I’m the Director of the Happier Lives Institute and Postdoctoral Research Fellow at Oxford’s Wellbeing Research Centre. I’m a philosopher by background and did my DPhil at Oxford, primarily under the supervision of Peter Singer and Hilary Greaves. I’ve previously worked for an MP and failed to start a start-up.
MichaelPlant
Karma: 9,115
Taking happiness seriously: Can we? Should we? Would it matter if we did? A debate
I wasn’t sure about the ‘do-ocracy’ thing either. Of course, it’s true that no one’s stopping you from starting whatever project you want—I mean, EA concerns the activities of private citizens. But, unless you have ‘buy-in’ from one of the listed ‘senior EAs’, it is very hard to get traction or funding for your project (I speak from experience). In that sense, EA feels quite like a big, conventional organisation.
Jack—or others who have run open board rounds recently—can you say more concretely what your advertisement and selection process was? In HLI, we’re thinking about doing an open board round soon, but I’m not sure exactly how we’d do it.
For reference, for selection for staff, we standardly do an initial application, two interviews and two test tasks (1 about 2 hours, 1 about 5 hours). This doesn’t seem like obviously the right process for board members: I’m hesitant to ask board members to do (long) test tasks, as they would be volunteers, plus I’m not sure what they would even be. But I’m also wary of spending lots of staff time on interviews and, similarly, don’t have a very clear idea of what criteria I’m selecting against. So, any recommendations you have would be great!
Thanks! Ah, in that case, I’m not sure what that community-building money was spent on—but I guess that’s not the question you’re asking!
Thanks very much for this. I see that OP’s longterm pot is really big and I’m wonder if that’s all community building, and also what counts as community building.
If you spend money on, say, AI safety research, I guess I’d see that as more like object-level funding than community building. Whereas ‘pure’ community building is the sort of thing the local groups do: bringing people together to meet, rather than funding specific work for the attendees to do. (If someone funded AMF and their team grew, I’m not sure people would say that’s GH and W community building; by analogy, maybe object-level work doesn’t count)
Does this seem right? I imagine lots of OPLT’s money is object-level stuff rather than pure community building. If so, maybe those should be split apart (and the LT community budget gets quite a bit smaller).
For comparison, if so
Or how about, rather than, “too rich” it’s has “no room for more funding” (noRFMF)?
Yes, glad the strategy fortnight is happening. But this is fully 6 months post-FTX. And I think it’s fair to say there’s been a lack of communication. IME people don’t mind waiting so much, so long as they have been told what’s going to happen.
I see a couple of people have disagreed with this. Curiously to know why people disagree! Is this the wrong model of what crisis response looks like? Am I being too harsh about 2 and 3 not happening? Do I have the wrong model of what should happen to restore trust? Personally, I would love to feel that EA handled FTX really well.
I agree with you that the loss of trust in leaders really stands out. I think it’s worth asking why that happened and what could have been done better. Presumably people will differ on this, but here’s roughly how I would expect a crisis to be managed well:
Crisis emerges.
Those in positions of authority quickly take the lead, say what needs to be changed, and communicate throughout
Changes are enacted
Problem is solved to some degree and everyone moves on.
What dented my trust was that I didn’t and haven’t observed 2 or 3 happening. When FTX blew up, various leaders seemed to stop communicating, citing legal reasons (which I don’t understand and don’t seem particularly plausible). I can’t think of any major changes that have been proposed or enacted, even now (Cf Winston Churchill’s “don’t let a good crisis go to waste”). I think restoring trust from this position is tricky—because it now feels like it’s been a long time since FTX without much happening. But what I would still like to see is those in central leadership positions is reflecting publicly on what’s happened, what they’ve learnt, and sharing a vision for the future.
Thanks for writing this up. I’ve often thought about EA in terms of waves (borrowing the idea from feminist theory) but never put fingers to keyboard. It’shard to do, because there is so much vagueness and so many currents and undercurrents happening. Some bits that seem missing:
You can identify waves within causes areas as well as between cause areas. Within ‘future people’, it seemed to go from X-risks to ‘broad longtermism’ (and I guess it’s now going back to a focus on AI). Within animals, it started with factory-farmed land animals, and now seems to include invertebrates and wild-animals. Within ‘present people’, it was objective wellbeing—poverty and physical health—and now is (I think and hope) shifting to subjective wellbeing. (I certainly see HLI’s work as being part of 2nd or 3rd wave EA).
Another trend is that EA initially seemed to be more pluralistic about what the top cause was (“EA as a question”), and then became more monistic with a push towards longtermism (“EA as an answer”). I’m not what that next stage is.
(Obviously we can’t put things on 0-10 scales but) I just want to add that a 0.5/10 decrease should be considered a medium-big drop.
Or, senior AI researcher says that AI poses no risk because it’s years away. This doesn’t really make sense—what will happen in a few years? But he does seem smart and work for a prestigious tech company, so...
Yes, reflecting on this since posting, I have been wondering if there is some important distinction between the principle of charity applied to arguments in the abstract vs its application to the (understated) reasoning of individuals in some particular instance. Steelmanning seems good in the former case, because you’re aiming to work your way to the truth. But steelmanning goes to far, and become mithrilmanning, in the latter case when you start assuming the individuals must have good reasons, even though you don’t know what they are.
Perhaps mithrilmanning involves an implicit argument from authority (“this person is an authority. Therefore they must be right. Why might they be right?”).
Minor points
These respond to bits of the discussion in the order they happened.
1. On the meaning of SWB
Rob and Elie jump into discussing SWB without really defining it. Subjective wellbeing is an umbrella term that refers to self-assessments of life. It’s often broken down into various elements, each of which can be measured separately. There are (1) experiential measures, how you feel during your life – this is closest to ‘happiness’ in the ordinary use of the word; (2) evaluative measure are an assess of life a a whole; the most common is life satisfaction; (3) ‘eudaimonic’ measures of how meaningful life is. These can give quite similar answers. As an example, see the image below for what the UK’s Office of National Statistics asks (which it does to about 300,000 people each year!) and the answers people give.
2. On the wellbeing life-year, aka the WELLBY
The way the discussion is framed, you might think HLI invented the WELLBY, or we’re the only people using it. That gives us too much credit: we didn’t and we’re not! Research into subjective wellbeing – happiness – using surveys has been going on for decades now and we’re making use of that. The idea of the WELLBY isn’t particularly radical – it’s a natural evolution of QALYs and DALYs – although the first use seems of the term seems have only been in 2015 (1, 2). The UK government has had WELLBYs as a part of their official toolkit for policy appraisal since 2021.
It is true that HLI is one of the first (if not the first) organisations to actually try to do WELLBY cost-effectiveness; although the UK government has this ‘on the books’, our understanding is it’s not being implemented yet.
3. Is SWB ‘squishy’ and hard to measure?
Elie: I think the downside [of measuring SWB], or the reasons not to, might be that on one level, I think it can just be harder to measure. A death is very straightforward: we know what has happened. And the measures of subjective wellbeing are squishier in ways that it makes it harder to really know what it is
As noted, there are different components of SWB: happiness is not the same thing as life satisfaction. I don’t think either of these are that squishy or that we don’t know what they are; they are different things. I don’t think measuring them isn’t hard: you can just ask “how happy are you, 0-10” or “how satisfied are you with your life nowadays, 0-10”! People find it easier to answer questions about their SWB than their income, if you look at non-response rates (OECD 2013). Of course, they are a measure of something subjective, but that’s the whole point. I don’t know how happy you feel: you need to tell me!
4. Does anyone’s view of the good not include SWB?
Elie: I think some people might say, “I really value reducing suffering and therefore I choose subjective wellbeing.” I think other people might say, “I think these measures are telling me something that is not part of my ‘view of the good,’ and I don’t want to support that.”
What constitutes someone’s wellbeing, that is, ultimately makes their life go well for them? In philosophy, there are three standard answers (see our explainer here). What matters is (1) feeling good – happiness, (2) having your desires met – life satisfaction, roughly – or (3) objective goods, such as knowledge, beauty, justice, etc, plus maybe (1) and/or (2). It would be a pretty wild view of wellbeing where people’s subjective experience of life didn’t matter at all, or in any way! It might not be all that matters, but that’s another thing.
5. On organisational comparative advantage
Elie: Because we’re not trying to add value by being particularly good philosophically. That’s not part of GiveWell’s comparative advantage.
If I can be forgiven for tooting our horn, I do see HLI’s comparative advantage as being particularly philosophically rigorous, as well as really understanding wellbeing science (I’m a philosopher; the other researchers are social scientists). We’re certainly much less experienced than GiveWell at understanding how well organisations implement their programmes.
6. On moral weights
Elie: I think this is an area — moral weights — where I don’t feel the same way. I don’t think this is a mature part of GiveWell. Instead, this is a part of GiveWell that has a huge amount of room for improvement
We could be talked into helping with this! In 2020 we explored how SWB would change GiveWell’s moral weights (GiveWell didn’t respond at the time). We subsequently have been doing more work on how to compare life-saving to life-improving interventions, including a survey looking at the ‘neutral point’ and other issues about interpreting SWB data.
7. On the challenges of using SWB given data limitations
Rob Wilbin: So just the number of studies that you can draw on if you’re strictly only going to consider subjective wellbeing is much lower.
I think another thing that really bites is that subjective wellbeing outcomes are really at the end of the chain of all of these different factors about someone’s life — their income, their health, their education, their relationships, all of these different factors.
We see data limitations as the biggest single challenge for SWB. The sort of data we’d want is scarce in low-income countries. We’ve started to talk to organisation working in LIC and to encourage them to collect data. Our capacity to do this is, however, very limited, but we would expand it if we had the resources. We found enough to compare mental health to cash transfers etc. (and even then we had to convert from mental health scores to SWB scores) but we expect to find much less data to look at other interventions.
On the complex causal chain, part of the virtue of SWB is that, if you have the SWB data, you don’t need to guess at how much all the different changes an intervention makes to someone’s life affects their wellbeing: you can just look at their answers, and they tell you! Take an education programme. It might change someone’s life in all sorts of ways. But if you’ve done an RCT and measured SWB, you can see the impact without needing to identify where it came from.
Elie: Maybe there’s reason to give credence to the measures that are easier to deal with and easier to know that you’ve done something good and made someone’s life better.
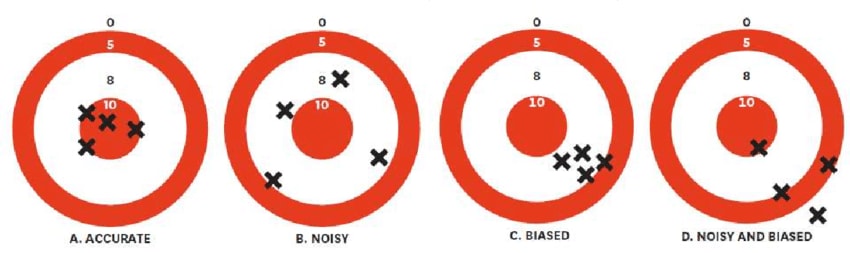
All this raises a good question: what should we do if we don’t have the data we want? As Daniel Kahneman reminds us, we should distinguish two concerns about measurement (and judgement). One is noise, the other is bias.
From Kahneman et al. (2016).
One way to put Elie and Rob’s concern is that SWB is a noisy measure. Now, if you have loads of data, you should use a noisy measure over a biased one because all the noise will average out. However, if you don’t have much data, and you have a choice between (C on the figure) a non-noisy, biased measure or (B on the figure) a noisy, non-biased one, you could sensibly conclude you’d get closer to the bull’s eye with (B).
Here’s a hypothetical example that brings this thought. Imagine we’re evaluating a new intervention. There is a n = 20,000 RCT that shows it doubles income for pennies. If we convert the income effects to WELLBYs it’s much more cost-effective than StrongMinds. But there’s an n = 100 RCT with SWB that shows it has a slightly negative but very very imprecisely measured effect on SWB. In this case, I think we’d mostly go with the income evidence (more technically: we’d combine the uncertainty of the income estimate with the conversion to SWB estimate and then combine both the income-converted and the SWB evidence in a bayesian manner).
But the issue is this. How do you know how biased your measures are? You need to establish bias by reference to a ‘ground truth’ of accuracy – how far are they from the bull’s eye? I’d argue that, when it comes to measuring impact, SWB data is the least-bad ground truth: you learn how important income, unemployment, health etc are by seeing their relationship to SWB. Hence, in the above example, I’d be inclined to go with the income data because there’s so much evidence already income does improve SWB! If the full sweep of available data showed income had no effect, I wouldn’t conclude that the income data from the hypothetical example was evidence the programme was effective. Of course there will be gaps in our evidence, and sometimes we have to guess, but we should try to avoid doing that.
8. On the tricky issue of the value of saving a life
It’s too long to quote in full, but I don’t think Rob or Elie quite captured what HLI’s view is on these issues, so let me try here. The main points are these; see our report here.
(1) comparing quality to quantity of life is difficult and complicated; there isn’t just ‘one simple way’ to do it. There are a couple of key issues which are discussed in the philosophical literature which haven’t, for whatever reason, made it into the discussions by GiveWell, effective altruists, etc.
(2) One of these issues, the one Elie and Rob focus on, is the ‘neutral point’: where on a 0-10 life satisfaction should count as equivalent to non-existence? We think it’s not obvious and merits further research. So far, there’s been basically no work on this, which is why we’ve been looking into it.
(3) how you answer these philosophical questions and make quite a big difference to the relative priorities of life-saving vs life-improving interventions. We got into that in a big report we did at the end of 2022, where we found that going from one extreme of ‘reasonable’ opinion to the other changes the cost-effectiveness of AMF by about 10 times.
(4) HLI doesn’t have a ‘house view’ on these issues and, if possible, we’ll avoid taking one! We think that’s for donors to decide.
(5) GiveWell does take a ‘house view’ on how to make this comparison. We’ve pointed out that GiveWell’s view is at the ‘most favourable to saving lives, least favourable to improving lives’ end of the spectrum, and that (on our estimates) treating depression does good more if you hold even slightly less favourable assumptions. This shouldn’t really need saying, but philosophy matters!
Major points
I’m writing from the perspective of the Happier Lives Institute. We’re delighted that HLI’s work and the subjective wellbeing approach featured so prominently in this podcast. It was a really high-quality conversation, and kudos to host Rob Wiblin for doing such an excellent job putting forward our point of view. Quite a few people have asked us what we thought, so I’ve written up some comments.
I split those into four main comments and a number of minor ones. To preview, the main comments are:
We’re delighted, but surprised, to hear GiveWell are now so positive about the SWB approach; we’re curious to know what changed their mind.
HLI and GiveWell disagree on what does the most good based on differences of how to interpret the evidence; we’d be open to an ‘adversarial collaboration’ to see if we can iron out those differences.
We’d love to do more research, but we’re currently funding constrained. If you – GiveWell or anyone else – want to see it, please consider supporting us!
Finally, Rob, it’s about time you had us on the podcast!
Main points
1. We’re delighted, but surprised, to hear GiveWell are now so positive about the SWB approach; we’re curious to know what changed their mind.
Elie Hassenfeld says the differences in opinion between HLI and GiveWell aren’t because HLI cares about SWB and GiveWell does not, but down to differences of opinion interpreting the data[1]. This is great news – we’re glad to see major decision-makers like GiveWell taking happiness seriously – but it is also news to us!
Listeners of the podcast may not know this, but I (as a PhD student) and then HLI have been publicly advocating for SWB since about 2017 (e.g., 1, 2). I/we have also done this privately, with a number of organisations, including GiveWell, who I spoke to about once a year. Whilst lots of people were sympathetic, I could not seem to interest the various GiveWell staff I talked to. That’s why I was surprised when earlier this year, GiveWell made its first public written comment on SWB and was tentatively in favour; Elie’s podcast this week seemed more positive.
So, we’re curious to know how thinking in GiveWell changed on this. This is of interest to us but I’m sure others would like to know how change happens inside large organisations.
2. HLI and GiveWell disagree on what does the most good based on differences of how to interpret the evidence; we’d be open to an ‘adversarial collaboration’ to see if we can iron out those differences.
Elie explained that the reason GiveWell doesn’t recommend StrongMinds[2] which HLI does recommend, is due to differences in the interpretation of the empirical data. Effectively, what GiveWell did was look at our numbers, then apply some subjective adjustments on factors they thought were off. We previously wrote a long response to GiveWell’s assessment and don’t want to get stuck into all those weeds here. Elie says – and we agree! – that reasonable people can really disagree on how to interpret the evidence. That’s why we’d be interested in an ‘adversarial collaboration’ to see if we can resolve them. I can see three areas of disagreement.
First, on the general theoretical issue of whether and how to make subjective adjustments to evidence. GiveWell are prepared to make adjustments, even if they’re not sure exactly how big they should be. For example, Elie says he’s unsure about the 20% reduction for ‘experimenter demand effect’. Our current view is to be very reluctant to make adjustments without clear evidence of what size is justified. Our reluctance is motivated by cases such as this: these ‘GiveWellian haircuts’ can really add up and change the results, so the conclusion ends up being more on the researcher’s interpretation of the evidence than the evidence itself. But we’re not sure how to think about it either!
A second, potentially more tractable issue, is clarifying what evidence would change our mind about the specific issues. For instance, if there was a well conducted RCT that directly estimated the household spillover effects of psychotherapy in a setting similar to StrongMinds, we’d likely largely adopt that estimate.
A third issue is deworming. Elie and Rob discuss HLI’s reassessment of GiveWell’s deworming numbers, for which GiveWell very generously awarded us a prize. However, GiveWell haven’t commented – on the podcast or elsewhere – on our follow-up work, which finds the available evidence suggests that there are no statistically significant long-term effects of deworming on SWB. This uses the exact same studies that GiveWell relies on; it indicates that GiveWell aren’t as bought into about SWB as Elie sounds or they haven’t integrated this evidence yet.
3. We’d love to do more research, but we’re currently funding constrained. If you – GiveWell or anyone else – want to see it, please consider supporting us!
As a small organisation – we’re just 4 researchers – we were pleased to see our ideas and work is influencing the wider discussion about how to do have the biggest impact. As the podcast highlights, HLI brings a different (reasonable) perspective, we have provided important checks on other’s work, we provide unique expertise in philosophy and wellbeing measurement, and we have managed to push difficult issues up to the top of the agenda[3], [4], [5]. We think we ‘punch above our weight’.
Elie mentions a number of areas where he’d love to see more research including in SWB and the difficult question of how to put numbers on the value of saving a life. We think we’d be very well placed to do this work, for the reasons given above; we’re not sure anyone else will do it, either (we understand GiveWell don’t have immediate plans, for instance). However, we don’t have the capacity to do more and we can’t expand due to funding constraints. So, we’d love donors to step forward and support us!
Of course we’re biased, but we believe we’re a very high leverage, cost-effective funding opportunity for donors who want to see top-quality research that changes the paradigm on global wellbeing and how to do the most good. Please donate here or get in touch at Michael@happierlivesinstitute.org. We’re currently finalising our research agenda for 2023-4 (available on request).
4. Finally, Rob, it’s about time you had us on the podcast!
We’ve got much more to say about topics covered, plus other issues besides: longtermism, moral uncertainty, etc. (Rob has said we’re on the list, but it might take a while because of the whole AI thing that’s been blowing up; which seems fair).
- ^
“I think ultimately what it comes down to is we have a different interpretation of the empirical data — meaning we look at the same empirical data and reach different conclusions about what it means for the likely impact of the programme in the real world.”
- ^
An organisation that treats depression at scale and is currently our top recommendation.
- ^
“…I think one of the things that HLI has done effectively is just ensure that [tradeoffs between saving and extending lives] is on people’s minds. I mean, without a doubt their work has caused us to engage with it more than we otherwise might have. Similar to some of the questions you were asking earlier, like, “Why doesn’t institution X see that it should do whatever?” Well, because it’s kind of hard, and sometimes you need another organisation to be pushing it in front of you. I think that’s really good that they’ve done that, because it’s clearly an important area that we want to learn more about, and I think could eventually be more supportive of in the future.”
- ^
“Yeah, they went extremely deep on our deworming cost-effectiveness analysis and pointed out an issue that we had glossed over, where the effect of the deworming treatment degrades over time. We had seen that degrading, and the way we had treated it, I should say, was that that’s just a noisy estimate, and we just took the average estimate persisting over the long run. Their critique convinced us that we should at least incorporate some probability that the effect is degrading into our overall model, and that shifted our overall assessment of deworming down by a small amount. Had we taken their correction on board in the past, it would have meant a few million dollars that we would have given elsewhere instead of deworming. Their published critique, I think we didn’t agree with the headline result that they reached, but we were really grateful for that critique, and I thought it catalysed us to launch this Change Our Mind Contest. And also it was a great example of the engagement that we’re getting from being transparent. That we can say, “Here’s our decisions, here’s why they could point to an error, and it changes our mind.” That was really cool, and we were really grateful for it.”
- ^
“I think the pro of subjective wellbeing measures is that it’s one more angle to use to look at the effectiveness of a programme. It seems to me it’s an important one, and I would like us to take it into consideration.”
- ^
Strawmen, steelmen, and mithrilmen: getting the principle of charity right
Yeah, I would frame the event as “this is a topic being are going to be discussing something, now is the time to pitch in”
Oh, excited to learn this is happening! I would write something. Most likely: a simplified and updated version of my post from a couple of weeks back (What is EA? How could it be reformed?). Working title: The Hub and Spoke Model of Effective Altruism.
That said, in the unlikely event someone wants to suggest something I should write, I’d be open to suggestions. You can comment below or send me a private message.
Points taken. The reaction I’d have anticipated, if I’d just put it the way I did now, would be
(1) the point of EA is to do the most good (2) we, those who run the central functions of EA, need to decide what that is to know what to do (3) once we are confident of what “doing the most good” looks like, we should endeavour to push EA in that direction—rather than to be responsive to what others think, even if those others consider themselves parts of the EA community.
You might think it’s obvious that the central bits of EA should not and would not ‘pick favourites’ but that’s been a more or less overt goal for years. The market metaphor provides a rationale for resisting that approach.
Yeah, seems helpful to distinguish central functions (something lots of people use) from centralised control (few people have power). The EA forum is a central function, but no one, in effect, controls it (even though CEA owns and could control it). There are mods, but they aren’t censors.