Towards evidence gap-maps for AI safety
An Evidence Gap Map (EGM) is visual tool that provides an overview of the existing evidence on a topic. They are a starting point for strategic evidence production and use. Organisations like the WHO, 3ie Impact and UNICEF produce EGMs that make evidence available in an accessible format for decision makers.
This is a post to prompt discussion about whether evidence gap-maps could and should be used by the AI safety community to inform decision-making, policy strategies, allocate resources and prioritising research efforts. They are to be interpreted cautiously. Strong recommendations can result from low confidence in effect estimates or from even low effect sizes.
How could an AI safety evidence gap map look?
This is a simplified, illustrative mockup of an EGM about interventions that alter the rate of AI progress. The shortlist of interventions and assessments of the strength of evidence has been made-up for illustrative purposes only.
| Interventions | Data | Algorithms | Compute |
| A. Taxation | M | L | L |
| B. Subsidies | L | L | M |
| C. Law Enforcement | M | M | L |
| D. Education and Workforce Dev | H | M | L |
| E. Research Funding | M | M | L |
| F. Intellectual Property Rts | L | M | L |
| G. Data Privacy and Security | M | M | L |
| H. Open Data Initiatives | M | M | L |
| J. Intl Collab and Governance | M | M | L |
| K. Antitrust laws | M | L | M |
| L. Sanctions | M | M | M |
| M. Military Intervention | M | L | M |
| N. Treaties | L | L | L |
Remember, this is placeholder data for illustrative purposes, I did not review the literature.
As you can see, EGMs are matrices, where the rows display the interventions and the columns display the outcomes or the factors that may affect the implementation of interventions:
In the rows you will see shortlisted interventions
In the columns you can see: “compute,” “algorithms,” and “data” which are possible indicators of AI progress.
In the cells, strength of evidence are coded under the GRADE (Grading of Recommendations, Assessment, Development, and Evaluations) framework:
Certainty | What it means |
Very low | The true effect is probably markedly different from the estimated effect |
Low | The true effect might be markedly different from the estimated effect |
Moderate | The authors believe that the true effect is probably close to the estimated effect |
High | The authors have a lot of confidence that the true effect is similar to the estimated effect |
GRADE is subjective and certainty can be rated down for: risk of bias, imprecision, inconsistency, indirectness, and publication bias. Certainty can be rated up for: large magnitude of effect, exposure-response gradient and residual confounding that would decrease magnitude of effect (in situations with an effect).
In the GRADE framework you will see the term estimated effect. This is another consideration. Separating confidence in estimates or quality of evidence from judgements about the size of effect estimates (the kind you can find in a meta-analysis) is important. There can be low confidence in a high effect estimate and vice-versa.
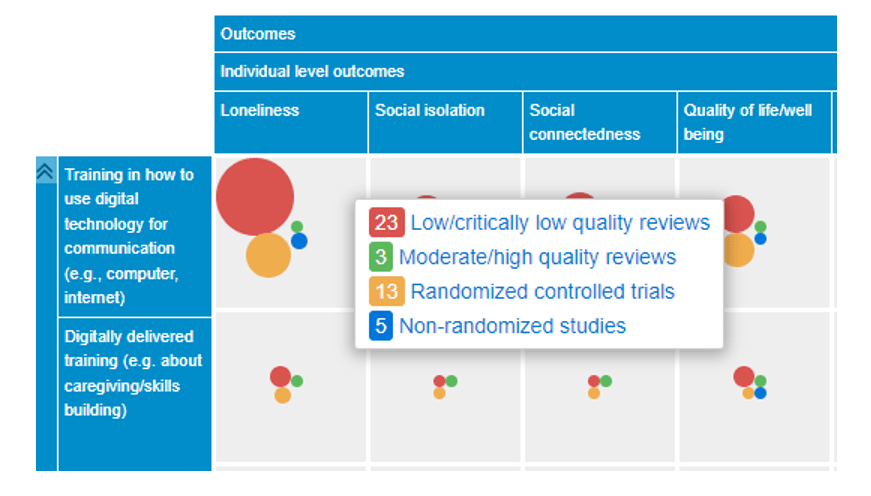
Don’t systematic reviews make these redundant? No, evidence gap maps’ development can be faster, more responsive and easier for decision-makers to interpret than systematic reviews: all available studies can be included in the EGM whether or not it is complete. You can see what I mean when we move on from my simplified, illustrative example of an AI Safety EGM to an actual EBM from the Cochrane and Campbell Collaborations:
Thanks for the post!
I’m familiar with EGMs in the spaces you mentioned. I can see EGMs being quite useful if the basic ideas in an area are settled enough to agree on outcomes (eg the thing that the interventions are trying to create)
Right now I’m unsure what this would be. That said, I support the use of EGMs for synthesising evidence and pointing out research directions. So it could be useful to construct one or some at the level of “has anyone done this yet?”