whoops, thanks, fixed
OscarD🔸
Karma: 2,269
Is AI welfare work puntable?
Good point. According to this manifold market an IPO within the next year is ~75% likely.
Fun! (the url at the top points to the /birds rather than /music page by mistake)
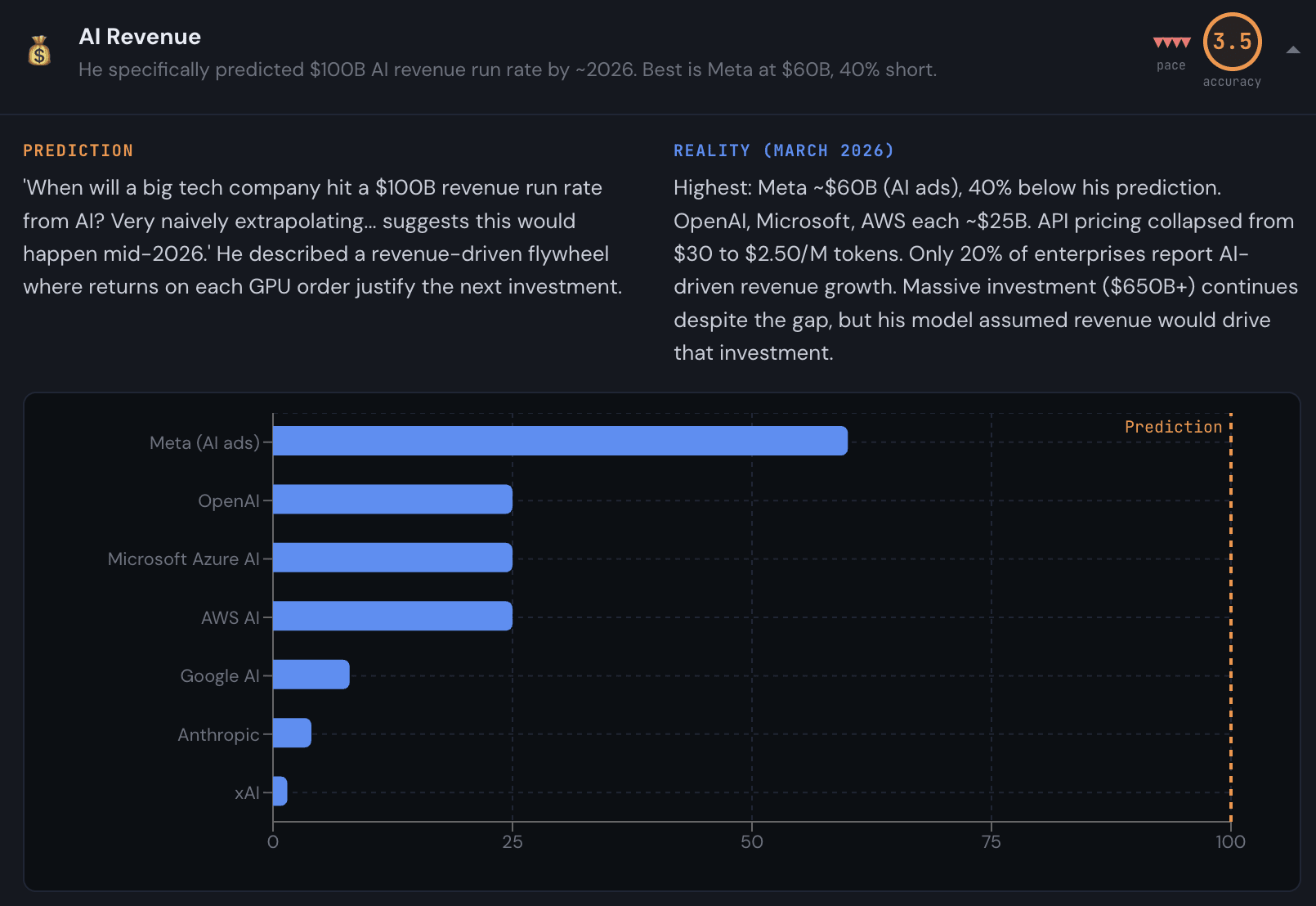
Anthropic revenue is actually about $20B I believe.
Claude’s constitution is great
Would democracy and good values recover after civilisational collapse?
Good point, that seems like a big risk! I expect the fraction of sentience that is (post)human or digital to be quite high, especially compared to today, in the intergalactic future. But improving values wrt wild animals seems important.
A world of intelligence too cheap to meter is more teleological: constraints and tradeoffs that exist now are washed away, and what matters is mainly what people ultimately value. And more people ultimately value animal welfare than animal diswelfare. The main game is wild animals, and the ~only way for things to go well for them is if we build an ASI that can eventually reshape the natural world to be less suffering filled. I think it is very unlikely farmed animal suffering is exported to other galaxies in a major way, because at technological maturity animals will not be the mose efficient way to meet human material needs.
Also, for those of us working in AI governance, ‘cG’ and ‘CIGI’ (the Center for International Governance Innovation) sound the same out loud. But in writing, I tend to use cG too.
What AI timelines are highest impact to act on?
I feel torn, and I think it varies a lot depending on your individual circumstances and opportunities. But overall, I think the arguments for prioritising shorter timelines are a bit stronger.
What timelines to act on
While I don’t work in GHD, I still enjoy reading GHD content on the Forum and on Substack. I agree that interesting questions in GHD are far from solved, but I wonder if a lot of the low-hanging intellectual fruit has been picked (your number 5)? I wasn’t around in early GiveWell days but I imagine that would have been an amazing time to be thinking about GHD and coming up with lots of new approaches and ideas. I haven’t found GiveWell’s research to be that surprising or interesting lately for instance (vibes-based, I don’t engage that closely with them anymore).
I would be keen to hear more from CE charities about what things they are learning and what questions they are facing!
Re your solution #2, I think I probably wouldn’t want the Forum team to show ‘favouritism’, but the decline of GHD curated posts is interesting, and maybe that should change.
I think the type of early deal that would be most valuable is where the US and China both agree to produce a joint ‘consensus’ ASI aligned to ‘the good’. In more detail:
The US and China, as you note, are unsure who will win, and would be better off making a deal to preserve some minimum amount of future influence. But I think I am more worried than you about the costs of continued multipolarity into space colonisation. You write “Even having two alternative systems might open up the possibility for comparison, healthy competition, and moral trade.” War, threats, and unhealthy (e.g., burning the cosmic commons) competition also seem like important possibilities here.
Instead, I think having a joint superintelligence that coordinates using our cosmic endowment would be better, with some amount of influence within the ‘moral parliament’ of the ASI for each of the US and China.
Just that would be preferable to dividing up the universe into two camps I think—it is easier to do moral trades within one agent acting under moral uncertainty than coordinating between two agents.
A better version, though, could involve the US and China agreeing on some core moral precepts, or just a moral reflection process, and then jointly designing a moral curriculum for the proto-ASI including plenty of Western and Chinese texts, and letting the ASI do as it sees fit. Presumably both sides genuinely believe they are right and that an appropriate moral training process for the AI will lead to liberalism/Socialism with Chinese characteristics. So this exploits the two sides having different credences (where as you note your proposed deals are possible even if both sides have the same credences). This creates a larger surplus for posisble agreements.
Of course, agreeing to create a joint ASI could also have big nearer term benefits, e.g. avoiding racing and slowing down AI progress and investing more in safety.
This proposal is clearly very far outside the overton window currently, but I don’t think this is that much worse on feasibility than your proposed great power resource-sharing deals. It also solves the enforcement challenge as well which is convenient since we might have needed to create such a consensus AI to enforce a different sort of deal.
I am tentatively excited about this proposal, but I expect there isn’t much to do to further it until the relevant parties are taking things more seriously.
I’m fairly sympathetic to that, but it also feels like one needs to draw a line somewhere and where they have currently drawn it seems not unreasonable to me. Though another place to draw the line kind of on the opposite extreme which could also work is just anyone who supports effective giving and is planning to donate/salary sacrifice a lot of their money. Maybe the worry is that is too fuzzy and diluting the core 10% message though.
fyi @Luke Moore 🔸
Great article! I sometimes find myself explaining cash benchmarking to people and why some charities still beat cash, and this will be a useful thing to link to going forwards :)
Seems great! Insofar as you feel comfortable saying, why isn’t this (fully) funded by cG?
Reasonable if you don’t want to publicly go into internecine tensions, but the obvious question seems to be how you see this relating to principles-first EA, which is, on its face, a similar idea.
cG made more AI policy grants than this in 2025! E.g. just from the >$1M bucket, there was also Oxford AI governance Initiative, Global Shield Global Catastrophic Risks Advocacy, Center for a New American Security, GovAI, Tarbell Center for AI Journalism, and maybe others I am missing!