I’m a software engineer on the CEA Online team, mostly working on the EA Forum.
You can contact me at will.howard@centreforeffectivealtruism.org
I’m a software engineer on the CEA Online team, mostly working on the EA Forum.
You can contact me at will.howard@centreforeffectivealtruism.org
I donated to Charity Entrepreneurship! I think they have an incredibly high hit rate on a tight budget
Fixed now! Sorry about that
Consensual ways of affecting the size of some wild animal populations
What does “consensual” mean here (and to some extent above)? Consensual on the part of humans/institutions?
Update (I came across this while prepping voting for this year’s election): I did add this random tie breaking in the system last year, and by default it will be used again this year
Thanks for reporting this! I’ve just deployed a fix so the graph should display correctly now
It’s OK to eat honey
I plead clueless
I haven’t yet read the sequence, but I have it on my backlog to read based on finding your older post about this very interesting. I agree-voted “An FAQ about various objections” because I think the other two can be looked up/skimmed from the existing content, whereas I’m actually unfamiliar with the objections so that would be new info to me.
@Jeff Kaufman 🔸 it would be possible, we’re currently using a library that claims to use heuristics based on the user’s timezone and locale, but this doesn’t seem to work very well. For the forum we use IP geolocation which is more reliable, so we can switch to that.
@Ian Turner unfortunately we do get some value out of non-GDPR-compatible analytics, and we want to try and optimise the site as a top-of-funnel intro to EA over time, so we think the banner is worth it for now.
Draft comments
You can now save comments as permanent drafts:
After saving, the draft will appear for you to edit:
1. In-place if it’s a reply to another comment (as above)
2. In a “Draft comments” section under the comment box on the post
3. In the drafts section of your profile
The reasons we think this will be useful:
For writing long, substantive comments (and quick takes!). We think these are the some of the most valuable comments on the forum, and want to encourage more of them
For starting a comment on mobile and then later continuing on desktop
To lower the barrier to starting writing a comment, since you know you can always throw it in drafts and then never look at it again
Polls in comments
We recently added the ability to put polls in posts, and this was fairly well received, so we’re adding it to comments (… and quick takes!) as well.
You can add a poll from the toolbar, you just need to highlight a bit of text to make the toolbar appear:
And the poll will look like this...
You may be aware of this already, but you can set values other than 50% by using the “Other” field:
It’s still a bit from-the-hip, but we don’t have a way of specifically favouring variety unfortunately
I’m not quite as convinced of the much greater cost of “bad criticism” over “good criticism”. I’m optimistic that discussions on the forum tend to come to a reflective equilibrium that agrees with valid criticism and disregards invalid criticism. I’ll give some examples (but pre-committing to not rehashing these too much):
I think HLI is a good example of long-discussion-that-ends-up-agreeing-with-valid-criticism, and as discussed by other people in this thread this probably led to capital + mind share being allocated more efficiently.
I think the recent back and forth between VettedCauses and Sinergia is a good example of the other side. Setting aside the remaining points of contention, I think commenters on the original post did a good job of clocking the fact that there was room for the reported flaws to have a harmless explanation. And then Carolina from Sinergia did a good job of providing a concrete explanation of most of the supposed issues[1].
It’s possible that HLI and Sinergia came away equally discouraged, but if so I think that would be a misapprehension on Sinergia’s part. Personally I went from having no preconceptions about them to having mildly positive sentiment towards them.
Perhaps we could do some work to promote the meme that “reasonably-successfully defending yourself against criticism is generally good for your reputation not bad”.
(Stopped writing here to post something rather than nothing, I may respond to some other points later)
You could also argue that not everyone has time to read through the details of these discussions, and so people go away with a negative impression. I don’t think that’s right because on a quick skim you can sort of pick up the sentiment of the comment section, and most things like this don’t escape the confines of the forum.
When we launched the first iteration of this slider feature for a forum-wide event, it was anonymous. We later decided to make it non-anonymous because we thought it would make people more bought into the poll (because they would be interested to see the opinions of people they recognise, and would take their own vote more seriously because it was public).
I think broadly speaking this worked, and people were more bought in to later polls. Letting people add comments was also intended to move further in the direction of “prompt for individuals to stake out their positions” (as opposed to “tool for aggregating preferences”).
I wouldn’t want to add the option of voting anonymously because I would guess people would use it just because it’s the lowest effort thing to do, even when there’s no real downside to having people see their vote. If people do want to vote anonymously they can always create an anonymous account, so a high-friction version of the option does exist.
(and: on the point about anon-voting being potentially hackable/known to CEA, fully anonymous accounts are the simplest way round this too).
I don’t think it’s obvious that less chance of criticism implies a higher chance of starting a project. There are many things in the world that are prestigious precisely because they have a high quality bar.
Some invitees to the Meta Coordination Forum (maybe like 3 out of the ~30) should be ‘independent’ EAs
This is an interesting idea that I’ve never heard articulated before. Seems good in principle to have some people with fewer (or at least different to looking-after-their-org) vested interests.
Good shout @Will Aldred , I’ve changed it to not allow submitting only the quoted text
Good idea, I hadn’t thought of that! I’ve changed it to 10 like you suggested (will be deployed in ~10 mins at time of writing)
Update: The poll feature is now out!
We recently discovered that the “Posts added to tags I’m subscribed to” notification type was generating way too many notifications (as previously noted in this post).
This is partly because the signup flow used to nudge people to subscribe to these notifications. We’ve changed this now. I have also just gone in and reversed any subscriptions that were already created this way, as my guess is that the vast majority of people wouldn’t want them.
If you did like getting these notifications, you can resubscribe by going to the topic page and checking “Notify me of new posts” in the subscribe dropdown. You can also see which for which tags you have notifications turn on in this page under “Notification of New Posts with Tags” (the heading won’t appear if you don’t have any):
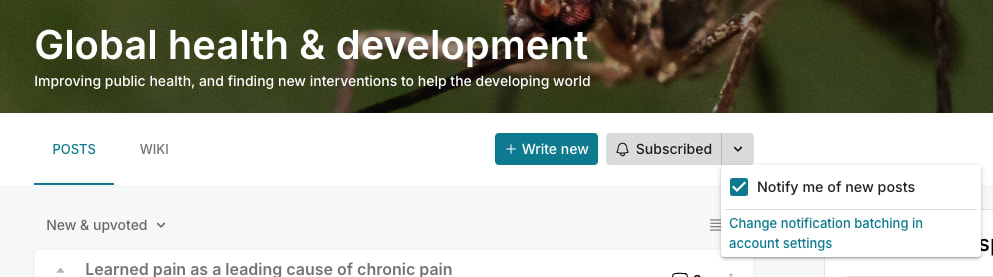
These are the topics affected (that are shown in the signup flow):
Can we keep that please?
Good news, this is a permanent feature, as careful followers of our donation election should already be well aware.

Hey, I just spot checked a few posts throughout the handbook and found that all of them have audio now 😌. Is there anywhere left in the handbook where audio is missing for you? I can coordinate with Type III to get them filled in if so (though I’m not sure if the missing audio you were seeing was a problem on their end or our end)