On the way out of EA.
🔸 10% Pledger.
Likes pluralist conceptions of the good.
Dislikes Bay Culture being in control of the future.
On the way out of EA.
🔸 10% Pledger.
Likes pluralist conceptions of the good.
Dislikes Bay Culture being in control of the future.
Full disclosure—I read a draft of this piece and provided titotal with some feedback on it
Some high level reflections on this piece and interpreting the surrounding Debate:
I think this is an excellent piece, and I think well worth reading, especially for EAs who are tempted to easily defer to ‘high status’ organisations/individuals in the field of AI Safety. Having said that, I also think @elifland and @kokotajlod deserve a lot of credit for being open to criticism and working with titotal privately, and communicating in good faith here, on LW, titotal’s substack etc[1]
I think the piece shows that there are clear flaws with how the model is constructed, and that its design betrays the assumptions of those creating it. Of course this is a feature, not a bug, as it’s meant to be a formalisation of the beliefs of the AI2027 team (at least as I understand it). This is completely ok and even a useful exercise, but then I think nostalgebraist is accurate in saying that if you didn’t buy the priors/arguments for a near-term intelligence explosion before the model, then you won’t afterwards. The arguments for our assumptions, and how to interpret the data we have are ~the whole ball game, and not the quantitative forecasts/scenarios that they then produce.
I particularly want to draw attention to the ‘Six stories that fit the data’ section, because to my mind it demonstrates the core issue/epistemological crux. The whole field of AI Safety is an intense case of the underdetermination of theory given evidence,[2] and choosing which explanation of the world to go with given our limited experience of it is the key question of epistemology. But as titotal points out, a similar exercise to AI2027 could pick any one of those curves (or infinitely many alternatives) - the key points here are the arguments and assumptions underlying the models and how they clash.
Why the AI debates seem so intractable is a combination of:
We have limited data with which to constrain hypotheses (METR’s curve has 11 data points!)
The assumptions that underly the differences are based on pretty fundamental worldview differences and/or non-technical beliefs about how the world works—see AI as Normal Technology[3] or Ajeya Cotra’s appearance on the AI Summer Podcast
The lack of communication between the various ‘different camps’ involved in frontier AI and AI research contributes to misunderstandings, confrontational/adversarial stances etc.
The increased capability and saliency of AI in the world starting to lead to political polarisation effects which might make the above worse
Linked to 4, what happens with AI seems to be very high stakes. It’s not just opinions differ, but the range of what could happen is massive. There’s a lot at risk if actions are taken which are later proben to be misguided.
Given this epistemological backdrop, and the downward spiral in AI discourse over the last 2 years,[4] I don’t know how to improve the current state of affairs apart from ‘let reality adjudicate the winners’ - which often leaves me frustrated and demotivated. I’m thinking perhaps of adversarial collaborations between different camps, boosting collaborative AI Safety strategies, and using AI to help develop high-trust institutions.[5] But I don’t think exercise like AI2027 push the field forward because of the ‘peak forecasting’ involved, but instead by surfacing the arguments which underline the forecasts for scrutiny and falsification.
Though I think Alfredo Parra’s recent post is also worth bearing in mind
Though, tbf, all of human knowledge is. This problem isn’t unique to AI/AI Safety
Particularly ‘The challenge of policy making under uncertainty’ section
A spiral of which no side is blameless
If you’re interested in collaborating on/supporting any of the above, please reach out
I was going to reply with something longer here, but I think Gregory Lewis’ excellent comment highlights most of what I wanted to, r.e. titotal does actually give an alternative suggestion in the piece.
So instead I’ll counter two claims I think you make (or imply) in your comments here:
1. A shoddy toy model is better than no model at all
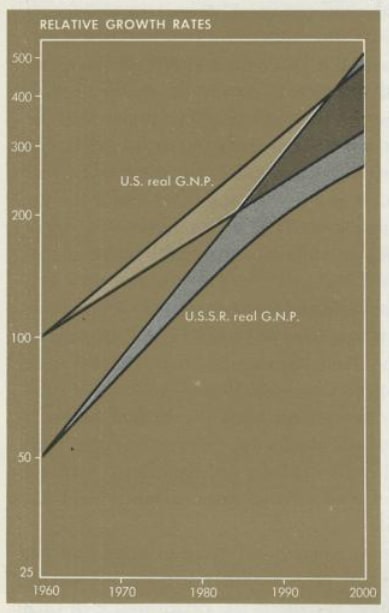
I mean this seems clearly not true, if we take model to be referring to the sort of formalised, quantified exercise similar to AI-2027. Some examples here might be Samuelson’s infamous predictions of the Soviet Union inevitably overtaking the US in GNP.[1] This was a bad model of the world, and even if it was ‘better’ than the available alternatives or came from a more prestigious source, it was still bad and I think worse than no model (again, defined as formal exercise ala AI2027).
A second example I can think of is the infamous Growth in a Time of Debt paper, which I remember being used to win arguments and justify austerity across Europe in the 2010s, being rendered much less convincing after an Excel error was corrected.[2]
TL;dr, as Thane said on LessWrong, we shouldn’t grade models on a curve
2. You need to base life decisions on a toy model
This also seems clearly false, unless we’re stretching “model” to mean simply “a reason/argument/justification” or defining “life decisions” narrowly as only those with enormous consequences instead of any ‘decision about my life’.
Even in the more serious cases, the role of models is to support presenting arguments for or against some decision or not, or to frame some explanation about the world, and of course simplification and quantification can be useful and powerful, but they shouldn’t be the only game in town. Other schools of thought are available.[3]
The reproduction paper turned critique is here, feels crazy that I can’t see the original data but the ‘model’ here seemed just to be spreadsheet of ~20 countries where the average only counted 15
Such as:
Make a decision based on the best explanation of the world
Go with common-sense heuristics since they likely encode knowledge gained from cultural evolution
As with many “p->q” arguments, I think this one is true for the trivial reason that q holds independent of p. I.e. it’s true that it’s unlikely that people will identify as EA’s one hundred years from now[1] but that also was unlikely 5 years ago.
This is a good and valid point for sure. I suppose that for the 4 failed movements I bring up in the post, they all failed to achieve their goals in their own terms and their ideas failed to influence other movements.[1] I think the q of ‘Effective Altruism ends as a movement’ is likely because the rate of dying out for all movements is 100%, just like it is for all living beings
So perhaps I want to distinguish between:
1) Movements that ‘die out’ because they succeed enough that their ideas permeate into the mainstream and outlive the initial social/intellectual movement
2) Movements that ‘die out’ because they lose enough reputation and support that nobody carries those ideas forward.
This would be different as well from:
3) The Movement’s goals eventually being realised
4) The Movement being a force for good in the world
So The Chartists might be an example of 2 & 3 - after the 1848 demostration they basically completely faded from power, but by 1918 5 out of 6 Chartist reforms had been implemented. It’s not clear to what extent the movement was causally responsible for this though
I think Revolutionary Marxism of various forms might be 1 & 4 - it was hugely popular in the late 19th and early 20th century even after Marx died, or the waning of power of explicitly Marxist parties, the ideas still had massive influence and can be casually traced to those intellectuals I think. I nevertheless think that their influence has been very negative for the world, but YMMV[2]
So I guess the underlying question is, if EA is in a prolonged or terminal decline (as in, we expect no early-Quaker style reforms to arrest the momentum, which is not guaranteed) then is it of form 1 or 2? I’m not sure, it’s an open question. I think conditioning on an SBF-scale reputational damage and subsequent ‘evaporate cooling’ of the movement since, the odds should have moved toward 2, but it’s not guaranteed for sure and it’d be interesting to see examples of which social movements match 1 vs 2.
There’s maybe some wiggle room around New Atheism/Technocracy, but the case is harder to make if you think they’re causally responsible
I don’t want to get into a huge debate about Marxism or not, it’s just the first thing that came to mind. If you are, you could just substitute ‘Revolutionary Marxism’ for ‘Neoliberal Capitalism’ of Hayek et al in the 20th century, which had a massively successful impact on the Reagan and Thatcher administrations, for instance
I’m going to actually disagree with your initial premise—the basic points are that the expected number of people in the future is much lower than longtermists estimate—because, at least in the Reflective Altruism blog series, I don’t see that as being the main objection David has to (Strong) Longtermism. Instead, I think he instead argues That the interventions Longtermists support require additional hypotheses (the time of perils) which are probably false and that the empirical evidence longtermists give for their existential pessimism are often non-robust on further inspection.[1] Of course my understanding is not complete, David himself might frame it differently, etc etc.
One interesting result from his earlier Existential risk pessimism and the time of perils paper is that on a simple model, though he expands the results to more complex ones, people with low x-risk should be longtermists about value, and those with high x-risk estimates should be focused on the short term, which is basically the opposite of what we see happening in real life. The best way out for the longtermist, he argues, is to believe in ‘the time of perils hypothesis’. I think the main appeals to this being the case are either a) interstellar colonisation giving us existential security so we’re moral value isn’t tethered to one planet,[2] or of course from b) aligned superintelligence allowing us unprecedented control over the universe and the ability to defuse any sources of existential risk. But of course, many working on Existential AI Risk are actually very pessimistic about the prospects for alignment and so, if they are longtermist,[3] why aren’t they retiring from technical AI Safety and donating to AMF? More disturbingly, are longtermists just using the ‘time of perils’ belief to backwards-justify their prior beliefs that interventions in things like AI are the utilitarian-optimal interventions to be supporting? I haven’t seen a good longtermist case answering these questions, which is not to say that one doesn’t exist.
Furthermore, in terms of responses from EA itself, what’s interesting is that when you look at the top uses of the Longtermism tag on the Forum, all of the top 8 were made ~3 years ago, and only 3 of the top 20 within the last 3 years. Longtermism isn’t a used a lot even amongst EA any more—the likely result of negative responses from the broader intelligensia during the 2022 soft launch, and then the incredibly toxic result of the FTX collapse shortly after the release of WWOTF. So while I find @trammell’s comment below illuminating in some aspects about why there might be fewer responses than expected, I think sociologically it is wrong about the overarching reasons—I think longtermism doesn’t have much momentum in academic philosophical circles right now. I’m not plugged into the GPI-Sphere though, so I could be wrong about this.
So my answer to your initial question is “no” if you mean ‘something big published post-Thorstad that responds directly or implicitly to him from a longtermist perspective’. Furthermore, were they to do so, or to point at one already done (like The Case for Strong Longtermism) I’d probably just reject many of the premises that give the case legs in the first place, such as that it’s reasonable to do risk-neutral-expected-value reasoning about the very long run future in the first place as a guide to moral action. Nevertheless, other objections to Longtermism I am sympathetic to are those from Eric Schwitzgebel (here, here) among others. I don’t think this is David’s perspective though, I think he believes that the empirical warrant for the claims aren’t there but that he would support longtermist policies if he believed they could be supported this way.
I’m also somewhat disturbed by the implication that some proportion of the EA Brain-Trust, and/or those running major EA/AI Safety/Biorisk organisations, are actually still committed longtermists or justify their work in longtermist terms. If so they should make sure this is known publicly and not hide it. If you think your work on AI Policy is justified on strong longtermist grounds, then I’d love to see your the model used for that, and parameters used for the length of the time of perils, the marginal difference to x-risk the policy would make, and the evidence backing up those estimates. Like if 80k have shifted to be AI Safety focused because of longtermist philosophical commitments, then lets see those commitments! The inability of many longtermist organisations to do that is a sign of what Thorstad calls the regression to the inscrutable,[4] which is I think one of his stronger critiques.
Disagreement about future population estimates would be a special case of the latter here
In The Epistemic Challenge to Longtermism, Tarsney notes that:
More concretely, the case for longtermism seems to depend to a significant
extent on the possibility of interstellar settlement
Note these considerations don’t apply to you if you’re not an impartial longtermist, but then again, if many people working in this area don’t count themselves as longtermists, it certainly seems like a poor sign for longtermism
Term coined in this blog post about WWOTF
A general good rule for life
(I am not a time-invariant-risk-neutral-totally-impartial-utilitarian, for instance)
No worries Ollie, thanks for the feedback :)
As I said, those bullet points were a memory of a draft so I don’t have the hard data to share on hand. But when dealing with social movements it’s always going to be somewhat vibesy—data will necessarily be observational and we can’t travel back in time and run RCTs on whether SBF commits fraud or not. And the case studies do show that declines can go on for a very long time post major crisis. It’s rare for movements to disappear overnight (The Levellers come closest of all the cases I found to that)
Fwiw I think that the general evidence does point to “EA is in decline” broadly understood, and that should be considered the null hypothesis at this point. I’d feel pretty gaslit if someone said EA was going swimmingly and unaffected by the tribulations of the last couple of years, perhaps less so if they think there’s been a bounce back after an initial decline but, you know, I’d want to see the data for that.
But as I said, it’s really not the (main) point of the post! I’d love to add my points to a post where someone did try and do a deep dive into that question.
Hey Ollie, thanks for your feedback! It helped me understand some of the downvotes the post was getting which I was a bit confused by. I think you and perhaps others are interpreting the post as “Here are some case studies that show EA is in decline”, but that’s not what I was trying to write, it was more “EA is in decline, what historical cases can inform us about this?” I’m not really arguing for “Is EA in decline?” in the post, in fact I’m just assuming it and punting the empirical evidence for another time, since I was interested in bringing out the historical cases rather than EAs current state. So the tweets are meant to be indicative of mood/sentiment but not load bearing proof. I do see that the rhetorical flourish in the intro might have given a misleading impression, so I will edit that to make the point of the piece more clear.
As for why, I mean, it does just seem fairly obvious to me, but social movements have fuzzy boundaries and decline doesn’t have to be consistent. Nevertheless answering this question was a post I was planning on write and the evidence seemed fairly damning to me—for instance:
Spikes in visiting the “Effective Altruism” Wikipedia page seem to mainly be in response to negative media coverage, such as the OpenAI board fallout or a Guardian Article about Wytham Abbey. Other Metrics like Forum engagement that were growing preFTX clearly spike and decline after the scandal period.
Other organisations similar to EA considering rebounding away. Apparently CE/AIM was considering this, and Rutger Bregman seems to be trying really hard to keep Moral Ambition free of EAs reputational orbit, which I think he’d be doing much less of if EAs prospects were more positive.
Previous community members leaving the Forum or EA in general, sometimes turning quite hostile to it. Some examples here are Habryka, Nuño Sempere, Nathan Young, Elizabeth from the more ‘rationalist’ side. I’ve noticed various people who were long term EAs, like Akash Wasil and John Halstead have deactivated their accounts. A lot of more left-wing EAs like Bob Jacobs seem to have started to move away too, or like Habiba moderate their stanc and relationship to EA.
This goes double so for leadership. I think loads kf the community felt a leadership vacuum post FTX. Dustin has deactivated his account. Holden has left OP, gone quiet, and might not longer consider himself EA? Every so often Ben Todd tweets something which I can only interpret as “testing the waters before jumping ship”. I don’t think leadership of a thriving, growing movement acts this.
If you search “Effective Altruism” on almost any major social media site (X, Bluesky, Reddit, etc) I suspect the general sentiment toward EA will be strongly negative and probably worse than it was preFTX and staying that way. There might be some counter evidence. Some metrics might have improved, and I know some surveys are showing mixed or positive things. I think Habryka’s point that reputation is evaluated lazily rings true to me even if I disagree on specifics.
But again, the above is my memory of a draft, and I’m not sure I’ll ever finish that post. I think hard data on a well formed version of the question would be good, but once again it’s not the question I was trying to get at with this post.
Some Positions In EA Leadership Should Be Elected
If we take this literally, then ‘some’ means ‘any at all’, and I think that the amount of democratic input is >0 so this should be 100% yes.
Having said that, I think the bar is kind-of acting as a ‘how much do you support democratising EA’, and in that sense while I do support Cremer-style reforms, I think they’re best introduced at a small scale to get a track record.
I wish this post—and others like it—had more specific details when it comes to these kind of criticisms, and had a more specific statement of what they are really taking issue with, because otherwise it sort of comes across as “I wish EA paid more attention to my object-level concerns” which approximately ~everyone believes.
If the post it’s just meant to represent your opinions thats perfectly fine, but I don’t really think it changed my mind on its own merits. I also just don’t like withholding private evidence, I know there are often good reasons for it, but it means I just can’t give much credence to it tbqh. I know it’s a quick take but still, it left me lacking in actually evaluating.
I general this discussion reminds me a bit of my response to another criticism of EA/Actions by the EA Community, and I think what you view as ‘sub-optimal’ actions are instead best explained by people having:
bounded rationality and resources (e.g. You can’t evaluate every cause area, and your skills might not be as useful across all possible jobs)
different values/moral ends (Some people may not be consequentialists at all, or prioritise existing vs possible people difference, or happiness vs suffering)
different values in terms of process (e.g. Some people are happy making big bets on non-robust evidence, others much less so)
And that, with these constraints accepted, many people are not actually acting sub-optimally given their information and values (they may later with hindsight regret their actions or admit they were wrong, of course)
Some specific counterexamples:
Being insufficiently open-minded about which areas and interventions might warrant resources/attention, and unwarranted deference to EA canon, 80K, Open Phil, EA/rationality thought leaders, etc. - I think this might be because of resource constraints, or because people disagree about what interventions are ‘under invested’ vs ‘correctly not much invested in’. I feel like you just disagree with 80K & OpenPhil on something big and you know, I’d have liked you to say what that is and why you disagree with them instead of dancing around it.
Attachment to feeling certainty, comfort and assurance about the ethical and epistemic justification of our past actions, thinking, and deference—What decisions do you mean here? And what do you even mean by ‘our’? Surely the decisions you are thinking of apply to a subset of EAs, not all of EA? Like this is probably the point that most needed something specific.
Trying to read between the lines—I think you think the AGI is going to be a super big deal soon, and that its political consequences might be the most important and consequently political actions might be the most important ones to take? But OpenPhil and 80K haven’t been on the ball with political stuff and now you’re disillusioned? And people in other cause areas that aren’t AI policy should presumably stop donating there and working their and pivot? I don’t know, it doesn’t feel accurate to me,[1] but like I can’t get a more accurate picture because you just didn’t provide any specifics for me to tune my mental model on 🤷♂️
Even having said all of this, I do think working on mitigating concentration-of-power-risks is a really promising direction for impact and wish you the best in pursuing it :)
As in, i don’t think you’d endorse this as a fair or accurate description of your views
Note—this was written kinda quickly, so might be a bit less tactful than I would write if I had more time.
Making a quick reply here after binge listening to three Epoch-related podcasts in the last week, and I basically think my original perspective was vindicated. It was kinda interesting to see which points were repeated or phrased a different way—would recommend if your interested in the topic.
The initial podcast with Jaime, Ege, and Tamay. This clearly positions the Epoch brain trust as between traditional academia and the AI Safety community (AISC). tl;dr—academia has good models but doesn’t take ai seriously, and AISC the opposite (from Epoch’s PoV)
The ‘debate’ between Matthew and Ege. This should have clued people in, because while full of good content, by the last hour/hour and half it almost seemed to turn into ‘openly mocking and laughing’ at AISC, or at least the traditional arguments. I also don’t buy those arguments, but I feel like the reaction Matthew/Ege have shows that they just don’t buy the root AISC claims.
The recent podcast Dwarkesh with Ege & Tamay. This is the best of the 3, but probably also best listened too after the first too, since Dwarkesh actually pushes back on quite a few claims, which means Ege & Tamay flush out their views more—personal highlight was what the reference class for AI Takeover actually means.
Basically, the Mechanize cofounders don’t agree at all with ‘AI Safety Classic’, I am very confident that they don’t buy the arguments at all, that they don’t identify with the community, and somewhat confident that they don’t respect the community or its intellectual output that much.
Given that their views are: a) AI will be a big deal soon (~a few decades), b) returns to AI will be very large, c) Alignment concerns/AI risks are overrated, and d) Other people/institutions aren’t on the ball, then starting an AI Start-up seems to make sense.
What is interesting to note, and one I might look into in the future, is just how much these differences in expectation of AI depend on differences in worldview, rather than differences in technical understanding of ML or understanding of how the systems work on a technical level.
So why are people upset?
Maybe they thought the Epoch people were more part of the AISC than they actually were? Seems like the fault of the people believe this, not Epoch or the Mechanize founders.
Maybe people are upset that Epoch was funded by OpenPhil, and this seems to have lead to ‘AI acceleration’? I think that’s plausible, but Epoch has still produced high-quality reports and information, which OP presumably wanted them to do. But I don’t think equating EA == OP, or anyone funded by OP, is a useful concept to me.
Maybe people are upset at any progress in AI capabilities. But that assumes that Mechanize will be successful in its aims, not guaranteed. It also seems to reify the concept of ‘capabilities’ as one big thing which i don’t think makes sense. Making a better Stockfish, or a better AI for FromSoft bosses does not increase x-risk, for instance.
Maybe people think that the AI Safety Classic arguments are just correct and therefore people taking actions other than it. But then many actions seem bad by this criteria all the time, so odd this would provoke such a reaction. I also don’t think EA should hang its hat on ‘AI Safety Classic’ arguments being correct anyway.
Probably some mix of it. I personally remain not that upset because a) I didn’t really class Epoch as ‘part of the community’, b) I’m not really sure I’m ‘part of the community’ either and c) my views are at least somewhat similar to the Epoch set above, though maybe not as far in their direction, so I’m not as concerned object-level either.
I’m not sure I feel as concerned about this as others. tl;dr—They have different beliefs from Safety-concerned EAs, and their actions are a reflection of those beliefs.
It seems broadly bad that the alumni from a safety-focused AI org
Was Epoch ever a ‘safety-focused’ org? I thought they were trying to understand what’s happening with AI, not taking a position on Safety per se.
…have left to form a company which accelerates AI timelines
I think Matthew and Tamay think this is positive, since they think AI is positive. As they say, they think explosive growth can be translated into abundance. They don’t think that the case for AI risk is strong, or significant, especially given the opportunity cost they see from leaving abundance on the table.
Also important to note is what Epoch boss Jaime says in this very comment thread.
As I learned more and the situation unfolded I have become more skeptical of AI Risk.
The same thing seems to be happening with me, for what it’s worth.
People seem to think that there is an ‘EA Orthodoxy’ on this stuff, but there either isn’t as much as people think, or people who disagree with it are no longer EAs. I really don’t think it makes sense to clamp down on ‘doing anything to progress AI’ as being a hill for EA to die on.
Note: I’m writing this for the audience as much as a direct response
The use of Evolution to justify this metaphor is not really justified. I think Quintin Pope’s Evolution provides no evidence for the sharp left turn (which won a prize in an OpenPhil Worldview contest) convincingly argues against it. Zvi wrote a response from the “LW Orthodox” camp that wasn’t convincing and Quintin responds against it here.
On “Inner vs Outer” framings for misalignment is also kinda confusing and not that easy to understand when put under scrutiny. Alex Turner points this out here, and even BlueDot have a whole “Criticisms of the inner/outer alignment breakdown” in their intro which to me gives the game away by saying “they’re useful because people in the field use them”, not because their useful as a concept itself.
Finally, a lot of these concerns revolve around the idea of their being set, fixed, ‘internal goals’ that these models have, and represent internally, but are themselves immune from change, or can hide from humans, etc. This kind of strong ‘Goal Realism’ is a key part of the case for ‘Deception’ style arguments, whereas I think Belrose & Pope show an alternative way to view how AIs work is ‘Goal Reductionism’, in which framing the issues imagined don’t seem certain any more, as AIs are better understood as having ‘contextually-activated heuristics’ rather than Terminal Goals. For more along these lines, you can read up on Shard Theory.
I’ve become a lot more convinced about these criticisms of “Alignment Classic” by diving into them. Of course, people don’t have to agree with me (or the authors), but I’d highly encourage EAs reading the comments on this post to realise Alignment Orthodoxy is not uncontested, and is not settled, and if you see people making strong cases based on arguments and analogies that seem not solid to you, you’re probably right, and you should look to decide for yourself rather than accepting that the truth has already been found on these issues.[1]
And this goes for my comments too
I’m glad someone wrote this up, but I actually don’t see much evaluation here from you, apart from “it’s too early to say”, but then Zhou Enlai pointed out that you could say that about the French Revolution,[1] and I think we can probably say some things. I generally have you mapped to the “right-wing Rationalist” subgroup Arjun,[2] so it’d be actually interested to get your opinion instead of trying to read between the lines on what you may or may not believe. I think there was a pretty strong swing in Silicon Valley / Tech Twitter & TPOT / Broader Rationalism towards Trump, and I think this isn’t turning out well, so I’d actually be interested to see people saying what they actually think—be that “I made a huge mistake”, “It was a bad gamble but Harris would’ve been worse” or even “This is exactly what I want”
Hey Cullen, thanks for responding! So I think there are object-level and meta-level thoughts here, and I was just using Jeremy as a stand-in for the polarisation of Open Source vs AI Safety more generally.
Object Level—I don’t want to spend too long here as it’s not the direct focus of Richard’s OP. Some points:
On ‘elite panic’ and ‘counter-enlightenment’, he’s not directly comparing FAIR to it I think. He’s saying that previous attempts to avoid democratisation of power in the Enlightenment tradition have had these flaws. I do agree that it is escalatory though.
I think, from Jeremy’s PoV, that centralization of power is the actual ballgame and what Frontier AI Regulation should be about. So one mention on page 31 probably isn’t good enough for him. That’s a fine reaction to me, just as it’s fine for you and Marcus to disagree on the relative costs/benefits and write the FAIR paper the way you did.
On the actual points though, I actually went back and skim-listened to the the webinar on the paper in July 2023, which Jeremy (and you!) participated in, and man I am so much more receptive and sympathetic to his position now than I was back then, and I don’t really find Marcus and you to be that convincing in rebuttal, but as I say I only did a quick skim listen so I hold that opinion very lightly.
Meta Level -
On the ‘escalation’ in the blog post, maybe his mind has hardened over the year? There’s probably a difference between ~July23-Jeremy and ~Nov23Jeremy, which he may view as an escalation from the AI Safety Side to double down on these kind of legislative proposals? While it’s before SB1047, I see Wiener had introduced an earlier intent bill in September 2023.
I agree that “people are mad at us, we’re doing something wrong” isn’t a guaranteed logic proof, but as you say it’s a good prompt to think “should i have done something different?”, and (not saying you’re doing this) I think the absolutely disaster zone that was the sB1047 debate and discourse can’t be fully attributed to e/acc or a16z or something. I think the backlash I’ve seen to the AI Safety/x-risk/EA memeplex over the last few years should prompt anyone in these communities, especially those trying to influence policy of the world’s most powerful state, to really consider Cromwell’s rule.
On this “you will just in fact have pro-OS people mad at you, no matter how nicely your white papers are written.” I think there’s some sense in which it’s true, but I think that there’s a lot of contigency about just how mad people get, how mad they get, and whether other allies could have been made on the way. I think one of the reasons they got so bad is because previous work on AI Safety has understimated the socio-political sides of Alignment and Regulation.[1]
Again, not saying that this is referring to you in particular
I responded well to Richard’s call for More Co-operative AI Safety Strategies, and I like the call toward more sociopolitical thinking, since the Alignment problem really is a sociological one at heart (always has been). Things which help the community think along these lines are good imo, and I hope to share some of my own writing on this topic in the future.
Whether or not I agree with Richard’s personal politics or not is kinda beside the point to this as a message. Richard’s allowed to have his own views on things and other people are allowed to criticse this (I think David Mathers’ comment is directionally where I lean too). I will say that not appreciating arguments from open-source advocates, who are very concerned about the concentration of power from powerful AI, has lead to a completely unnecessary polarisation against the AI Safety community from it. I think, while some tensions do exist, it wasn’t inevitable that it’d get as bad as it is now, and in the end it was a particularly self-defeating one. Again, by doing the kind of thinking Richard is advocating for (you don’t have to co-sign with his solutions, he’s even calling for criticism in the post!), we can hopefully avoid these failures in the future.
On the bounties, the one that really interests me is the OpenAI board one. I feel like I’ve been living in a bizarro-world with EAs/AI Safety People ever since it happened because it seemed such a collosal failure, either of legitimacy or strategy (most likely both), and it’s a key example of the “un-cooperative strategy” that Richard is concerned about imo. The combination of extreme action and ~0 justification either externally or internally remains completely bemusing to me and was big wake-up call for my own perception of ‘AI Safety’ as a brand. I don’t think people can underestimate the second-impact effect this bad on both ‘AI Safety’ and EA, coming about a year after FTX.
Piggybacking on this comment because I feel like the points have been well-covered already:
Given that the podcast is going to have a tigher focus on AGI, I wonder if the team is giving any considering to featuring more guests who present well-reasoned skepticism toward 80k’s current perspective (broadly understood). While some skeptics might be so sceptical of AGI or hostile to EA they wouldn’t make good guests, I think there are many thoughtful experts who could present a counter-case that would make for a useful episode(s).
To me, this comes from a case for epistemic hygiene, especially given the prominence that the 80k podcast has. To outside observers, 80k’s recent pivot might appear less as “evidence-based updating” and more as “surprising and suspicious convergence” without credible demonstrations that the team actually understands opposing perspectives and can respond to the obvious criticisms. I don’t remember the podcast featuring many guests who present a counter-case to 80ks AGI-bullishness as opposed to marginal critiques, and I don’t particularly remember those arguments/perspectives being given much time or care.
Even if the 80k team is convinced by the evidence, I believe that many in both the EA community and 80k’s broader audience are not. From a strategic persuasion standpoint, even if you believe the evidence for transformative AI and x-risk is overwhelming, interviewing primarily those already also convinced within the AI Safety community will likely fail to persuade those who don’t already find that community credible. Finally, there’s also significant value in “pressure testing” your position through engagement with thoughtful critics, especially if your theory of change involves persuading people who are either sceptical themselves or just unconvinced.
Some potential guests who could provide this perspective (note, I don’t these 100% endorse the people below, but just that they point the direction of guests that might do a good job at the above):
Melanie Mitchell
François Chollet
Kenneth Stanley
Tan Zhi-Xuan
Nora Belrose
Nathan Lambert
Sarah Hooker
Timothy B. Lee
Krishnan Rohit
I don’t really get the framing of this question.
I suspect, for any increment of time one could take through EAs existence, then there would have been more ‘harm’ done in the total rest of world during that time. EA simply isn’t big enough to counteract the moral actions of the rest of the world. Wild animals suffer horribly, people die of preventable diseases etc constantly, formal wars and violent struggles occur affecting the lives of millions. There sheer scale of the world outweighs EA many, many times over.
So I suspect you’re making a more direct comparison to Musk/DOGE/PEPFAR? But again, I feel like anyone wielding using the awesome executive power of the United States Government should expect to have larger impacts on the world than EA.
I think this is downstream of a lot of confusion about what ‘Effective Altruism’ really means, and I realise I don’t have a good definition any more. In fact, because all of the below can be criticised, it sort of explains why EA gets seemingly infinite criticism from all directions.
Is it explicit self-identification?
Is it explicit membership in a community?
Is it implicit membership in a community?
Is it if you get funded by OpenPhilanthropy?
Is it if you are interested or working in some particular field that is deemed “effective”?
Is it if you believe in totalising utilitarianism with no limits?
To always justify your actions with quantitative cost-effectiveness analyses where you’re chosen course of actions is the top ranked one?
Is it if you behave a certain way?
Because in many ways I don’t count as EA based off the above. I certainly feel less like one than I have in a long time.
For example:
I think a lot of EAs assume that OP shares a lot of the same beliefs they do.
I don’t know if this refers to some gestalt ‘belief’ than OP might have, or Dustin’s beliefs, or some kind of ‘intentional stance’ regarding OP’s actions. While many EAs shared some beliefs (I guess) there’s also a whole range of variance within EA itself, and the fundamental issue is that I don’t know if there’s something which can bind it all together.
I guess I think the question should be less “public clarification on the relationship between effective altruism and Open Philanthropy” and more “what does ‘Effective Altruism’ mean in 2025?”
I mean I just don’t take Ben to be a reasonable actor regarding his opinions on EA? I doubt you’ll see him open up and fully explain a) who the people he’s arguing with are or b) what the explicit change in EA to an “NGO patronage network” was with names, details, public evidence of the above, and being willing to change his mind to counter-evidence.
He seems to have been related to Leverage Research, maybe in the original days?[1] And there was a big falling out there, any many people linked to original Leverage hate “EA” with the fire of a thousand burning suns. Then he linked up with Samo Burja at Bismarck Analysis and also with Palladium, which definitely links him the emerging Thielian tech-right, kinda what I talk about here. (Ozzie also had a good LW comment about this here).
In the original tweet Emmett Shear replies, and then it’s spiralled into loads of fractal discussions, and I’m still not really clear what Ben means. Maybe you can get more clarification in Twitter DMs rather than having an argument where he’ll want to dig into his position publicly?
For the record, a double Leverage & Vassar connection seems pretty disqualifying to me—especially as i’m very Bay sceptical anyway
On Stepping away from the Forum and “EA”
I’m going to stop posting on the Forum for the foreseeable future[1]. I’ve learned a lot from reading the Forum as well as participating in it. I hope that other users have learned something from my contributions, even if it’s just a sharper understanding of where they’re right and I’m wrong! I’m particularly proud of What’s in a GWWC Pin? and 5 Historical Case Studies for an EA in Decline.
I’m not deleting the account so if you want to get in touch the best way is probably DM here with an alternative way to stay in contact. I’m happy to discuss my reasons for leaving in more detail,[2] or find ways of collaborating on future projects.[3]
I don’t have the data to hand but I’d guess I’m probably one of the higher percentile Forum users in recent years, so why such a seemingly sudden change? The reason is that it’s less a relation to the Forum and more due to my decision to orient away from “EA” in my life—and being consistent there means stepping away from the Forum. I could write a whole post on the reasons I have for not feeling ‘EA’, but some paragraph summaries are:
I don’t really know what “EA” means anymore: There’s always been a tension between the ‘philosophy or movement’ framings of EA, so in practice it’s been used as a fuzzy label for sets of ideas or people. In practice, “EA” seems to have been defined by its enemies for the past ~2.5 years, though I know CEA seems to change this. But I think this lack of clarity is actually a sign that EA doesn’t really have a coherent identity at the moment. It doesn’t seem right to strongly associate with something I can’t clearly define.
I have increasing differences with ‘philosophical’ EA (as I understand it): This difference has been growing recently, and it’s a fairly long list of which I’ll only include a few things. I think viewing morality as about ‘the best’ instead of ‘doing right’ is a mistake, especially if the former leads to viewing morality as about global/perspectiveless maximisation.[4] I’m a virtue ethicist and not a consequentialist/utilitarian. I think my special relationships to others in my life create important and partial moral obligations/duties. I don’t think Expected Value is the only or best way to make decisions for individuals or institutions. I think cluelessness/Knightian uncertainty arguments defeat most of the cases for longtermism in practice. The various differences I have seem significant enough that I can’t really claim to be EA philosophically unless ‘EA’ is drawn arbitrarily and trivially wide.
I also don’t feel connected to the ‘movement’ side of EA either: I’m not personally or socially connected to much of EA. My friends and close personal relationships are not related to EA. While I’m more professionally involved with AI Safety than before, I also make clear that my positions are fairly unorthodox in this space too. While I’ve done my own bit of defending EA on and off the Forum, I no longer feel the identification or need to. So I’m starting to leave the various online EA spaces I am a part of one-by-one.[5] Given my limited connection to EA personally or philosophically, it seems odd to be part of the movement in ways that imply I’m giving it more support than I actually do.
I think there are better ways for me to spend my time than engaging with EA: In the last ~6 months EA engagement hasn’t made me happy. This has often been from seeing EA criticisms left unresponded to, and I don’t want to be associated with something society views negatively if I don’t support that thing! I also think that there are more interesting and fulfilling pathways for my life to pursue which are either orthogonal to EA, or outside the ‘orthodoxy’ of cause areas/interventions. Finally, I just think I spend too much time reading the Forum or EA Twitter, and going cold turkey would be a good way to reallocate my attention better. I don’t think that the ‘right’ thing for me to do in terms of doing the right thing, or for personal flourishing, is to engage with EA.
Overall Takeaway: I never really claimed the label ‘EA’ for myself—it was never the basis of my identity and I’ve never really had the ‘taking ideas seriously’ genie take over my life. But I think, given my differences, I want to put clearer distance between me and EA into the future.
Anyway, that turned out to be a fair bit longer than I intended! If you made to the end, then I wish you all the best in your future endeavours 👋[6]
Definitely ‘for now’, but possibly for longer. I haven’t quite decided yet.
Though see below first
See the end of this comment for some ideas
Indeed, from a certain point of view EA could be seen as a philosophical version of Bostrom’s paperclip monster. If there is a set definition of the good, and you want to maximise, then the right thing to do is paperclip the universe with your definition. My core commitment to pluralism views this as wrong, and makes me deeply suspicious of any philosophy which allows this, or directionally points towards it
I do, however, intend to continue with the GWWC Pledge for the foreseeable future
I also wish you the best if you didn’t