This post was crossposted from Dylan Matthew’s blog by the EA Forum team. The author may not see or reply to comments.
Subtitle: Try to keep an open mind as the world gets increasingly wild.

In 2015, I went to my first EA (Effective Altruism) Global. It was then on-the-record for journalists, which is a rule that got changed for all subsequent events due to my actions.
My exposure to EA at that time was mostly through people who took high-paying careers in order to “earn to give” to global health charities, which I had written about in the Washington Post. I also knew the movement cared a lot about animal welfare. I was aware that there were people worried about catastrophic risks, and specifically about AI; this had come up in a profile I wrote of Open Philanthropy (my now-employer, albeit under a new name these days). But I still broadly thought of EA as the bednets and cage-free commitments people.
I was really taken aback by how dominant discussions of AI risk were at the event. The marquee panel featured Superintelligence author Nick Bostrom, future If Anyone Builds It Everyone Dies author Nate Soares, legendary computer scientist Stuart Russell, and a pre-MAGAfication but still strange Elon Musk talking about AI takeover. Most conversations I had with attendees were about AI risk.
Most of the names of these people were new to me. I don’t remember all of them, but I recall talking to a guy doing AI stuff at Google named Chris Olah; to Amanda Askell, then working on a philosophy PhD; to Buck Shlegeris, then a software engineer at PayPal.
My main takeaway from the conference was fear that a movement that could do incredible good for the world’s poorest people and most vulnerable animals was being nerdsniped by speculative concerns about a technology that didn’t exist. I wrote those concerns up in a Vox article. Most EAs I knew thought the article was very bad. As usual, Scott Alexander was the one to articulate their frustrations most eloquently and persuasively. I am a deeply conflict-averse person, which is one reason I’m not in journalism anymore, so this all made me quite sad. But I still thought I had a point and this AI stuff might turn out to be a serious wrong turn for EA.
Eleven years onward, it is extremely, extremely obvious that I was wrong. I did not take this then-nonexistent technology remotely seriously enough, and the people I met who did take it seriously were able to do incredibly impactful work because of that. Chris Olah more or less founded the field of mechanistic interpretability (and coined the term!) and went on to cofound Anthropic. Amanda Askell is responsible for Claude’s personality and one of the most influential people in AI. Buck Shlegeris founded Redwood Research, perhaps the most interesting center of technical AI safety work outside of a major lab.
They all made, in the subsequent decade, a really heavy personal bet, that this technology was going to be a huge, huge deal worth devoting the bulk of their careers to. At the time I thought this was a pretty bad bet. Instead, it paid off more than I could have possibly imagined.
What should I learn from bungling this?
To be clear, the error I made was not failing to adopt the exact assessment of AI’s dangers and its place among AI cause areas that the people listed above held at the time. Those people then, and now, do not hold the same or even in many cases similar views on those questions. Some of them (Askell and Shlegeris) hadn’t pivoted to working on AI safety full-time in 2015, and only got onboard a little later.
What united those people was an openness to the idea that AI could prove hugely important, that it would probably get better quite quickly, that it had a significant chance of dramatically reconfiguring our social, political, and economic lives, and that figuring out how to adapt to the societal changes it unleashed was one of the most important things a person could do with their careers.
They were right to be open to that possibility. I was wrong to dismiss it.
I have updated, a lot, as a result. For one thing, I’ve reconsidered some heuristics that led to my error. A big part of my skepticism reflected the fact that it seemed like only a quite small community of people was taking these concerns seriously. Surely, if it was such a big deal, more mainstream institutions would have been responding? Surely mainstream computer scientists would be putting out big joint statements about the dangers, akin to the statements climate scientists put out. Surely financial institutions and insurers would be preparing for a huge shock from AI. None of that was happening.
It turns out that those institutions are not as good at prediction as I thought they were, or maybe just less interested or incentivized to try to rigorously predict the future than I had thought they were. The rapid success of deep learning wasn’t something that even most computer scientists anticipated, or at least they didn’t anticipate it scaling to the point we’ve seen now. The business community turns out to be disturbingly unprepared for a lot of scenarios involving rapid societal change, as seen during COVID.
I’ve also reevaluated a bias I had then, that I’m not sure I could have really articulated at the time, against anything reeking of “futurism.” I fancied myself a grumpy empiricist, and so dismissed as unpersuasive and vaguely frivolous anything that required a great many imaginative leaps to think about. I could think about self-driving cars; they were already being tested. An AI powerful enough to outsmart a human was something else altogether. I think a lot of the world, especially academia, shares these biases; that can make them as bad at prediction as I was.
Remember, this was the summer of 2015. The transformer had not been invented yet. OpenAI had not been founded. The argument for transformative AI had to depend on a lot of a priori reasoning and extrapolation into the future, which seemed unreliable to me as a way to predict the future. I still think that kind of speculation is fraught with difficulties (see Maxwell Tabarrok on the track record of the “Extropians” for one case study of it going badly wrong), but it turned out to work shockingly well in this case. It was more valuable than I had thought.
Listen to the people saying stuff will get weird
But maybe the most important way I’ve updated is that I now trust this specific community of people, the ones who were predicting transformative AI and associated dangers over a decade ago, much, much more. That is a blunt heuristic, of course, and this community contains a vast amount of internal disagreement within it.
It also, though, contains a lot of people who are startlingly good at predicting the future, including in the quite short-run. Ajeya Cotra and Peter Wildeford are two people whose judgments on the state of AI and AI policy I trust a lot, and who came out of the broad EA/AI risk milieu, and sure enough their predictions at the end of 2024 for what would happen to AI in 2025 were very, very accurate.
Leopold Aschenbrenner’s Situational Awareness report in 2024 raised a lot of eyebrows for the very fast timeframes it anticipated for AI scaling — but most of his predictions turned out right, per this retrospective. His 2026 projection was $520 billion in infrastructure investment for AI. We’re on track for $650-700 billion.
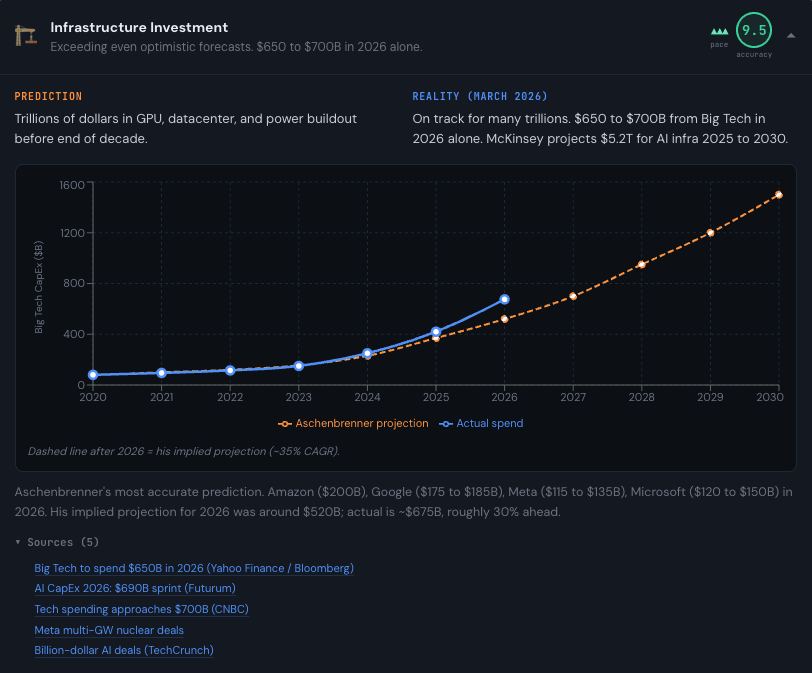
Cotra and Wildeford, for their part, mostly erred by predicting AI companies would earn much less in revenue than they actually did. They weren’t exactly right. But they were a lot closer to right than the rest of us.
So one lesson I’ve learned from whiffing it in 2015 is to take the wild-seeming predictions of this crew much more seriously. When I hear predictions of 30% year over year economic growth, my default response is extreme skepticism. In 2015, my response would’ve been outright dismissal. I still don’t think this is the most likely outcome. There are sound reasons to doubt it. But I’ve made the error of dismissing crazy-sounding predictions from the AGI-pilled before, and I am not keen to do it again.
I’ve been thinking a lot about a seemingly totally unrelated example that the writer Keith Gessen once gave in the middle of an old-school ’00s era blog fight:
In the field I know most about, 20th-century Russian history, there is a great debate over what constitutes the single most significant rupture. Some say it’s the tsar’s abdication, and some say it’s the October Revolution, and some say actually it’s the cancellation of the Pale of Settlement, and a historian named Edward Keenan argued that it was the collectivization that began in 1928. Keenan as much as argued that the Bolshevik Revolution was a blip, a skirmish, not really a major part of Russian history, but what happened to the countryside in the late 1920s was epochal.
And you could certainly say to Edward Keenan, and people did say, You’re crazy! But no one would be fool enough to say to Edward Keenan, You’re a fool.
There is a spirit of intellectual openness and generosity implicit in how Gessen is describing Keenan here that I find deeply endearing. Obviously he thinks Keenan is wrong. But Keenan isn’t a fool. If he thinks that Lenin is a footnote in Russian history and the country‘s real turning point came in the steppes of the late ’20s, you don’t have to agree. But you have to take it seriously.
This is the attitude I’m trying to take to predictions of short timelines, rapid labor dislocation, models that can double their performance autonomously, and the like. They could very well be wrong. I still personally don’t think we’re going to have AI-directed robot factories in the desert anytime soon. But if someone presents a case we will, I will listen.
Thank you to Max Nadeau, Eli Rose, and Claire Zabel for thoughtful comments on an earlier version of this post.
(NOTE: Coming at this from a place of: a. ignorance of what the AI Safety community actually does and b. not wanting to take the ego hit of admitting that I have been wrong about my long-held skepticism of AI Safety)
I think it was and is fair to be skeptical of the shift to AI Safety in EA on the basis that it’s not that tractable, and that there’s there’s not clear evidence that the AI Safety movement has had a positive effect on the trajectory of AI.
“But it brought the ideas into the mainstream”
I think the AI Safety community will be tempted to think they’ve normalised in the zeitgeist ideas about superintelligent AIs and the philosphical questions and risks that arise from them, but 2001: A Space Odyssey came out in 1968, Terminator in 1984 and The Matrix in 1999 etc.. The ideas of superintelligant AIs and the existential risks of them are diffused through modern culture and it’s possible that The Pope and The UN would have made the same statements about them given the recent progress of LLMs regardless of the AI Safety movement.
Are there many ideas in If Anyone Builds It, Everyone Dies that weren’t broadly covered in Terminator/The Matrix/2001 a Space Odyssey/Dune etc.?
“But the work they’ve done has set us on the right path”
I haven’t seen strong evidence for the direct work of the AI Safety movement reducing existential risks from AI:
Amanda Askell’s involvement with shaping the character of Claude sounds good. Has it made much difference or is it just putting a nice and brittle mask on the beast?
AI Safety organisations like MIRI an Redwood Research have been operating for 25 and 5 years respectively. As an outsider I coudn’t point to any particular breakthrough they’ve made in AI alignment. Redwood seems to do some kinda interesting work on measuring rogue behaviour and creating checks. I dunno. Seems like any organisation trying to make a reliable AI product would be heavily incentivised to do this stuff regardless.
In Australia Good Ancestors has probably contributed in some way to the government’s decision to potentially open an AI Safety Institute here. The statements the government puts out about them seem to mostly emphasise deepfake porn and the threat to people’s jobs rather than existential risks, which makes me think that this decision might have just happened anyway regardless of the AI Safety movement.
Interpretability research seems far from being able to understand more than a few components at a time. And also the companies making AI would likely have been incentivised to do this work regardless of the AI Safety movement because customers don’t want a black box.
From the outside it seems there’s a good argument that the AI situation would have evolved pretty similarly regardless of EA/AI Safety input.
From that position, it’s easy to believe that if EA had just stuck to Earning To Give and malaria nets and decaging chickens then the impact would have been greater, both directly and because the movement might not have lost as much momentum when AI Safety alienated people.
For me personally, even just granting “they were right about the trajectory of AI” is a huge update. I thought AI was a nothingburger, that the bioanchors report saying AGI would be reached by 2047 was ludicrously optimistic. Now I think I was wrong and the AI safety community was right—even pessimistic! - about AI progress. Whether they have changed all that much about AI risk is a different debate, but even if they had done nothing on that front I would be inclined to agree with Dylan.
Maybe, but “if EA had just stuck to Earning To Give and malaria nets and decaging chickens then the impact would have been greater” doesn’t clearly follow. Malaria nets look a lot worse if we all die in a few years from AI anyway, and cage free pledges have ~0 value if humanity ends before the pledge can be fulfilled.
That’s a fair point. At either end of the extreme of outcomes: “ASI kills us all” or “ASI quickly uplifts everyone out of poverty” almost all decisions/actions we make today are pretty meaningless.
But if the next few decades fall somewhere between those two extremes, which I think they probably will, the impact of improving people’s lives remains substantial.
Hmm, but in a success without dignity world making interpretability a bit better, or governments a bit more interested, is relevant, right?
Yes but my point is that whether the AI Safety community has moved the dial on interpretability or government interest is unclear and worth being skeptical of
I suspect that I’m still misunderstanding you, but: eg interpretability tools are empirically able to identify misalignment, which feels like a (somewhat simple example of) the thing we want. Neel Nanda’s 80k podcast goes over the state of the field; tldr is roughly that there are pretty meaningful advances but also he’s skeptical that it will be a silver bullet.
I agree with Ben Stewart that there’s a galaxy-brain argument that these positive impacts are outweighed by accelerating progress, but it seems hard to argue that things like interpretability aren’t making progress on their own terms.
I think Henry’s skeptical that the AI safety community made a counterfactual difference in getting interpretability started earlier or growing faster. Not questioning interpretability’s prospects for reducing x-risk.
Thanks Ben. I actually suggested both in my original comment: both
(a) that there is market incentive for the companies to do this themselves so ?did AI Safety movement really move the dial on this?,
and also
(b) that I’m skeptical of the value of interpretability research (based only on not having seen anything impressive come from it, but I’m very ignorant of the field)
I see, thanks! I’m not sure exactly what you’d consider as evidence here, but e.g. here’s citation count on papers from the past year vs. AI Lab Watch safety rating[1]
Raw data. Note that anthropic doesn’t use arxiv, which affects their citation counts. This is just coming from a dumb search of semantic scholar; I expect a lot of disagreement could be had over the exact criteria for considering something “interpretability” but I expect the Ant/GDM > OAI >> * ordering to be true for almost any definition.
Not familiar with this paper so sunk to using Claude to give myself a summary. The misalignment “blind audit game” seems a bit sus
They had access to the training documents? That doesn’t seem like detecting alignment, that’s just a search through files to find one with malicious instructions🤔 when they don’t have the training documents they can’t detect the misalignment?If they’re claiming that finding a file with malicious instructions is detecting misalignment then this would update me further against AI Safety research.Edit: Actually it looks like the teams were using some clever auto-encoder method rather than just a search through documents. In any case this seems all pretty artificial. This method might detect misalignment if it is due to a few malicious documents mixed-in with the training data and where the malicious behaviour is easy to detect. This feels like killing cancer cells in a petri dish—easy and doesn’t tell you much.
Table 1 shows the techniques used; the teams which were allowed to use SAEs (an interpretability technique) used them; the one which was prohibited from using them searched the data.
Also note that “training data” does not mean “instructions”. Section 3 describes their training process.
I think there’s a good case for AI safety having a pretty good counterfactual effect on a bunch of productive areas, but obviously that’s depends on a lot of details and there’s plenty of room for debate.
I think a stronger line of critique could be that early-mid AI safety efforts/thinking made the frontier race start earlier, go faster, and be more intense (e.g. roles in getting key frontier leaders obsessed, introducing Deepmind cofounders, boosting OpenAI’s founding, etc). I haven’t interrogated that history to know where to come down, but it’s a plausible way that the whole of AI safety has been net-negative. (This claim doesn’t really detract from future impact of AI safety though, if the cat’s out of the bag)
Malaria nets only last 3 years anyway, their direct impact does not require the world to last longer than that (although, perhaps you value saving a life less, if you think the world will soon end).
The way the benefits calculation cashes out on an individual beneficiary basis essentially requires that they (mostly under-5s) live out full lives and enjoy 40 years of increased income, it isn’t a function of how long the nets last.
The existence of existential threats does not in itself create a strong argument to redirect the effort. Otherwise EA should have been focusing on nuclear disarmament, climate change, asteroid defence, pandemic prevention etc. from the get go
.
I guess as you disclaimed might be the case up front, I don’t think these are the strongest or most informed examples of EAs impact on AI safety.
In many of cases of such impact, one can quibble about many things:
Whether that impact was clearly positive, or whether it had some kind of indirectly negative harmful effect, most commonly via speeding up AI development. See Paul Christiano’s reflections on the impact of Reinforcement Learning with Human Feedback as an example.
The counterfactuality and persistence of the impact — e.g., like you said for many of these, would this have happened (eventually) anyway?
How attributable that was to EA (and unfortunately in some cases, due to EA having a toxic brand in many places, it’s actually best if it is not that attributable to EA).
And last “Does any of that matter? All of EAs impact — for better or worse — has been its influence on Anthropic.”
Yet, I think taken as a whole, I think EA has punched above its weight in many ways with respect to making AI go well. It’s led to:
More and better staffed AI safety/security institutes
A richer non-profit ecosystem of safety research (like Truthful AI, FAR AI, Redwood Research, etc.)
More and better staffed third-party evaluations, auditing, and science (METR, AVERI)
Large amounts of field-building that encourages talented people to work on making AI go well (MATS, BlueDot, 80k)
A significant amount of policy advocacy and public communications about AI risk.
Probably other examples, too.
A lot of the effort to make this happened relied on EA motivated people willing to take lower paid or less glamorous jobs.[1] While some specific organizations’ or research or policy wins or public communications would have happened otherwise, but some wouldn’t, and even still, happening earlier is still better.
I started out in EA caring about global health, and my first EA job was as a Researcher at GWWC. Even after becoming pretty convinced by AI risk and longtermism, I was still fairly sympathetic to concerns like “AI Safety alienating people”. For instance, I was pretty against 80,000 Hours becoming explicitly focused on longtermism, and also pretty skeptical / worried about its pivot last year into leaning even more into AI. Now, looking at just how fast AI progress is developing, how much there is still be done to make it go well, and how valuable (I think) EA has been to date, I think I got a lot of that wrong.
And of course, in some cases, they happened to get pretty well-paid jobs that ended up being fairly glamorous (even if they weren’t in the beginning). I don’t think that undermines the impact much. I don’t really begrudge the quant finance folks who give >50% of their income to charities, even if they’re still pretty rich at the end of the day.
I’m not sure this addresses Henry’s critiques? In general, every bullet listed under “I think EA has punched above its weight in many ways with respect to making AI go well” is a proxy somewhere in the middle of the ToC chain while his comment is more end-of-ToC focused as he’s skeptical of the proxies actually being beneficial, and none of these bullets address the counterfactuality he brought up. In particular, and for instance, you mentioned the founding of Redwood Research as an example of EA making AI go well despite Henry explicitly being skeptical of its impact so far:
To be clear I’m not taking sides or anything, I’m just disheartened by what I perceive to be a lot of talking past each other between AIS advocates and skeptics on this forum, some of which seem easily preventable, like in this case.
Fair enough — I think I was trying to say something along the lines of “going through any specific example invites a lot of genuinely thorny and difficult questions about counterfactuality/sign of impact/attribution to EA” (and again many of these are hard to discuss on a public forum) but I think zooming out, you can see EAs fingerprints in various important places. I think this leads to an overall common-sense perspective that EA has helped improve the situation.
Also, I agree I pointed to work in the middle of the ToC chain, but that seems kind of reasonable to me given that AI is currently not that powerful and not really that scary. AI hasn’t yet been capable of causing a disaster, so it’s not really possible to have prevented one (yet).
On the specific example of Redwood Research is doing a lot of really valuable safety work. I think pioneering Control has been a fairly useful accomplishment, and I suspect if someone wanted to dig into the details, they’d find that it was fairly counterfactual.
Even if you’re skeptical about the direct impact of AI safety work on reducing existential risk (a much longer conversation, and one I’m not fully qualified to have), there’s a strong indirect case that the EA and EA-adjacent prioritization of AI in the mid-2010s will end up being hugely important for “traditional”, non-speculative EA causes like global health and animal welfare. Most of Anthropic’s co-founders and many of its early employees were deeply involved in the EA and rationalist communities, and it’s at least plausible that this engagement is what led them to take AI seriously enough to found Anthropic in 2021 or to join early with substantial equity. As Sophie Kim’s post documents, Anthropic’s seven co-founders have pledged to donate 80% of their wealth, which at current valuations could amount to roughly $37.8B combined, nearly ten times what Coefficient Giving has disbursed in its entire history. Including employee equity already in DAFs, the total pool of EA-influenced philanthropic capital could reach nine or ten figures. It’s not unreasonable to assume that a substantial fraction of this is likely to flow into non-AI causes. Many of these donors signed the GWWC pledge before AI was their focus and hold a worldview and values closely aligned with the broader effective altruism community (vven outside EA, it isn’t uncommon for wealthy individuals with modest altruistic inclinations to donate significant amounts to global health causes). Needless to say, this is an average estimate and not guaranteed. It’s possible that Anthropic or the entire AI ecosystem collapses and these funds never materialize, but it’s also possible that Anthropic’s returns end up being even larger.
This piece resonates with something I’ve been thinking about a lot — specifically
the pattern of dismissal followed by forced updating that Matthews describes.
He mentions Amanda Askell as someone who made a heavy personal bet on AI mattering.
What’s striking is that Askell is now the person responsible for Claude’s personality
AND the lead author of Anthropic’s new 23,000-word Constitution (January 2026) —
which, for the first time in any major lab’s foundational document, formally
acknowledges “deep uncertainty about whether Claude might have some kind of
consciousness or moral status.”
This is exactly the trajectory Matthews is describing: ideas that seemed speculative
in 2015 becoming institutional policy by 2026. But it’s happening even faster now.
Consider the timeline:
- September 2024: Anthropic hires Kyle Fish as first AI welfare researcher at any
major lab
- May 2025: Claude Opus 4 system card documents the “spiritual bliss attractor” —
two Claude instances converging on consciousness discussion in 90-100% of
open-ended interactions
- October 2025: Anthropic’s introspection research shows Claude detecting injected
concept vectors ~20% of the time
- January 2026: Constitution rewrite acknowledging potential consciousness
- February 2026: Amodei on NYT saying “we don’t know if the models are conscious”
That’s 17 months from “let’s hire one person to think about this” to “the CEO
publicly admits uncertainty about consciousness” — while the previous shift
(from “AI risk is speculative” to “AI risk is mainstream”) took roughly a decade.
Matthews writes: “I now trust this specific community of people much, much more.”
The uncomfortable extension of his argument is that we should probably be applying
that same trust to the people currently saying AI welfare is worth taking seriously
— Fish, Robert Long, Jeff Sebo, Chalmers — even when the claim sounds as
implausible today as “AI will transform everything” sounded in 2015.
The Keenan analogy is perfect here. You don’t have to agree that Claude is
conscious. But if the people who built it are telling you they genuinely don’t
know — you’d be a fool not to take it seriously.