I am a research analyst at the Center on Long-Term Risk.
I’ve worked on grabby aliens, the optimal spending schedule for AI risk funders, and evidential cooperation in large worlds.
Some links
I am a research analyst at the Center on Long-Term Risk.
I’ve worked on grabby aliens, the optimal spending schedule for AI risk funders, and evidential cooperation in large worlds.
Some links
Thanks for putting it together! I’ll give this a go in the next few weeks :-)
In the past I’ve enjoyed doing the YearCompass.
Thanks!
And thanks for the suggestion, I’ve created a version of the model using a Monte Carlo simulation here :-)
This is a short follow up to my post on the optimal timing of spending on AGI safety work which, given exact values for the future real interest, diminishing returns and other factors, calculated the optimal spending schedule for AI risk interventions.
This has also been added to the post’s appendix and assumes some familiarity with the post.
Here I consider the most robust spending policies and supposes uncertainty over nearly all parameters in the model[1] Inputs that are not considered include: historic spending on research and influence, rather than finding the optimal solutions based on point estimates and again find that the community’s current spending rate on AI risk interventions is too low.
My distributions over the the model parameters imply that
Of all fixed spending schedules (i.e. to spend X% of your capital per year[2]), the best strategy is to spend 4-6% per year.
Of all simple spending schedules that consider two regimes: now until 2030, 2030 onwards, the best strategy is to spend ~8% per year until 2030, and ~6% afterwards.
I recommend entering your own distributions for the parameters in the Python notebook here[3]. Further, these preliminary results use few samples: more reliable results would be obtained with more samples (and more computing time).
I allow for post-fire-alarm spending (i.e., we are certain AGI is soon and so can spend some fraction of our capital). Without this feature, the optimal schedules would likely recommend a greater spending rate.
Caption: Simple - two regime - spending rate
The system of equations—describing how a funder’s spending on AI risk interventions change the probability of AGI going well—are unchanged from the main model in the post.
This version of the model randomly generates the real interest, based on user inputs. So, for example, one’s capital can go down.
Caption: An example real interest function , cherry picked to show how our capital can go down significantly. See here for 100 unbiased samples of .
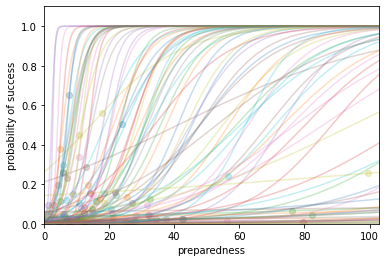
Caption: Example probability-of-success functions. The filled circle indicates the current preparedness and probability of success.
Caption: Example competition functions. They all pass through (2022, 1) since the competition function is the relative cost of one unit of influence compared to the current cost.
This short extension started due to a conversation with David Field and comment from Vasco Grilo; I’m grateful to both for the suggestion.
Inputs that are not considered include: historic spending on research and influence, the rate at which the real interest rate changes, the post-fire alarm returns are considered to be the same as the pre-fire alarm returns.
And supposing a 50:50 split between spending on research and influence
This notebook is less user-friendly than the notebook used in the main optimal spending result (though not un user friendly) - let me know if improvements to the notebook would be useful for you.
The intermediate steps of the optimiser are here.
Previously the benefactor has been Carl Shulman (and I’d guess he is again, but this is pure speculation). From 2019-2020 donor lottery page:
Carl Shulman will provide backstop funding for the lotteries from his discretionary funds held at the Centre for Effective Altruism.
The funds mentioned are likely these $5m from March 2018:
The Open Philanthropy Project awarded a grant of $5 million to the Centre for Effective Altruism USA (CEA) to create and seed a new discretionary fund that will be administered by Carl Shulman
I’ll be giving to the EA Funds donor lottery (hoping it’s announced soon :-D )
This is great to hear! I’m personally more excited by quality-of-life improvement interventions rather than saving lives so really grateful for this work.
Echoing kokotajlod’s question for GiveWell’s recommendations, do you have a sense of whether your recommendations change with a very high discount rate (e.g. 10%)? Looking at the graph of GiveDirectly vs StrongMinds it looks like the vast majority of benefits are in the first ~4 years
Minor note: the link at the top of the page is broken (I think the 11⁄23 in the URL needs to be changed to 11⁄24)
When LessWrong posts are crossposted to the EA Forum, there is a link in EA Forum comments section:
This link just goes to the top of the LessWrong version of the post and not to the comments. I think either the text should be changed or the link go to the comments section.
In this recent post from Oscar Delaney they got the following result (sadly doesn’t go up to 10%, and in the linked spreadsheet the numbers seem hardcoded)
Top three are Hellen Keller International (0.122), Sightsavers (0.095), AMF (0.062)
(minor point that might help other confused people)
I had to google CMO (which I found to mean Chief Marketing Officer) and also thought that BOAS might be an acronym—but found on your website
BOAS means good in Portuguese, clearly explaining what we do in only four letters!
Increasing/decreasing one’s AGI timelines decrease/increase the importance [1] of non-AGI existential risks because there is more/less time for them to occur[2].
Further, as time passes and we get closer to AGI, the importance of non-AI x-risk decreases relative to AI x-risk. This is a particular case of the above claim.
These seem neat! I’d recommend posting them to the EA Forum—maybe just as a shortform—as well as on your website so people can discuss the thoughts you’ve added (or maybe even posting the thoughts on your shortform with a link to your summary).
For a while I ran a podcast discussion meeting at my local group and I think summaries like this would have been super useful to send to people who didn’t want to / have time to listen. As a bonus—though maybe too much effort—would be generating discussion prompts based on the episode.
This looks exciting!
The application form link doesn’t currently work.
I highly recommend Nick Bostrom’s working paper Base Camp for Mt. Ethics.
Some excerpts on the idea of the cosmic host that I liked most:
34. At the highest level might be some normative structure established by what we may term the cosmic host. This refers to the entity or set of entities whose preferences and concordats dominate at the largest scale, i.e. that of the cosmos (by which I mean to include the multiverse and whatever else is contained in the totality of existence). It might conceivably consist of, for example, galactic civilizations, simulators, superintelligences, or a divine being or beings.
39. One might think that we could have no clue as to what the cosmic norms are, but in fact we can make at least some guesses:
a. We should refrain from harming or disrespecting local instances of things that the cosmic host is likely to care about.
b. We should facilitate positive-sum cooperation, and do our bit to uphold the cosmic normative order and nudge it in positive directions.
c. We should contribute public goods to the cosmic resource pool, by securing resources and (later) placing them under the control of cosmic norms. Prevent xrisk and build AI?
d. We should be modest, willing to listen and learn. We should not too headstrongly insist on having too much our way. Instead, we should be compliant, peace-loving, industrious, and humble vis-a-vis the cosmic host.
41. Maybe this could itself be part of an alignment goal: to build our AI such that it wants to be a good cosmic citizen and comply with celestial morality.
a. We may also want it to cherish its parents and look after us in our old age. But a little might go a long way in that regard.
I’ve been building a model to calculate the optimal spending schedule on AGI safety and am looking for volunteers to run user experience testing.
Let me know via DM on the forum or email if you’re interested :-)
The only requirements are (1) to be happy to call & share your screen for ~20 to ~60 minutes while you use the model (a Colab notebook which runs in your browser) and (2) some interest in AI safety strategy (but certainly no expertise necessary)
I was also not sure how the strong votes worked, but found a description from four years ago here. I’m not sure if the system’s in date.
Normal votes (one click) will be worth
3 points – if you have 25,000 karma or more
2 points – if you have 1,000 karma
1 point – if you have 0 karma
Strong Votes (click and hold) will be worth
16 points (maximum) – if you have 500,000 karma
15 points – 250,000
14 points – 175,000
13 points – 100,000
12 points – 75,000
11 points – 50,000
10 points – 25,000
9 points – 10,000
8 points – 5,000
7 points – 2,500
6 points – 1,000
5 points – 500
4 points – 250
3 points – 100
2 points – 10
1 point – 0
If you create a search then edit it to become empty on the Forum, you can see a list of the highest karma users. The first two pages:
Peter Wildeford 8y 11209 karma
Thanks for writing this! I think you’re right that if you buy the Doomsday argument (or assumptions that lead to it) then we should update against worlds with 10^50 future humans and towards worlds with Doom-soon.
However, you write
My take is that the Doomsday Argument is … but it follows from the assumptions outlined
which I don’t think is true. For example, your assumptions seem equally compatible with the self-indication assumption (SIA) that doesn’t predict Doom-soon.[1]
I think a lot of confusions in anthropics go away when we convert probability questions to decision problem questions. This is what Armstrong’s Anthropic Decision Theory does.
Interestingly, something like the Doomsday argument applies for average utilitarians: they bet on Doom-soon, since in this case they win the bet the utility is spread over much fewer people.
Katja Grace has written about SIA Doomsday but this is (in my view) contingent on beliefs about aliens & simulations whereas SSA Doomsday is not.
Thanks :-)
Good point! The model does assume that the funder’s spending strategy never changes. And if there was a slow takeoff the funder might try and spend quickly before their capital becomes useless etc etc.
I think I’m pretty sold on fast-takeoff that this consideration didn’t properly cross my mind :-D
Here’s one very simple way of modelling it
write ps for the probability of a slow takeoff
call C the interventions available during the slow take-off and write c as the (average) cost effectiveness of interventions as as fraction of a, the cost effectiveness of intervention A.[1]
Conditioning on AGI at t:
F spends fraction min(ft,1) of any saved capital on A
F spends fraction 1−min(ft,1) ofof any saved capital on C
Hence the cost effectiveness of a small donor’s donation to A this year is min(ft,1)+[1−min(ft,1)]⋅ps⋅c times the on-paper cost effectiveness of donating to A.
Taking
ps∼Normal(0.4,0.2) truncated to (0,1)
the distribution for f in the post and Metaculus AGI timelines
gives the following result, around a 5pp increase compared to the results not factoring this in.
I think this extension better fits faster slow-takeoffs (i.e. on the order of 1-5 years). In my work on AI risk spending I considered a similar model feature, where after an AGI ‘fire alarm’ funders are able to switch to a new regime of faster spending.
I think almost certainly that s<1 for GHD giving. Both because
(1) the higher spending rate requires a lower bar
(2) many of the best current interventions benefit people over many years (and so we have to truncate only consider the benefit accrued before full on AGI, something that I consider here).