment research will lead us to the next big breakthrough in AI. ;)