Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks.
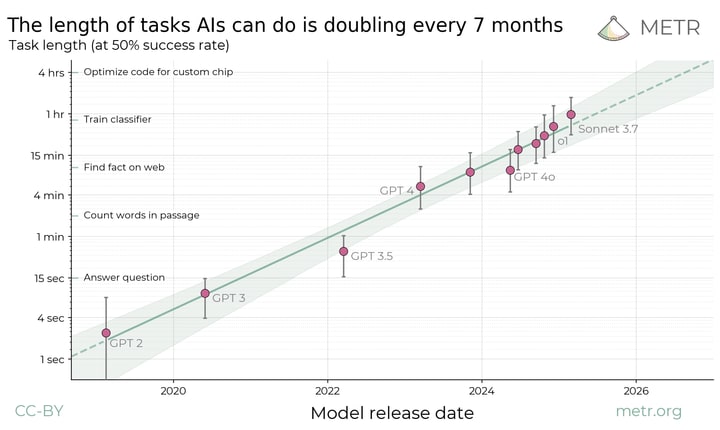
The length of tasks (measured by how long they take human professionals) that generalist frontier model agents can complete autonomously with 50% reliability has been doubling approximately every 7 months for the last 6 years. The shaded region represents 95% CI calculated by hierarchical bootstrap over task families, tasks, and task attempts.
On the one hand, this seems like not much (shouldn’t AGIs be able to hit ‘escape velocity’ and operate autonomously forever?), but on the other, being able to do a month’s worth of work coherently would surely get us close to recursive self-improvement.
Remember that this is graphing the length of task that the AI can do with an over 50% success rate. The length of task that an AI can do reliably is much shorter than what is shown here (you can look at figure 4 in the paper): for an 80% success rate it’s 30 seconds to a minute.
Being able to do a months work of work at a 50% success rate would be very useful and productivity boosting, of course, but it would really be close to recursive self improvement? I don’t think so. I feel that some part of complex projects needs reliable code, and that will always be a bottleneck.
Figure four averages across all models. I think figure six is more illuminating:
Basically, the 80% threshold is ~2 doublings behind the 50% threshold, or ~1 year. An extra year isn’t nothing! But you’re still not getting to 10+ year timelines.
The more task lengths the 80% threshold has to run through before it gets to task length we’d regard as AGI complete though, the more different the tasks at the end of the sequence are from the beginning, and therefore the more likely it is that the doubling trend will break down somewhere along the length of the sequence. That seems to me like the main significance of titotal’s point, not the time gained if we just assume the current 80% doubling trend will continue right to the end of the line. Plausibly 30 seconds to minute long tasks are more different from weeks long tasks than 15 minute tasks are.
Fair enough! My guess is that when the trend breaks it will be because things have gone super-exponential rather than sub-exponential (some discussion here) but yeah, I agree that this could happen!
Just so people know what you’re referring to, this is Figure 4:
Ben West noted in the blog post that
We think these results help resolve the apparent contradiction between superhuman performance on many benchmarks and the common empirical observations that models do not seem to be robustly helpful in automating parts of people’s day-to-day work: the best current models—such as Claude 3.7 Sonnet—are capable of some tasks that take even expert humans hours, but can only reliably complete tasks of up to a few minutes long.
This is probably the most important single piece of evidence about AGI timelines right now. Well done! I think the trend should be superexponential, e.g. each doubling takes 10% less calendar time on average. Eli Lifland and I did some calculations yesterday suggesting that this would get to AGI in 2028. Will do more serious investigation soon.
Why do I expect the trend to be superexponential? Well, it seems like it sorta has to go superexponential eventually. Imagine: We’ve got to AIs that can with ~100% reliability do tasks that take professional humans 10 years. But somehow they can’t do tasks that take professional humans 160 years? And it’s going to take 4 more doublings to get there? And these 4 doublings are going to take 2 more years to occur? No, at some point you “jump all the way” to AGI, i.e. AI systems that can do any length of task as well as professional humans -- 10 years, 100 years, 1000 years, etc.
Also, zooming in mechanistically on what’s going on, insofar as an AI system can do tasks below length X but not above length X, it’s gotta be for some reason—some skill that the AI lacks, which isn’t important for tasks below length X but which tends to be crucial for tasks above length X. But there are only a finite number of skills that humans have that AIs lack, and if we were to plot them on a horizon-length graph (where the x-axis is log of horizon length, and each skill is plotted on the x-axis where it starts being important, such that it’s not important to have for tasks less than that length) the distribution of skills by horizon length would presumably taper off, with tons of skills necessary for pretty short tasks, a decent amount necessary for medium tasks (but not short), and a long thin tail of skills that are necessary for long tasks (but not medium), a tail that eventually goes to 0, probably around a few years on the x-axis. So assuming AIs learn skills at a constant rate, we should see acceleration rather than a constant exponential. There just aren’t that many skills you need to operate for 10 days that you don’t also need to operate for 1 day, compared to how many skills you need to operate for 1 hour that you don’t also need to operate for 6 minutes.
There are two other factors worth mentioning which aren’t part of the above: One, the projected slowdown in capability advances that’ll come as compute and data scaling falters due to becoming too expensive. And two, pointing in the other direction, the projected speedup in capability advances that’ll come as AI systems start substantially accelerating AI R&D.
Is the point when models hit a length of time on the x-axis of the graph meant to represent the point where models can do all tasks of that length that a normal knowledge worker could perform on a computer? The vast majority of knowledge worker tasks of that length? At least one task of that length? Some particular important subset of tasks of that length?
I don’t quite get what that means. Do they really take exactly the same amount of time on all tasks for which they have the same success rate? Sorry, maybe I am being annoying here and this is all well-explained in the linked post. But I am trying to figure out how much this is creating the illusion that progress on it means a model will be able to handle all tasks that it takes normal human workers about that amount of time to do, when it really means something quite different.
Thanks for the question David! I expect that I can’t summarize this more simply than the paper does; particularly: section 4 goes into more detail on what the horizon means and section 8.1 discusses some limitations of this approach.
Section 4 is completely over my head I have to confess.
Edit: But the abstract gives me what I wanted to know :) : “To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate”
Reposting this from Daniel Eth:
On the one hand, this seems like not much (shouldn’t AGIs be able to hit ‘escape velocity’ and operate autonomously forever?), but on the other, being able to do a month’s worth of work coherently would surely get us close to recursive self-improvement.
Remember that this is graphing the length of task that the AI can do with an over 50% success rate. The length of task that an AI can do reliably is much shorter than what is shown here (you can look at figure 4 in the paper): for an 80% success rate it’s 30 seconds to a minute.
Being able to do a months work of work at a 50% success rate would be very useful and productivity boosting, of course, but it would really be close to recursive self improvement? I don’t think so. I feel that some part of complex projects needs reliable code, and that will always be a bottleneck.
Figure four averages across all models. I think figure six is more illuminating:
Basically, the 80% threshold is ~2 doublings behind the 50% threshold, or ~1 year. An extra year isn’t nothing! But you’re still not getting to 10+ year timelines.
The more task lengths the 80% threshold has to run through before it gets to task length we’d regard as AGI complete though, the more different the tasks at the end of the sequence are from the beginning, and therefore the more likely it is that the doubling trend will break down somewhere along the length of the sequence. That seems to me like the main significance of titotal’s point, not the time gained if we just assume the current 80% doubling trend will continue right to the end of the line. Plausibly 30 seconds to minute long tasks are more different from weeks long tasks than 15 minute tasks are.
So the claim is:
The 50% trend will break down at some length of task T
The 80% trend will therefore break at T/4
And maybe T is large enough to cause some catastrophic risk, but T/4 isn’t
?
Yes. (Though I’m not saying this will happen, just that it could, and that is more significant than a short delay.)
Fair enough! My guess is that when the trend breaks it will be because things have gone super-exponential rather than sub-exponential (some discussion here) but yeah, I agree that this could happen!
Just so people know what you’re referring to, this is Figure 4:
Ben West noted in the blog post that
More discussion on LessWrong.
Reposting this from Daniel Kokotajlo:
Is the point when models hit a length of time on the x-axis of the graph meant to represent the point where models can do all tasks of that length that a normal knowledge worker could perform on a computer? The vast majority of knowledge worker tasks of that length? At least one task of that length? Some particular important subset of tasks of that length?
As it says in the subtitle of the graph, it’s the length of task at which models have a 50% success rate.
I don’t quite get what that means. Do they really take exactly the same amount of time on all tasks for which they have the same success rate? Sorry, maybe I am being annoying here and this is all well-explained in the linked post. But I am trying to figure out how much this is creating the illusion that progress on it means a model will be able to handle all tasks that it takes normal human workers about that amount of time to do, when it really means something quite different.
Thanks for the question David! I expect that I can’t summarize this more simply than the paper does; particularly: section 4 goes into more detail on what the horizon means and section 8.1 discusses some limitations of this approach.
Section 4 is completely over my head I have to confess.
Edit: But the abstract gives me what I wanted to know :) : “To quantify the capabilities of AI systems in terms of human capabilities, we propose a new metric: 50%-task-completion time horizon. This is the time humans typically take to complete tasks that AI models can complete with 50% success rate”
This is going viral on X (2.8M views as of posting this comment).