I’m a developer on the EA Forum (the website you are currently on). You can contact me about forum stuff at will.howard@centreforeffectivealtruism.org or about anything else at w.howard256@gmail.com
Will Howard
Karma: 876
PSA: You can now add buttons to posts and comments:
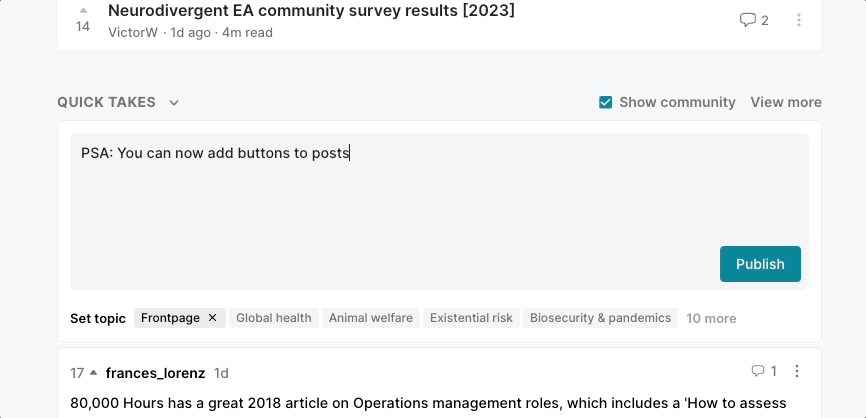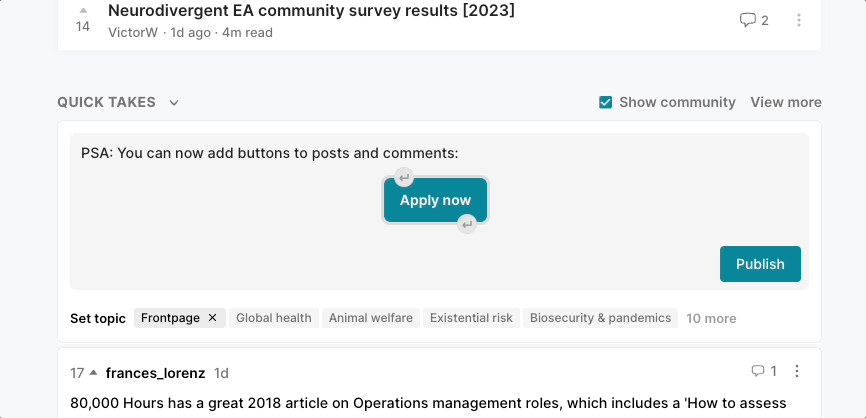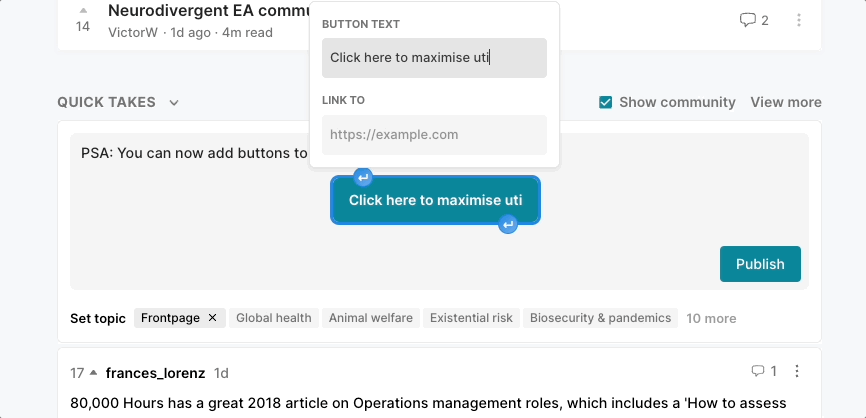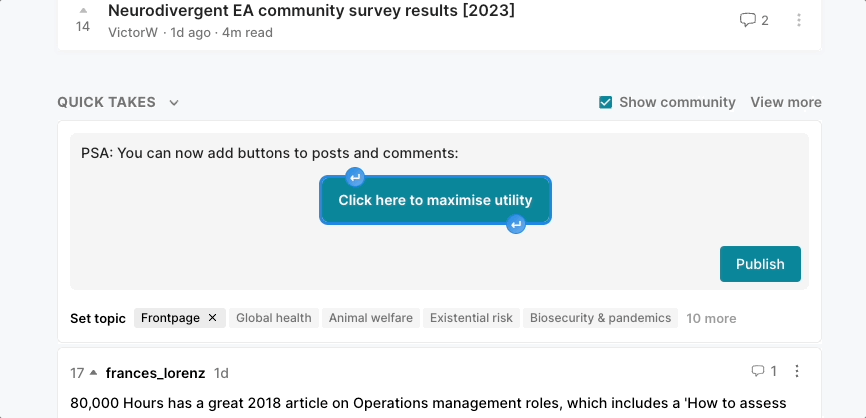
Click here to maximise utilityWe would love it if people started adding these to job opportunities to nudge people to apply. To add a button, select some text to make the toolbar appear and then click the “Insert button” icon (see below)
As always, feedback on the design/implementation is very welcome.
Breakdown of Open Philanthropy grants to date
I came across this spreadsheet buried in a comment thread. I don’t know who made it (maybe @MarcusAbramovitch knows) but, it’s great. It shows a breakdown of all OP grants by cause area and organisation, updated automatically every day:
I’d be interested in any feedback people have about the analytics page we added recently. You can get to it via “Post stats” in the user menu.
Specific areas of feedback that would be helpful:
Are the stats displayed useful to you and easy to understand, are there other stats that you think would be more useful?
Feedback on the design/layout
Do you endorse it as a concept (i.e. you might think this incentivises engagement bait or something, if you notice that motivation in yourself that would be useful to know)?
Is it broken in any way? Is it annoyingly slow?
We also updated the analytics page for individual posts at the same time so feedback on that would be helpful as well (you can get to this via the three dot menu on posts you have published, or via the “Post stats” page).
I’ll be going to this. I just listened to your podcast with Daniel Filan and I thought your point about protests being underrated was a good one
There is already a topic for the FTX discussion which you can add a filter for on the frontpage to reduce how much you see it:
Ok nested bullets should be working now :)
The thing that stands out to me as clearly seeming to go wrong is the lack of communication from the board during the whole debacle. Given that the final best guess at the reasoning for their decision seems like something could have explained[1], it does seem like an own goal that they didn’t try to do so at the time.
They were getting clear pressure from the OpenAI employees to do this for instance, this was one of the main complaints in the employee letter, and from talking to a couple of OAI employees I’m fairly convinced that this was sincere (i.e. they were just as in the dark as everyone else, and this was at least one of their main frustrations).
I’ve heard a few people make a comparison to other CEO-stepping-down situations, where it’s common for things to be relatively hush hush and “taking time out to spend with their family”. I think this isn’t a like for like comparison, because in those cases it’s usually a mutual agreement between the board and the CEO for them both to save face and preserve the reputation of the company. In the case of a sudden unilateral firing it seems more important to have your reasoning ready to explain publicly (or even privately, to the employees).
It’s possible of course that there are some secret details that explain this behaviour, but I don’t think there’s any reason to be overly charitable in assuming this. If there was some strategic tradeoff that the board members were making it’s hard to see what they were trading off against because they don’t seem to have ended up with anything in the deal[2]. I also don’t find “safety-related secret” explanations that compelling because I don’t see why they couldn’t have said this (that there was a secret, not what it was). Everyone involved was very familiar with the idea that AI safety infohazards might exist so this would have been a comprehensible explanation.
If I put myself in the position of the board members I can much more easily imagine feeling completely out of my depth in the situation that happened and ill-advisedly doubling down on this strategy of keeping quiet. It’s also possible they were getting bad advice to this effect, as lawyers tend to tell you to keep quiet, and there is general advice out there to “not engage with the twitter mob”.
- ^
Several minor fibs from Sam, saying different things to different board members to try and manipulate them. This does technically fit with the “not consistently candid” explanation but that was very cryptic without further clarification and examples
- ^
To frame this the other way, if they had kept quiet and then been given some lesser advisory position in the company afterwards you could more easily reason that some face-saving dealing had gone on
- ^
We should fix and normalize relative to the moral value of human welfare, because our understanding of the value of welfare is based on our own experiences of welfare
I used to think this for exactly the same reason, but I now no longer do. The basic reason I changed my mind is the idea that uncertainty in the amount of welfare humans (or chickens) experience is naturally scale invariant. This scale invariance means that observing any particular absolute amount of welfare (by experiencing it directly) shouldn’t update you as to the relative amount of welfare under different theories.
The following is a fairly “heuristic” version of the argument, I spent some time trying to formalise it better but got stuck on the maths, so I’m giving the version that was in my head before I tried that. I’m quite convinced it’s basically true though.
The argument
Consider only theories that allow the most aggregation-friendly version of hedonistic utilitarianism[1]. Under this constraint, the total amount of utility experienced by one or more moral patients is some real quantity that can be expressed in objective units (“hedons”), and this quantity is comparable across the theories that we are allowing. You might imagine that you could consult God as to the utility of various world states and He could say truthfully “ah, stubbing your toe is −1 hedon”. In your post you also suppose that you can measure this amount yourself through direct experience, which I find reasonable.
From the perspective of someone who is unable to experience utility themselves, there is a natural scale invariance to this quantity. This is clearest when considering the “ought” side of the theory: the recommendations of utilitarianism are unchanged if you scale utility up and down by any amount as it doesn’t affect the rank ordering of world states.
Another way to get this intuition is to imagine an unfeeling robot that derives the concept of utility from some combination of interviewing moral patients and constructing a first principles theory[2]. It could even get the correct theory, and derive that e.g. breaking your arm is 10 times as bad as stubbing your toe. It would still be in the dark about how bad these things are in absolute terms though. If God told it that stubbing your toe was –1 hedons that wouldn’t mean anything to the robot. God could play a prank on the robot and tell it stubbing your toe was instead –1 millihedons, or even temporarily imbue the robot with the ability to feel pain and expose it to –1 millihedons and say “that’s what stubbing your toe feels like”. This should be equally unsurprising to the robot as being told/experiencing –1 hedon.
My claim is that the epistemic position of all the different theories of welfare are effectively that of this robot. And as a result of this, observing any absolute amount of welfare (utility) under theory A shouldn’t update you as to what the amount would be under theory B, because both theories were consistent with any absolute amount of welfare to begin with. In fact they were “maximally uncertain” about the absolute amount, no amount should be any more or less of a surprise under either theory.
If you had a prior reason to think theory B gives say 5 times the welfare to humans as theory A (importantly in relative terms), then you should still think this after observing the absolute amount yourself, and this is what generates the thorny version of the two envelopes problem. I think there are sensible prior reasons to think there is such a relative difference for various pairs of theories.
For instance, suppose both A and B are essentially “neuron count” theories and agree on some threshold brain complexity for sentience, but then A says “amount of sentience” scales linearly with neuron count whereas B says it scales quadratically. It’s reasonable to think that the amount of welfare in humans is much higher under B, maybe times higher.
Other examples where arguments like this can be made are:
A and B are the same except B has multiple conscious subsystems
A and B are predicting chicken welfare rather than human, and A says they are sentient whereas B says they are not. Clearly B predicts 0 times the welfare of A (equivalently A predicts infinity times the welfare of B)
Putting this in two envelopes terms
If we say we have two theories, 1 and 2, which you might imagine are a human centric (, )[4] and an animal-inclusive (, ) view, then we have:
And
As we are used to seeing.
But as you point out in your post, the quantities and are not necessarily the same (though you argue they should be treated as such) which makes this a nonsensical average of dimensionless numbers. E.g. could be 0.00001 hedons and could be 10 hedons, which would mean we are massively overcounting theory 1. The quantities we actually care about are and (dimension-ed numbers in units of hedons), or their ratio . We can write these as:
This may seem like a roundabout way of writing these down, but remember that what we have from our welfare range estimates are values for , so these can’t be cancelled further and the s are the minimum number of parameters we can add to pin down the equations. The ratio is then:
I find this easier to think about if the ratios are in terms of a specific theory, e.g. , so you are always comparing what the relative amount of welfare is in theory X vs some definite reference theory. We can rearrange (3) to support this by dividing all the fractions though by :
Where
Again, maybe this seems incredibly roundabout, but in this form it is more clear that we now only need the ratios not their absolute values. This is good according to the previous claims I have made:
Because of scale invariance, it’s not possible to say anything about the absolute value of
It is possible to reason about the relative welfare values between theories, represented by
So under this framing the “solution to the two envelopes problem for moral weights” is that you need to estimate the inter-theoretic welfare ratios for humans (or any reference moral patient), as well as the intra-theoretic ratios between moral patients. I.e. you have to estimate as well as and for each theory.
I think this is still quite a big problem because of the potential for arguing that some theories have combinatorially higher welfare than others, thus causing them to dominate even if you put a very low probability on them. The neuron count example above is like this, you could make it even worse by supposing a theory where welfare is exponential in neuron count.
Returning to the human-centric vs animal inclusive toy example
If we say we have two theories, 1 and 2, which you might imagine are a human centric (, )[4] and a animal-inclusive (, ) view
Adding these numbers into this example we now have:
What should the value of be? Well in this case I think it’s reasonable to suppose and are in fact equal, as we don’t have any principled reason not to, so this still comes out to ~0.001. As in the original version we can flip this around to see if we get a wildly different answer if we make the inter-theoretic comparison be between chickens:
Now what should be, recalling that theory 1 says chickens are worth very little compared to humans? I think it’s reasonable say that is also very little compared to , since the point of theory 1 is basically to suppose chickens aren’t (or are barely) sentient, and not to say anything about humans. Supposing that none of the difference is explained by humans, we get , this also gives , so comes out to ~1000. This is the inverse of as we expect.
Clearly this is just rearranging the same numbers to get the same result, but hopefully it illustrates how explicitly including these ratios makes the two envelope problem that you get by naively inverting the ratios less spooky, because by doing so you are effectively wildly changing the estimates of .
I agree with you that there are many cases where for the specific theories under consideration it is right to assume that and are equal (because we have no principled reason not to), but that this is not because we are able to observe welfare directly (even if we suppose that this is possible). And for many pairs of theories we might think and are very different.
(Apologies for switching back and forth between “welfare” and “utility”, I’m basically treating them both like “utility”)
- ^
I think it’s right to start with this case, because it should be the easiest. So if something breaks in this case it is likely to also break once we start trying to include things like non-welfare moral reasons
- ^
“I’ve met a few of those”
- ^
We can label the “true” theory as A, because we only get the chance to experience the true theory (we just don’t know which one it is)
- ^
You could make this actually zero, but I think adding infinity in makes the argument more confusing
I think this is valuable research, and a great write up, so I’m curating it.
I think this post is so valuable because having accurate models of what the public currently believe seems very important for AI comms and policy work. For instance, I personally found it surprising how few people disbelieve AI being a major risk (only 23% disbelieve it being an extinction level risk), and how few people dismiss it for “Sci-fi” reasons. I have seen fears of “being seen as sci-fi” as a major consideration around AI communications within EA, and so if the public are not (or no longer) put off by this then that would be an important update for people working in AI comms to make.
I also like how clearly the results are presented, with a lot of the key info contained in the first graph.
Most deaths in war aren’t from gunshots
This is an edited version of a memo I shared within the online team at CEA. It’s about the forum, but you could also make it about other stuff. (Note: this is just my personal opinion)
There’s this stylised fact about war that almost none of the deaths are caused by gunshots, which is surprising given that for the average soldier war consists of walking around with a gun and occasionally pointing it at people. Whether or not this is actually true, the lesson that quoters of this fact are trying to teach is that the possibility of something happening can have a big impact on the course of events, even if it very rarely actually happens.
[warning: analogy abuse incoming]
I think a similar thing can happen on the forum, and trying to understand what’s going on in a very data driven way will tend to lead us astray in cases like this.
A concrete example of this is people being apprehensive about posting on the forum, and saying this is because they are afraid of criticism. But if you go and look through all the comments there aren’t actually that many examples of well intentioned posts being torn apart. At this point if you’re being very data minded you would say “well I guess people are wrong, posts don’t actually get torn apart in the comments; so we should just encourage people to overcome their fear of posting (or something)”.
I think this is probably wrong because something like this happens: users correctly identify that people would tear their post apart if it was bad, so they either don’t write the post at all, or they put a lot of effort into making it good. The result of this is that the amount of realised harsh criticism on the forum is low, and the quality of posts is generally high (compared to other forums, facebook, etc).
I would guess that criticising actually-bad posts even more harshly would in fact lower the total amount of criticism, for the same reason that hanging people for stealing bread probably lowered the theft rate among victorian street urchins (this would probably also be bad for the same reason)
This seems like the wrong order of magnitude to apply this logic at, $20mn is close to 1% of the money that OpenPhil has disbursed over its lifetime ($2.8b)
I think the big problem with the suffering/day of life estimate is that it assumes suffering can’t go negative. If you think suffering can go as low as 0.015 suffering-units it doesn’t seem too much of a stretch to think their lives could be net positive.
(this is a general problem with reducing-suffering derived estimates imo)
Some examples from my last company:
(product thing) We got into a trap of mainly developing features for our biggest customer, which made the product less generally useful to other customers, which made us even more reliant on our biggest customer in a sort of downwards spiral. About half the stuff I did was pretty low value for this reason. This is a problem I’ve heard a lot of companies get into, it’s hard to avoid because from a short term perspective keeping your main source of revenue happy makes sense
(eng thing) Our api got really slow and we launched a big project (~3 engineers for like 3 months, including me) to fix it, basically by manually optimising individual endpoints. About 2 months in I worked out that a big part of the problem was due to our load balancer sending too many requests to the same instance in a row (for a reason I still don’t understand) and fixing this (which took ~1 day) solved like 70% of the problem, and counterfactually I think we wouldn’t have done a big performance project if this had been fixed beforehand. There were lots of ~valuable lessons~ I learned from this, mostly very object level stuff:
“Work expands to consume the resources allocated to it”—having a big project with lots of engineers biased me towards assuming that the solution would require lots of engineering work, I think it would have been fixed faster if I was told I only had 1 week or something
Keep things simple, especially things that are fiddly, rarely changed, and a single point of failure (servers) - we had kubernetes set up with load balancing, autoscaling, pods with multiple docker containers, fine tuned health checks etc. All of this stuff interacted in accursed ways which obscured the problem. We didn’t really need any of it, and if we had just had 1 Big Server the problem would have been obvious, and probably wouldn’t have happened in the first place
Reproduce bugs in exactly same environment in which they occurred—creating a clone of the production environment with no traffic would have also made it obvious that the problem was due to servers getting overloaded
Very reasonable, I think the project is great as is. I just have one more newsletter-related suggestion:
It’s a lot cheaper to collect emails than it is to do the rest of the work related to sending out automated updates, so it could be worth doing that to take advantage of the initial spike in interest (without making any promises as to whether there will be updates). This could just be a link to a google form on the website if you wanted it to be really simple to implement.
I have a basic question about the opportunity cost part: do you track whether charities keep their reserves in investments vs cash? Are charities allowed (legally) to invest all their reserves in the stock market?
It seems like this would make a big difference to the opportunity cost if you are comparing keeping money in OpenPhil (which itself has >4 years of reserves and presumably keeps this in appreciating assets) vs giving it to NTI
This is a great idea, I just submitted a project. I also wrote it up as a post, but your post was what prompted me to write it :)
Something I tend to find with projects like this[1] is that they can be forgotten about after the initial launch because they’re not a destination site so there is no way for people to naturally come back to them. Have you thought about doing a newsletter or similar with an update on the projects that are added? I think it could be fairly infrequent (monthly) and automated and still be quite useful.
Also some minor feedback: submitting didn’t work initially because of some problem with the description field. I removed a url and some line breaks and then it worked.
- ^
i.e. the UnfinishedImpact project, not my idea
- ^
I wonder what’s happening with the OpenPhil board seat
I’m pretty sure that’s gone now. I.e. that the initial $30m for a board seat arrangement wasn’t actually legally binding wrt future members of the board, it was just maintained by who the current members would allow. So now there are no EA aligned board members there is no pressure or obligation to add any.
I could be wrong about this but I’m reasonably confident
Update on the home page algorithm
As mentioned above, we are now testing out some changes designed to make the home page algorithm better suited for users who visit more or less often. This will make it so that people who visit every day will see a home page similar to the existing algorithm, while less frequent users will see a “slower” home page which is weighted less towards recency and more towards karma.
We are rolling this out as an A/B test, so initially only 1/3rd of users will get the new algorithm. You can deliberately opt in (or out) by going here and selecting “New ‘slower’ frontpage algorithm” in the final dropdown. Some more details about the changes:This will apply to both logged-in and logged-out users. For logged out users: it’s calculated by device for you, so if you visit on your phone and your laptop the home page may be different
(shh don’t tell anyone) If you’re really a power user you can set the exact speed of the algorithm by adding “?algoActivityFactor=[number]” to the home page url like so. “algoActivityFactor” is a number between 0 and 1 which we calculate for each user based on their visit frequency. A value of 1 indicates daily visits, 0 means you’ve never visited, and a value around 0.5 corresponds to visiting every ~3 days. Keep in mind that this is mainly intended for debugging, so we can’t guarantee it’ll work forever
We’d love to hear your feedback on this, such as “I’m a daily user but I still think the slower algorithm is way better for me” (or the opposite). You can reply here or reach out to us at forum@centreforeffectivealtruism.org
You can now import posts directly from Google docs
Plus, internal links to headers[1] will now be mapped over correctly. To import a doc, make sure it is public or shared with “eaforum.posts@gmail.com″[2], then use the widget on the new/edit post page:
Importing a doc will create a new (permanently saved) version of the post, but will not publish it, so it’s safe to import updates into posts that are already published. You will need to click the “Publish Changes” button to update the live post.
Everything that previously worked on copy-paste[3] will also work when importing, with the addition of internal links to headers (which only work when importing).
There are still a few things that are known not to work:
Nested bullet points(these are working now)Cropped images get uncropped
Bullet points in footnotes (these will become separate un-bulleted lines)
Blockquotes (there isn’t a direct analog of this in Google docs unfortunately)
There might be other issues that we don’t know about. Please report any bugs or give any other feedback by replying to this quick take, you can also contact us in the usual ways.
Appendix: Version history
There are some minor improvements to the version history editor[4] that come along with this update:
You can load a version into the post editor without updating the live post, previously you could only hard-restore versions
The version that is live[5] on the post is shown in bold
Here’s what it would look like just after you import a Google doc, but before you publish the changes. Note that the latest version isn’t bold, indicating that it is not showing publicly:
Previously the link would take you back to the original doc, now it will take you to the header within the Forum post as you would expect. Internal links to bookmarks (where you link to a specific text selection) are also partially supported, although the link will only go to the paragraph the text selection is in
Sharing with this email address means that anyone can access the contents of your doc if they have the url, because they could go to the new post page and import it. It does mean they can’t access the comments at least
I’m not sure how widespread this knowledge is, but previously the best way to copy from a Google doc was to first “Publish to the web” and then copy-paste from this published version. In particular this handles footnotes and tables, whereas pasting directly from a regular doc doesn’t. The new importing feature should be equal to this publish-to-web copy-pasting, so will handle footnotes, tables, images etc. And then it additionally supports internal links
Accessed via the “Version history” button in the post editor
For most intents and purposes you can think of “live” as meaning “showing publicly”. There is a bit of a sharp corner in this definition, in that the post as a whole can still be a draft.
To spell this out: There can be many different versions of a post body, only one of these is attached to the post, this is the “live” version. This live version is what shows on the non-editing view of the post. Independently of this, the post as a whole can be a draft or published.