TIO: A mental health chatbot
This post describes a mental health chatbot, which we call the Talk It Over Chatbot (sometimes TIO for short). The first work on the bot started in 2018, and we have been working more earnestly since 2019.
My main aim is to explore whether I should seek funding for it. (It is currently volunteer-led)
Here’s a summary of my findings:
Using direct-results thinking: a cost-effectiveness model indicates that the direct results of this project may be competitive with the benchmark (Strong Minds), as assessed with a cost-effectiveness model, however this is based on a number of assumptions.
Using hits-based thinking: this bot is distinctive in having a conversational interface with a programmed bot and also allowing that conversation to be free-flowing. This distinctive approach may allow us to resolve an evidence gap on the effectiveness of certain therapies
This post invites:
Material arguments for or against funding this
Interest from funders
Interest from volunteers
Our motivations when we started this project
The bot was created by a team of volunteers, the initial three of which were current/former volunteers with Samaritans, a well-known UK charity which provides emotional support to the distressed and despairing, including those who are suicidal.
A big part of our motivation was the fact that we knew there was a big demand for the Samaritans service, but nowhere near enough supply. This meant that our initial prototype need not outperform a human, it need only outperform (e.g.) calling the Samaritans and getting the engaged tone.
We also suspected that some users might prefer speaking to software, and this suspicion has been confirmed.
Another motivation was the fact that lots of important decisions we made were under-evidenced or unevidenced. Specifically, when deciding what we, as individual therapeutic listeners, should say to a service user, we were often operating in an evidence vacuum. Our conversations with professionals suggest that this problem is common to other parts of the mental health space, so creating a new source of data and evidence could be highly valuable.
Overview of the cost-effectiveness model
I referred earlier to “direct-results thinking” (as opposed to hits-based thinking). This refers to direct interventions having relatively immediate effects, which can be best assessed with a cost-effectiveness model.
The model that I have built incorporates the expected costs of running the bot and the expected improvements in the wellbeing of the users.
The model tries to envisage a medium-term future state for the bot (rather than, e.g., what the project will look like immediately after funding it).
The decision criterion for the modelled considerations is that the bot’s cost-effectiveness should be competitive with StrongMinds. (Note that the unmodelled considerations may also be material)
Modelled Results of the cost-effectiveness model
The realistic assumption-set for the bot does come out with an answer that is (coincidentally) similar to the benchmark (StrongMinds).
Optimistic and pessimistic assumption-sets give outputs that are substantially better than / worse than StrongMinds.

The model also explores alternative scenarios:
If we negotiate support from Google, then the bot substantially outperforms StrongMinds (by a factor of 6.8). Other ways of sourcing users may have a similar effect.
If we use a different assumption for how to convert between different impact measurement scales, then the bot substantially outperforms StrongMinds (by a factor of 4.4)
If we use a different assumption for how to convert between interventions of different durations, then the bot outperforms StrongMinds (by a factor of 2.1)
If we make different assumptions about the counterfactual, we may conclude that the bot underperforms StrongMinds, potentially materially (although it’s hard to say how much; see separate appendix on this topic)

My interpretation of these findings is that the model’s estimates of the bot’s effectiveness are in the same ballpark as StrongMinds, assuming we accept the model’s assumptions.
The model can be found here.
Key assumptions underlying the model
Interested readers are invited to review the appendices which set out the assumptions in some detail.
A key feature is that the model sets out a medium term future state for the bot, after some improvements have been made. These assumptions introduce risks, however for a donor with appetite for risk and a general willingness to support promising early-stage/startup projects, this need not be an issue.
If I were to pick one assumption which I think is mostly likely to materially change the conclusions, it would be the assumption about the counterfactual. This is discussed in its own appendix. This assumption is likely to be favourable to the bot’s cost-effectiveness, and it’s unclear how much. If you were to fund this project, you would have to do so on one of the following bases:
You have comfort about the counterfactuals and therefore you support the development of the bot based on “direct-results thinking” alone
This might be because you buy the arguments set out in the appendix about why the counterfactuals are not a worry for the way the bot is currently implemented (via Google ads)...
Or because the overall shortage of mental health resources (globally) seems to increase the probability that the project will find new contexts which *do* have favourable counterfactuals.
A belief that the unmodelled factors are materially favourable, such as the potential to improve the evidence base for certain types of therapy (“hits-based thinking”)
Unmodelled arguments for and against funding the bot
This section refers to factors which aren’t reflected in the model.
For
Potential to revolutionise the psychology evidence base?
The bot creates a valuable dataset
With more scale, the dataset can be used to answer questions like “If a patient/client/user says something like X, what sort of responses are more or less effective at helping them?”
There is currently a shortage of data and evidence at this level of granularity
It could also provide more evidence for certain types of therapeutic intervention which are currently underevidenced.
This is explored in more detail in Appendix 3
The TIO chatbot’s free-text-heavy interface is distinctive and may allow for many other therapeutic approaches in the future
The conversational interface allows lots of freedom in terms of what the user can say, like an actual conversation.
This is highly unusual compared to other mental health apps, which are generally much more structured than TIO
While the approach is currently focused on a specific therapeutic approach (an approach inspired the Samaritans listening approach, which has similarities to Rogerian therapy), other approaches may be possible in the future
Good feedback loops and low “goodharting” risk
Goodharting risk refers to the risk that the immediately available measures are poor representatives for the ultimate impacts that we care about. (Examples include hospitals optimising for shorter waiting times rather than health, or schools optimising for good exam results rather than good education.)
This project does not have zero goodharting risk (are we sure that self-reported wellbeing really is the “right” ultimate goal?) However the goodharting risk is low by comparison with most other charitable projects
It also has quick feedback loops, which mean that it’s easier to optimise for the things the project is trying to achieve
Low hanging fruit
At the moment the project is making good progress given that it is volunteer-run
However there are easy improvements to the bot which could be made with a bit of funding
Project has existing tech and experience
Unlike a project starting from scratch, this project has experience in creating multiple variants of this bot, and a substantial dataset of c10,000 conversations
The existing team includes almost 40 years of Samaritans listening experience + other psychology backgrounds
Good connections with volunteers
The founding team is well-connected with groups which could supply volunteers to support the work of the project; indeed this project has been wholly volunteer-run thus far
A partly volunteer-run project could create cost-effectiveness advantages
Against
Questionable evidence base for underlying therapeutic approach
This bot has departed from many other mental health apps by not using CBT (CBT is commonly used in the mental health app space).
Instead it’s based on the approach used by Samaritans. While Samaritans is well-established, the evidence base for the Samaritans approach is not strong, and substantially less strong than CBT
Part of my motivation was to improve the evidence base, and having seen the results thus far, I have more faith in the bot’s approach, although more work to strengthen the evidence base would be valuable
Counterfactuals: would someone else have created a similar app?
While the approach taken by *this* chatbot is distinctive, the space of mental health apps is quite busy.
Perhaps someone else would (eventually) have come up with a similar idea
I believe that our team can be better than the average team who would work on this, because we are naturals at being evidence-based. However I’m biased.
Language may put a limit on scalability
Currently, if someone wants to build a mechanism for the bot to detect what the user has said, they need (a) a careful understanding of how to respond empathetically and (b) a nuanced understanding of the language you are speaking in
Currently, to make this bot work in a different language would not be a simple task
This is important, as mental health needs in the global south are substantial and neglected
Note that further investments in AI may invalidate this concern (not fully investigated)
Research goals may be ambitious
The need around more evidence for certain types of therapeutic intervention is well-established. However it’s unclear how useful it is to extrapolate evidence from a bot and apply it to a human-to-human intervention
Even if this evidence is (at least partly) relevant, we don’t yet know whether the scientific community is ready to accept such evidence
Realistically, I don’t expect we will see hard results (e.g. published research papers) for some years, and outcomes with a longer time period between the time when funding is provided and the outcome occurs carry more risk
How would extra funds be used?
At first the most pressing needs are around:
A specialist with NLP (Natural Language Processing) skills
More frontend skills, especially design and UX
A strong frontend developer, preferably with full stack skills
A rigorous evaluation of the bot
More google ads
The purpose of this post is to gather feedback on whether the project has sufficient potential to warrant funding it (which is a high-level question), so for brevity this section does not set out a detailed budget.
Volunteering opportunities
We currently would benefit from the following types of volunteer:
Front-end graphic design and UX volunteer
Skills needed: experience in graphic design and UX
Could be split into two roles
Front-end developer
Skills needed: confidence with javascript, html, css
Familiarity with how the front end interacts with the backend via the Python Flask framework would be a bonus
Back-end developer
Skills needed: familiarity with Python
NLP or AI knowledge desirable
Psychology advisor
Required background: professional, qualified psychologist or psychiatrist, preferably with plenty of past/ongoing clinical experience, preferably with a Rogerian background
Psychology research advisor
Required background: academic assessing psychological interventions, preferably with experience of assessing hard-to-assess interventions such as Rogerian or existential therapies
Our existing team and/or the people we are talking to do already cover all of these areas to a certain degree, however further help is needed on all of these fronts.
Appendices
The appendices are in the following sections:
More info about how the bot works
How this bot might revolutionise the evidence base for some therapies
History of the bot
More details of the cost-effectiveness modelling
Overview of other mental health apps
Appendix 1a: How the bot works
The bot sources its users via google ads from people who are searching for things like “I’m feeling depressed”.
The bot starts by asking users how they feel on a scale from 1 to 10 (see later appendix about impact measures for more on how this question is worded)
The bot starts to initiate the conversation (to give users a little feel of what to expect)
The bot explains some things (e.g. making sure that the user knows that they are talking to a bot, not a human, gives them a choice about whether we can use their conversation data, and asks the user to say how they feel at the end too)
The bot enters the main (or free text) section, where the user explores their feelings. In the original prototype (or “MVP”) of the bot, the responses were all simple generic responses saying something like “I hear you”, “I’m listening”, etc. This simple bot generated a net positive impact on users. The bot is now much more sophisticated: several more tailored responses are programmed in. And where a tailored response isn’t found, the fallback is to use a generic response.
The user clicks on a button (or something slightly different depending on the front end) to indicate that the conversation is at an end, and they say how they’re feeling at the end, and have an opportunity to give feedback
The philosophy behind how the bot chooses its responses can be summarised as follows:
The bot is humble: it doesn’t claim to know more about the user’s life than the user does
The bot is non-judgemental
The bot is honest: e.g. the bot not only tells users that they are talking to a bot, but users have to click on something which says “I will talk to you even though you are a simple bot” to make sure there is no ambiguity
The bot respects users’ wishes around data privacy: the bot spends some time carefully explaining the choices the user has (i.e. totally confidential—nobody ever sees what they wrote or anonymous—our “boffins” can see the user’s words, but we don’t know who they are)
The bot gives empathetic responses
The bot doesn’t try to diminish what the user says (e.g. by telling them that they should just cheer up, or everything is all OK really)
The bot aims to achieve change in the user’s emotional state by letting the user express what’s on their mind
Allowing the user to express what’s on their mind includes allowing them to express things that they cannot express to people in their lives (such as their suicidal thoughts). The bot may explain that (e.g.) it is only a simple bot and therefore unable to call an ambulance for you, however it won’t get shocked or scared by users talking about suicide.
The bot does not guide the user to change the world around the user (e.g. by providing the user with advice on what they should do). Instead the bot provides a space where the user can be listened to. If this leads to the user feeling emotionally better, and then choosing to make their own decisions about what they should do next, then so much the better.
If you want to get a feel for what the bot is like, here are some recordings of the bot:
TIO example conversation using blue/grey frontend
TIO example conversation using bootstrap frontend
TIO example conversation using Guided Track frontend
You are also welcome to interact with the chatbot, however note that the bot’s responses are geared towards *actual* users; people who aren’t in emotional need at the time of using the bot are likely to have a more disappointing experience. Here’s a link. Note that this is a test version of the bot because I want to avoid contaminating our data with testing users. However if you are genuinely feeling low (i.e. you are a “genuine” user of the service) then you are welcome to use the bot here.
Appendix 1b: Does the bot use AI?
Depends on what you mean by AI.
The bot doesn’t use machine learning, and we have a certain nervousness about incorporating a “black box” with poor explainability.
We instead are currently using a form of pattern matching where the bot looks for certain strings of text in the user’s message (this description somewhat simplifies the reality).
At time of writing we are investigating “Natural Language Processing” (NLP) libraries, such as NLTK and Spacy. We are currently expecting to ramp up the amount of AI we use.
Under some definitions of AI, even relatively simple chatbots count as AI, so this chatbot would certainly count as AI under those definitions.
Appendix 1c: Summary of impact scores
The impact scores shown here are calculated as:
How the user was feeling on a scale from 1 to 10 at the end of the conversation
Minus
How the user was feeling on a scale from 1 to 10 at the start of the conversation
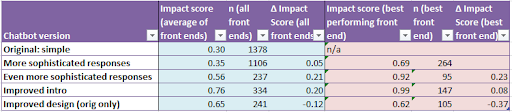
Total number of users is >10,000, but not all users state how they feel at the end, so the number of datapoints (n) feeding into the above table is only c3300.
The first two rows relate to time periods when the team was smaller, so we acted more slowly. Hence the larger sample sizes.
The bot has three front ends. The blue section shows the scores relating to the overall picture (i.e. a combination of all three front ends). The pale red section shows the best performing front end.
The story apparently being told in the above table is that each of the above changes improved the bot, but the last change (improving the design) was a step backwards. However we performed some statistical analysis, and we can’t be confident that this story is correct.
What we can say with confidence: the bot does better than a null hypothesis of zero impact (p-values steadily below 1%, and often many orders of magnitude below 1% for a t-test)
What we can’t say with confidence: we don’t know whether a bot version on one row really is better or worse than the previous row; p-values on a two-sample t-test comparing one row of the above table with the previous row are consistently disappointing (normally >10%).
The main thing holding us back is money: getting larger sample sizes involves paying for more google ads; if we could do this we would be able to draw inferences more effectively.
Appendix 1d: How good are these impact scores?
The changes in happiness scores in the above table are mostly in the range 0.3 out of 10 (for the earliest prototype) to 0.99 out of 10.
Is this big or small?
If we look at this EA Forum post by Michael Plant, it seems, at first glance, that the bot’s impacts are moderately big. The table suggests that achieving changes as large as 1 point or more on a scale from 1 to 10 is difficult. The table shows that a physical illness has an impact of 0.22 out of 10, and having depression has an impact of 0.72 out of 10. However note that the question wording was different, so it doesn’t necessarily mean that those are on a like-for-like basis.
(Thank you to Michael for directing me to this in the call I had with him on the topic)
Using a more statistical approach to answering the question finds that the Cohen’s d typically falls in the range 0.2 to 0.5. Cohen’s d is a measure which compares the outcome with the standard deviation. A Cohen’s d of 0.2 typically indicates a modest effect size; a Cohen’s d of 0.5 indicates a medium effect size, and Cohen’s d of 0.8 indicates a large effect size.
Appendix 1e: Distribution of responses to the bot
Users’ responses to the bot experience are varied.
The below is an example histogram showing the users’ impact scores (i.e. final score minus initial score) for one variant of the bot.
If we ignore the big dollop of users whose impact score is zero out of 10, the shape seems to indicate a roughly symmetrical distribution centred roughly around 1 out of 10.
Note that the big dollop of zero scores may be linked to the fact that the question wording “leads” or “anchors” the user towards a zero score (see separate appendix about the impact measures for more on this).
There are also a few extreme values, with more positive extreme values than negatives.
I have read all of the conversations which have happened between users and the bot (that the users have been willing to share). I synthesise here my impressions based on those conversations and the feedback provided.
Extremely positive reactions:
The bot allows users to express things that they wouldn’t feel able to say to any human
The bot creates a sense of “safety” which doesn’t apply in contexts which apply more social pressure, such as interacting with another human
It appears that knowing *exactly* what happens with the data is probably important
The “on-demand” nature of the bot seemed relevant (this more my inference than something said explicitly)
Users sometimes express surprise that the conversation with the bot is as therapeutic as it is
A surprisingly large number of users described the bot with superlative terms such as “it’s perfect” and “don’t change anything about it!”
The most positive reactions often seemed to involve some element of (conscious) Eliza effect
Neutral to mildly positive reactions:
These seemed to include some features of the more positive and the more negative reactions
Some comments noted that the bot is imperfect, but better than nothing (mirroring our thinking when we set up the project)
Users often asked for more sophistication in the bot’s responses (especially earlier when the bot’s responses were extremely unsophisticated)
Negative reactions:
Some reactions were negative about the fact that the user was talking to a bot, arguing that they could never get the support they need without speaking a human
Relatedly, some users felt that talking to a bot just highlighted how lonely they were
Others thought that the bot was too simplistic
Some users had responses that were familiar from the Samaritans context, including disappointment at not receiving advice, and the idea that expressing your feelings could actually be unhelpful
Appendix 1f: Impact measures: the “happiness” question
To assess our impact, we ask the user how they feel at the start and at the end of the conversation
At the start of the conversation, the bot asks the user:
“Please rate how you feel on a scale from 1 to 10, where 1 is terrible and 10 is great”
When the user initiates the final feedback question, they see this text:
“Thank you for using this bot. Please rate how you feel on a scale from 1 to 10, where 1 is terrible and 10 is great. As a reminder, the score you gave at the start was <INITIAL_SCORE>”
Considerations:
Is the anchoring effect desirable?
The wording in the final question reminds the user which score they gave at the start
I suspect this is probably good—it means that if the user really is feeling better/worse than they felt before, then they can calibrate their answer accordingly
However you could argue the contrary: maybe a purer and better answer would be given if the answer were given without anchoring?
Consistency with other research
As my years of experience in research have taught me, people can be surprisingly responsive to the smallest details of how a question is worded
For comparability across different research, it’s preferable to use consistent wording
An early prototype tried using the same wording used by Samaritans in their research. However because the Samaritans research has been delivered verbally as part of a phone call, there wasn’t a single/canonical wording. However I tried using wording that followed the same approach. Recent Samaritans studies have used a distress scale where distress was rated on a scale of 0-10 (0= no distress, 5= moderate distress and 10= extreme distress)
When I implemented this, I found that there was often a surprisingly low amount of distress for some users, which seemed to indicate that users were getting confused and thinking that 10 out of 10 is good and 0 out of 10 is bad.
Hence the bot now uses a different wording.
I didn’t find another wording used by another group which works this way round (and is only one question long)
Consistency with what we’ve done before
Now that we have had over 10,000 users, if we were to change the wording of our question, it would be a significant departure from what we’ve done before, and would have implications for comparability.
Appendix 2: How this bot might revolutionise the evidence base
The source for much of this section is conversations with existing professional psychiatrists/psychologists.
Currently some psychological interventions are substantially better evidenced than others.
E.g. CBT (Cognitive Behavioural Therapy) has a really strong evidence base
Other therapeutic approaches such as Rogerian or Existential therapies don’t have a strong evidence base
Most psychologists would not argue that we should therefore dismiss these poorly evidenced approaches.
Instead the shortage of evidence reflects the fact that this sort of therapy typically doesn’t have a clearly defined “playbook” of what the therapist says.
Part of the aim of this project is to address this in two ways:
Providing a uniform intervention that can be assessed at scale
Example: imagine a totally uniform intervention (such as giving patients a prozac pill, which is totally consistent from one pill to the next)
A totally uniform intervention (like Prozac) is easier to assess
Some therapeutic approaches (like CBT) are closer to being uniform (although, depending on how you implement them, sometimes CBT can be more or less uniform)
Others, like Rogerian or existential therapies, are highly non-uniform—they don’t have a clear “playbook”
This means that we don’t have good evidence around the effectiveness of these sorts of therapy
This chatbot project aims to implement a form of Rogerian-esque therapy that *is* uniform, allowing assessment at scale
Allowing an experimental/scientific approach which could provide an evidence base for therapists
At the moment, there is a shortage of evidence about *specifically* to say in a given context
To take an example which would be controversial within Samaritans:
Imagine that a service user is talking about some health issues. Consider the following possible responses that could be said by a therapist/listening volunteer
“You must recognise that these health issues might be serious. Please make sure you go to see a doctor. Will you do that for me please?”
“How would you feel about seeing a doctor?”
“How are you feeling about the health issues you’ve described?”
In a Samaritans context, the first of these would most likely be considered overly directive, the third would likely be considered “safe” (at least with regard to the risk of being overly directive), and the middle option would be controversial.
Currently, these debates operate in an evidence vacuum
Adding evidence to the debate need not necessarily fully resolve the debate, but would almost certainly take the debate forward.
I believe that this benefit on its own may be sufficient to justify funding the project (i.e. even if there were no short term benefit). This reflects the fact that other, better-evidenced interventions don’t work for everyone (e.g. CBT might be great for person A, but ineffective for person B), which means that CBT can’t solve the mental health problem on its own, so we need more evidence on more types of therapy.
Crucially, TIO is fundamentally different from other mental health apps—it has a free-form conversational interface, similar to an actual conversation (unlike other apps which either don’t have any conversational interface at all, or have a fairly restricted/”guided” conversational capability). This means that TIO is uniquely well-positioned to achieve this goal.
Note that there is still plenty of work needed before the bot can make this sort of contribution to the evidence base. Specifically, a number of other mental health apps have been subjected to rigorous evaluations published in journals, whereas TIO—still an early-stage project—has not.
Appendix 3: History of the bot
2018: I created the first prototype, which was called the Feelings Feline. The bot took on the persona of a cat. This was partly to explain to the user why the bot’s responses were simplistic, and also because of anecdotal evidence of the therapeutic value of conversations with pets. User feedback suggested that with the incredibly basic design used, this didn’t work. I suspect that with more care, this could be a success, however it would need better design expertise than I had at the time (and I had almost zero design expertise at the time).
Feedback was slow at this stage. Because of a lack of technical expertise, there was no mechanism for gathering feedback (although this is straightforward to develop for any full stack web developer). However another glitch in the process did (accidentally) lead to feedback. The glitch was because of an unforeseen feature of wix websites. Wix is an online service that allows people to create websites. I had created a wix website to explain the concept of the bot. It then pointed to another website which I had programmed in javascript. However wix automatically includes a chat interface in its websites (which doesn’t show up in the preview, so I didn’t know it existed when I launched the site) . This led to confusion—many users started talking to a chat interface which I hadn’t programmed and didn’t even know existed! This led to a number of messages coming through to my inbox. I responded to them—I felt I had to because many of them expressed great distress. In the course of the conversations, I explained about the chatbot (again, I had to, to clear up the confusion). Although this was not the intention, it meant that some users gave me their thoughts about the website, and some of those did so in a fairly high-quality “qualitative research” way. Once I worked out what was going on, I cleared up the website confusion, and the high quality feedback stopped.
2019: Another EA (Peter Brietbart) was working on another mental health app; he introduced me to Guided Track. Huge thanks to Peter Brietbart for doing this; it was incredibly useful. I can’t understate how helpful Peter was. Guided Track provided a solution to the problems around gathering feedback, all through a clean, professional-looking front-end, together with an incredibly easy to program back-end.
By this stage, the team consisted of me and two other people that I had recruited through my network of Samaritans volunteers.
2020: The team has now grown further, including some non-Samaritan volunteers. My attempts to recruit volunteers who are expert on UX (user experience) and design have not been successful. We also have a stronger network of people with a psychology background and have surpassed 10,000 users.
Appendix 4a: Detailed description of assumptions in cost effectiveness model
This section runs through each of the assumptions in the cost effectiveness model.
Fixed costs per annum: Based on having seen the budgets of some early stage tech startups, the numbers used in the model seem like a reasonable budget for something moderately early stage with relatively uncomplicated tech. Actually, the tech may be complicated, but there’s the offsetting advantage that lots of the work has already been done. Note also that this is intended as a slightly mid-term assumption, rather than a budget for the first year.
Variable costs, per user: The optimistic budget of $0.14 comes from actual past experience (we have had periods of spending £0.11 per user; although currently we are relying on free ads from a charity). Cost per click (CPC) seems unlikely to get much higher than $2 (this is also the upper bound that is enforced under Google for nonprofits). The model also assumes that costs won’t increase materially from operating at scale because of high unmet demand for help from those feeling low. The costs should be kept down somewhat by sourcing some of the ads via a charity entity.
No of users per annum: Reaching the pessimistic figure of 50,000 users via google ads does not seem difficult:
The bot is currently getting c 60 users per day (i.e. c20,000 per annum) using just free ads via google for nonprofits
Google for nonprofits is highly restrictive, including a number of arbitrary restrictions. If we supplement this with paid ads, we should expect many more users
The bot was receiving almost as many ads previously when we used paid ads at a rate of £3 per day, and this was limited to the UK only, and we still had plenty of room for more funding.
Expanding geographically to other English-speaking geographies will allow much more scale
My intuition that we can reach many more people comes from the impression that mental health issues are widespread, that people feel able to enter search queries into google when they might not be willing to ask their closest friends, and that this trend is growing. Hence an optimistic assumption which is substantially larger (50 million), which doesn’t seem unreasonable given that 450 million people around the world suffer from mental health issues (source: WHO) And I chose a realistic assumption equal to the geometric mean of the pessimistic and optimistic.
However in case the assumptions about scale were overoptimistic, I tried tweaking the realistic assumption so that the no of users was substantially lower (only 200,000) and it didn’t change the conclusion at the bottom of the table.
Total cost, per user: Calc
Benchmark improvement in “happiness” on 27 point scale (PHQ-9): Several past StrongMinds reports (e.g. this one) show an average improvement in PHQ-9 of 13 points (see bottom of page 2)
Benchmark duration in “happiness” improvement (years): StrongMinds reports indicate that they test again after 6 months. If some people have been checked after 6 months, how long should we assume that the improvement lasts? A reasonable assumption is that it will last for another 6 months after that, so 1 year in total.
Benchmark Cost per patient: StrongMinds tracks their cost per patient, and for the most recent report pre-COVID, this came to $153 for the StrongMinds-led groups, and $66 for the peer-led groups (i.e. the groups where a past graduate of their groups runs a new group, rather than a StrongMinds staff member). We then divided this by 75%, because we want the cost per patient actually cured of depression, and 75% is the StrongMinds target.
TIO: Improvement in self-reported “happiness” on 1-10 scale: Pessimistic score of 0.9 comes from assuming that we simply take the current bot, focus on the best-performing front-end, perhaps back out the recent design changes if necessary, and then we have a bot which seems to be generating 0.99 (see scores noted earlier). If, in addition, we give credit to future targeting of users and future improvements in the bot, we should expect the impact score to be higher. The 2.8 assumption comes from taking the data from the current bot and taking the average of positive scores (i.e. assume that we can effectively target users who will benefit, but assume no further improvements in the bot’s effectiveness). To choose an optimistic figure, I calculated the number such that 2.8 would be the geometric mean—this came to 8.7, which I thought was too high, so I nudged it down to 7.
TIO: duration of improvement (days) -- for a single usage of the bot: We know that some people feel better after using the bot, but we don’t know how long this will persist. In the absence of evidence, this is really a matter of guesswork. All the more so, since my impression from having read the conversations is that the extent to which the effect persists probably varies. The assumptions chosen here were between a few hours (i.e. quarter of a day) to a week. The realistic assumption is the geometric mean of the optimistic and pessimistic.
TIO: proportion of “reusers”; i.e. those who reuse the bot: Thus far, there have already been some instances of users indicating that they have liked the experience of using the bot and they will bookmark the site and come back and use it again, and we have currently made no effort to encourage this. It therefore seems reasonable to believe that if we tried to encourage this more, it would happen more, and this would improve the cost-effectiveness (because we wouldn’t have to pay for more google ads, and the google ads are a material part of the cost base under the medium term scenario). However we also need to manage a careful balance between three things: (a) reuse is potentially good for a user and good for the project’s cost-effectiveness (b) dependency management (c) user privacy. Dependency here refers to the risk (for which there is precedent) that users of such services can develop an unhealthy relationship with the service, almost akin to an addiction. We have not yet thought through how to manage this.
TIO: assumed duration of continuing to use the bot for reusers (months): On this point we are operating in the absence of data, so the duration has been estimated as anywhere between 2 weeks (pessimistic) through to 1 year (optimistic; although there is no in-principle reason why the benefits could not persist for longer). The central assumption of 3 months was chosen as a rounded geometric mean of the optimistic and pessimistic scenarios.
TIO: no of happiness-point-years: Calculated as the proportion of users who single users x the duration of impact for a single usage + proportion of users who reusers x duration of continuing to use the bot. This includes the assumption that if someone is a multiple user, then the happiness improvement persists throughout the duration of their reuse period. This is a generous assumption (although no more generous than the assumption being made in the benchmark). On the other hand, the reusers are assumed to have the same happiness improvement as single users, which is a very harsh assumption given that users have varied reactions to the bot, and those who are least keen on the bot seem less likely to reuse it.
TIO: cost per happiness-point-year: Calc
Decision criterion: Should we fund TIO? In the row in yellow labelled “Should we fund TIO?” there is a formula which determines whether the answer is “Yes”, “No”, or “Tentative yes”. Tentative yes is chosen if the two cost-effectiveness figures are close to each other, which is defined (somewhat arbitrarily) as being within a factor of 2 of each other. This is to reflect the fact that if the cost effectiveness comes out at a number close to the benchmark, then we should be nervous because the model depends on a number of assumptions.
(Note that the comparison here is against the standard StrongMinds intervention, not the StrongMinds chatbot.)
Optimistic and pessimistic assumptions:
I did not try to carefully calibrate the probabilities around the optimistic and pessimistic scenarios, however they are probably something like a 75%-90% confidence interval for each assumption.
Note further most of the assumptions are essentially independent of each other, meaning that a scenario as extreme as the optimistic or pessimistic scenario is much more severe than a 90% confidence interval if we are looking at the overall scenario.
Having said that, the main aim of including those scenarios was to highlight the fact that the model is based on a number of uncertain assumptions about the future, and specifically that the uncertainty is sufficient to make the difference between being close to the benchmark and being really quite far from the benchmark (in either direction)
Appendix 4b: PHQ-9 to 1-10 conversion
This bot measures its effectiveness based on a scale from 1 to 10. The comparator (StrongMinds) uses a well-established standard metric, which is PHQ-9. PHQ-9 is described in more detail in a separate appendix.
The calculation used in the base scenario of the model is to take the 13-point movement in the 27-point PHQ-9 scale and simply rescale it.
This is overly simplistic. As can be seen from the separate appendix about PHQ-9, PHQ-9 assesses several very different things, and is constructed in a different way, so a straight rescaling isn’t likely to constitute an effective translation between the two measures.
To take another data point, this post by Michael Plant of the Happier Lives Institute suggests that the effect of curing someone’s depression appears to be 0.72 on a 1-10 scale, using data that come from Clark et al. The chatbot cost-effectiveness model includes an alternative scenario which uses this conversion between different impact scales, and it suggests that the chatbot (TIO) outperforms the benchmark by quite a substantial benchmark under this assumption.
To a certain extent this may seem worrying—the output figures move quite considerably in response to an uncertain assumption. However I believe I have used a fairly conservative assumption in the base scenario, which may give us some comfort.
Appendix 4c: Time conversion
The cost-effectiveness model compares interventions with different durations.
Let’s assume that a hypothetical short term intervention improves user wellbeing for 1 day (say).
Let’s assume that a hypothetical long term intervention improves user wellbeing for one year (say)
And assume that the extent of the wellbeing improvement is the same
Should we say that the intervention which lasts 365 times as long is 365 times more valuable? (let’s call this the time-smoothing assumption)
I raised a question about this on the Effective Altruism, Mental Health, and Happiness facebook group. (I suspect you may need to be a member of the group to read it.) It raised some discussion, but no conclusive answers.
In the cost-effectiveness model I’ve used what I call the time-smoothing assumption.
It’s possible that the time-smoothing assumption is too harsh on the bot (or equivalently too generous to the longer-term intervention). After all, if someone’s depression is improved after the StrongMinds intervention, it seems unrealistic to believe that the patient’s wellbeing will be consistently, uninterruptedly improved for a year. That said, it also seems unrealistic to believe that the chatbot will *always* cause the user to feel *consistently* better for a full day (or whichever assumption we are using), however in a short time period there is less scope for variance.
The cost-effectiveness model includes an alternative scenario which explores this by applying a somewhat arbitrarily chosen factor of 2 to reflect the possibility that the time-smoothing assumption used in the base case is too harsh on TIO.
However my overall conclusion on this section is that the topic is difficult, and remains, to my mind, an area of uncertainty.
Appendix 4d: “Support from google” scenario
The cost-effectiveness model includes a “Support from Google” scenario
At the last general meeting of the chatbot team, it was suggested that Google may be willing to support a project such as this, and specifically that this sort of project would appeal to Google sufficiently that they might be willing to support the project above and beyond their existing google for nonprofits programme. I have not done any work to verify whether this is realistic.
There is a scenario in the cost-effectiveness model for the project receiving this support from Google, which involves setting the google ads costs to zero.
I would only consider this legitimate if there were sufficiently favourable counterfactuals.
If the Google support came from the same source as Google donations to GiveDirectly, for example, then I’d worry that the counterfactuals on that money might be quite good outcomes, and I should still treat the money as a cost within the model
If the Google support were ultimately a reduction in profits to shareholders, this would likely be a much smaller opportunity cost because of diminishing marginal returns, and therefore it would be reasonable for the model to not treat the google ad costs as a “real” cost
Appendix 4e: Counterfactuals
For impact scores we have gathered thus far, we have assumed that the counterfactual is zero impact.
This section explores this assumption, and concludes that with regard to the current mechanism for reaching users (via Google ads) the assumption might be generous. However, the bot’s ultimate impact is not limited to the current mechanism of reaching users, and given that mental health is, in general, undersupplied, it’s reasonable to believe that other contexts with better counterfactuals may arise.
Here’s how it works at the moment:
The user journey starts with someone googling “I’m feeling depressed” or similar
Our google ads appear, and some people will click on those ads
If those ads had not been there what would have happened instead?
To explore this, I have tried googling “I’m feeling depressed”, and the search results include advice from the NHS, websites providing advice on depression, and similar. (note that one complication is that search results are not totally uniform from one user to the next)
The content of those websites seems fine, however I’ve heard comments from people saying things like
“I don’t have the capacity to read through a long website like that—not having the emotional resources to do that is exactly what it means to be depressed!”
“The advice on those websites is all obvious. I *know* I’m supposed to eat healthy, get exercise, do mindfulness, get enough sleep etc. It’s not *knowing* what to do, it’s actually *doing* it that’s hard!”
Which suggests that those websites aren’t succeeding in actually making people happier. Hence the zero impact assumption.
However, these impressions are *not* based on careful studies. Specifically, I’m gathering these impressions from people who have ended up talking to me in some role in which I’m providing volunteer support to people who are feeling low. In such a context, there’s a risk of selection effects: maybe the people who found such websites useful get help and therefore don’t end up needing my support?
Some important observations about counterfactuals in the specific context of sourcing users from Google ads:
Assessing counterfactuals is hard (in general, and in this case in particular)
As the resources in the google search results seem credible, it seems unlikely that the counterfactual outcome would actually be *harmful*
So the assumption of zero impact used in the model errs on the side of being favourable to the chatbot’s cost-effectiveness
This is all the more worrying, as the effect size of the bot is unclear, but (at least based on the Cohen’s d measure) is currently often small (or at best medium). (Although it might be larger in the future, and looks larger based on other ways of assessing this—see separate appendix about this)
Note that the comparator (StrongMinds) does clearly have favourable counterfactuals (poor women in sub-Saharan Africa almost certainly *wouldn’t* get access to decent support without StrongMinds)
While the counterfactuals appear to raise some material doubts within the Google ads context, the ultimate impact of the project need not be tied solely to that context
Just because the project currently sources users from Google ads, it doesn’t mean that it will only ever source users from Google ads.
Specifically, future expansion to the developing world may have counterfactuals which are more favourable to this project (assuming that the AI techniques can adapt across languages).
Ultimately, however, the overall/global undersupply of mental health services is relevant. Even if we don’t know now exactly where the project will reach users with favourable counterfactuals, the fact that mental health services are undersupplied increases the probability that such places can be found.
However this is speculative.
Appendix 4f: About PHQ-9
This is what a standard PHQ-9 questionnaire looks like:
There are 9 questions, and a score out of 27 is generated by assigning a score of 0 for each tick in the first column, a score of 1 for each tick in the second column, a score of 2 for each tick in the third column and a score of 3 for each tick in the fourth column, and then adding the scores up.
It is a standard tool for monitoring the severity of depression and response to treatment.
Appendix 5: Other mental health apps
We are very much not the first people to think of providing mental health help via an app.
A list of about 15 or so other apps can be found here.
Types of therapeutic approaches used a lot:
CBT
Meditation
Approaches which don’t seem to come up often:
Psychodynamic
Rogerian
Existential
We appear to be taking an approach which is different from the existing mental health apps.
And yet if we look at attempts to solve the Turing test, an early attempt was a chatbot called Eliza, which was inspired by the Rogerian approach to therapy (which is also the approach which is closest to the Samaritans listening approach)
So it seemed surprising that people trying to solve the Turing test had tried to employ a Rogerian approach, but people trying to tackle mental health had not.
To our knowledge, we are the first project taking a Rogerian-inspired conversational app and applying it for mental health purposes.
On a related note, this project seems unusual in including a relatively free flowing conversational interface. While several other apps have a conversational or chatbot-like interface, these bots are normally constructed in a very structured way, meaning that most of the conversation has been predetermined. I.e. the bot sets the agenda, not the user. And in several apps, there is actually no free text fields at all.
We speculate that the reason for this is the more open conversational paradigm was too intimidating for other app developers, who perhaps felt that solving mental health *and* the Turing Test at the same time was too ambitious. Our approach is distinctive perhaps because of the fact that we were inspired by the Samaritans approach, which is relatively close to an MVP of a therapeutic approach.
The fact that our interface is so free flowing is important. It means that our bot’s approach is closest to actual real life therapy.
- What’s the effect size of therapy? (StrongMinds 3 of 9) by (8 Dec 2023 8:34 UTC; 61 points)
- Data Science for Effective Good + Call for Projects + Call for Volunteers by (9 Aug 2022 14:02 UTC; 47 points)
- Technology Non-Profits I could volunteer for? by (21 Oct 2020 0:56 UTC; 7 points)
- 's comment on Automated online suicide prevention: potentially high impact? by (26 Jul 2022 15:26 UTC; 4 points)
Hello Sanjay, thanks both for writing this up and actually having a go at building something! We did discuss this a few months ago but I can’t remember all the details of what we discussed.
First, is there a link to the bot so people can see it or use it? I can’t see one.
Second, my main question for you -sorry if I asked this before—is: what is the retention for the app? When people ask me about mental health tech, my main worry is not whether it might work if people used it, but whether people do want to use it, given the general rule that people try apps once or twice and then give up on them. If you build something people want to keep using and can provide that service cheaply, this would very likely be highly cost-effective.
I’m not sure it’s that useful to create a cost-effectiveness model based on the hypothetical scenario where people use the chatbot: the real challenge is to get people to use it. It’s a bit like me pitching a business to venture capitalists saying “if this works, it’ll be the next facebook”, to which they would say “sure, now tell us why you think it will be the next facebook”.
Third, I notice your worst-cast scenario is the effect lasts 0.5 years, but I’d expect using a chatbot to only make me feel better for a few minutes or hours, so unless people are using it many times, I’d expect the impact to be slight. Quick maths: a 1 point increase on a 0-10 happiness scale for 1 day is 0.003 happiness life-years.
Thank you very much for taking the time to have a look at this.
(1) For links to the bot, I recommend having a look at the end of Appendix 1a, where I provide links to the bot, but also explain that people who aren’t feeling low tend not to behave like real users, so it might be easier to look at one of the videos/recordings that we’ve made, which show some fictional conversations which are more realistic.
(2) Re retention, we have deliberately avoided measuring this, because we haven’t thought through whether that would count as being creepy with users’ data. We’ve also inherited some caution from my Samaritans experience, where we worry about “dependency” (i.e. people reusing the service so often that it almost becomes an addiction). So we have deliberately not tried to encourage reuse, nor measured how often it happens. We do however know that at least some users mention that they will bookmark the site and come back and reuse it. Given the lack of data, the model is pretty cautious in its assumptions—only 1.5% of users are assumed to reuse the site; everyone else is assumed to use it only once. Also, those users are not assumed to have a better experience, which is also conservative.
I believe your comments about hypotheticals and “this will be the next facebook” are based on a misunderstanding. This model is not based on the “hypothetical” scenario of people using the bot, it’s based on the scenario of people using the bot *in the same way the previous 10,000+ users have used the bot*. Thus far we have sourced users through a combination of free and paid-for Google ads, and, as described in Appendix 4a, the assumptions in the model are based on this past experience, adjusted for our expectations of how this will change in the future. The model gives no credit to the other ways that we might source users in the future (e.g. maybe we will aim for better retention, maybe we will source users from other referrals) -- those would be hypothetical scenarios, and since I had no data to base those off, I didn’t model them.
(3) I see that there is some confusion about the model, so I’ve added some links in the model to appendix 4a, so that it’s easier for people viewing the model to know where to look to find the explanations.
To respond to the specific points, the worst case scenario does *not* assume that the effect lasts 0.5 years. The worst case scenario assumes that the effect lasts a fraction of day (i.e. a matter of hours) for exactly 99.9% of users. For the remaining 0.1% of users, they are assumed to like it enough to reuse it for about a couple of weeks and then lose interest.
I very much appreciate you taking the time to have a look and provide comments. So sorry for the misunderstandings, let’s hope I’ve now made the model clear enough that future readers are able to follow it better.
Interesting idea, great to see such initiatives! My main attempt to contribute something is that I think I disagree about the way you seem to assume that this potentially would ‘revolutionise the psychology evidence base’.
I’m not sure if it’s helpful to think in terms of evidence base of an entire approach, instead of thinking diagnosis- or process-based. I mean, we do now a bit about what works for whom, and what doesn’t. One potential risk is assuming that an approach can never be harmful, which it can.
This is such a potential mechanism, it might be harmful for processes such as worrying or ruminating. If I understand the app correctly, I don’t think I would advise it for my patients with generalized anxiety disorder, or with dependent personality traits.
But a lot of Rogerian therapies would exclude quite some cases? Or there is at least a selection bias?
Thank you for your comment Kris.
I’m unclear why you are hesitant about the claim of the potential to revolutionise the psychology evidence base. I wonder if you perhaps inadvertently used a strawman of my argument by only reading the section which you quoted? This was not intended to support the claim about the bot’s potential to revolutionise the psychology evidence base.
Instead, it might be more helpful to refer to Appendix 2; I include a heavily abbreviated version here:
To expand on item (2), the idea is that when I, as someone who speaks to people in a therapeutic capacity, choose to say one thing (as opposed to another thing) there is no granular evidence about that specific thing I said. This feels all the more salient when being trained or training others, and dissecting the specific things said in a training role play. These discussions largely operate in an evidence vacuum.
The professionals that I’ve spoken to thus far have not yet been able to point me to evidence as granular as this.
If you know of any such evidence, please do let me know—it might help me to spend less time on this project, and I would also find that evidence very useful.
Thanks for your reply, I hope I’m not wasting your time.
But appendix 2 also seems to imply that the evidence base for CBT is for it as an approach in its entirety. What we think that works in a CBT protocol for depression is different than what we think that works in a CBT protocol for panic disorder (or OCD, or …). And there is data for which groups none of those protocols work.
In CBT that is mainly based on a functional analysis (or assumed processes), and that functional analysis would create the context in which specific things one would or wouldn’t say. This also provides context to how you would define ‘empathetic responses’.
(There is a paper from 1966 claiming that Rogers probably also used implicit functional analyses to ‘decide’ to what extent he would or wouldn’t reinforce certain (mal)adaptive behaviors, just to show how old this discussion is. The bot might generate very interesting results to contribute to that discussion!)
Would you consider evidence that a specific diagnosis-aimed CBT protocol works better than a general CBT protocol for a specific group as relevant to the claim that there is evidence about which reactions (sentences) would or wouldn’t work (for whom)?
So I just can’t imagine revolutionizing the evidence base for psychological treatments using a ‘uniform’ approach (and thus without taking characteristics of the person into account), but maybe I don’t get how diverse this bot is. I just interacted a bit with the test version, and it supported my hypothesis about it potentially being (a bit) harmful to certain groups of people. (*edit* you seem to anticipate on this but not encouraging re-use). But still great for most people!
Thanks very much Kris, I’m very pleased that you’re interested in this enough to write these comments.
And as you’re pointing out, I didn’t respond to your earlier point about talking about the evidence base for an entire approach, as opposed to (e.g.) an approach applied to a specific diagnosis.
The claim that the “evidence base for CBT” is stronger than the “evidence base for Rogerian therapy” came from psychologists/psychiatrists who were using a bit of a shorthand—i.e. I think they really mean something like “if we look at the evidence base for CBT as applied to X for lots of values of X, compared to the evidence base for Rogerian therapy as applied to X for lots of values of X, the evidence base for the latter is more likely to have gaps for lots of values of X, and more likely to have poorer quality evidence if it’s not totally missing”.
It’s worth noting that while the current assessment mechanism is the question described in Appendix 1f, this is, as alluded to, not the only question that could be asked, and it’s also possible for the bot to incorporate other standard assessment approaches (PHQ9, GAD7, or whatever) and adapt accordingly.
Having said that, I’d say that this on its own doesn’t feel revolutionary to me. What really does seem revolutionary is that, with the right scale, I might be able to say: This client said XYZ to me, if I had responded with ABC or DEF, which of those would have given me a better response, and be able to test something as granular as that and get a non-tiny sample size.