I am a research analyst at the Center on Long-Term Risk.
I’ve worked on grabby aliens, the optimal spending schedule for AI risk funders, and evidential cooperation in large worlds.
Some links
I am a research analyst at the Center on Long-Term Risk.
I’ve worked on grabby aliens, the optimal spending schedule for AI risk funders, and evidential cooperation in large worlds.
Some links
I think you raise some good considerations but want to push back a little.
I agree with your arguments that
- we shouldn’t use point estimates (of the median AGI date)
- we shouldn’t fully defer to (say) Metaculus estimates.
- personal fit is important
But I don’t think you’ve argued that “Whether you should do a PhD doesn’t depend much on timelines.”
Ideally as a community we can have a guess at the optimal number of people in the community that should do PhDs (factoring in their personal fit etc) vs other paths.
I don’t think this has been done, but since most estimates of AGI timelines have decreased in the past few years it seems very plausible to me that the optimal allocation now has fewer people doing PhDs. This could maybe be framed as raising the ‘personal fit bar’ to doing a PhD.
I think my worry boils down to thinking that “don’t factor in timelines too much” could be overly general and not get us closer to the optimal allocation.
This is a short follow up to my post on the optimal timing of spending on AGI safety work which, given exact values for the future real interest, diminishing returns and other factors, calculated the optimal spending schedule for AI risk interventions.
This has also been added to the post’s appendix and assumes some familiarity with the post.
Here I consider the most robust spending policies and supposes uncertainty over nearly all parameters in the model[1] Inputs that are not considered include: historic spending on research and influence, rather than finding the optimal solutions based on point estimates and again find that the community’s current spending rate on AI risk interventions is too low.
My distributions over the the model parameters imply that
Of all fixed spending schedules (i.e. to spend X% of your capital per year[2]), the best strategy is to spend 4-6% per year.
Of all simple spending schedules that consider two regimes: now until 2030, 2030 onwards, the best strategy is to spend ~8% per year until 2030, and ~6% afterwards.
I recommend entering your own distributions for the parameters in the Python notebook here[3]. Further, these preliminary results use few samples: more reliable results would be obtained with more samples (and more computing time).
I allow for post-fire-alarm spending (i.e., we are certain AGI is soon and so can spend some fraction of our capital). Without this feature, the optimal schedules would likely recommend a greater spending rate.
Caption: Simple - two regime - spending rate
The system of equations—describing how a funder’s spending on AI risk interventions change the probability of AGI going well—are unchanged from the main model in the post.
This version of the model randomly generates the real interest, based on user inputs. So, for example, one’s capital can go down.
Caption: An example real interest function , cherry picked to show how our capital can go down significantly. See here for 100 unbiased samples of .
Caption: Example probability-of-success functions. The filled circle indicates the current preparedness and probability of success.
Caption: Example competition functions. They all pass through (2022, 1) since the competition function is the relative cost of one unit of influence compared to the current cost.
This short extension started due to a conversation with David Field and comment from Vasco Grilo; I’m grateful to both for the suggestion.
Inputs that are not considered include: historic spending on research and influence, the rate at which the real interest rate changes, the post-fire alarm returns are considered to be the same as the pre-fire alarm returns.
And supposing a 50:50 split between spending on research and influence
This notebook is less user-friendly than the notebook used in the main optimal spending result (though not un user friendly) - let me know if improvements to the notebook would be useful for you.
The intermediate steps of the optimiser are here.
Thanks for this post! I used to do some voluntary university community building, and some of your insights definitely ring true to me, particularly the Alice example—I’m worried that I might have been the sort of facilitator to not return to the assumptions in fellowships I’ve facilitated.
A small note:
Well, the most obvious place to look is the most recent Leader Forum, which gives the following talent gaps (in order):
This EA Leaders Forum was nearly 3 years ago, and so talent gaps have possibly changed. There was a Meta Coordination Forum last year run by CEA, but I haven’t seen any similar write-ups. This doesn’t seem to be an important crux for most of your points, but thought would be worth mentioning.
Hello! I’m a maths master’s student at Cambridge and have been involved with student groups for the last few years. I’ve been lurking on the forum for a long time and want to become more active. Hopefully this is the first comment of many!
This is great to hear! I’m personally more excited by quality-of-life improvement interventions rather than saving lives so really grateful for this work.
Echoing kokotajlod’s question for GiveWell’s recommendations, do you have a sense of whether your recommendations change with a very high discount rate (e.g. 10%)? Looking at the graph of GiveDirectly vs StrongMinds it looks like the vast majority of benefits are in the first ~4 years
Minor note: the link at the top of the page is broken (I think the 11⁄23 in the URL needs to be changed to 11⁄24)
Thanks for this post! I’ve been meaning to write something similar, and have glad you have :-)
I agree with your claim that most observers like us (who believe they are at the hinge of history) are in (short-lived) simulations. Brian Tomasik discusses how this marginally makes one value interventions with short-term effects.
In particular, if you think the simulations won’t include other moral patients simulated to a high resolution (e.g. Tomasik suggests this may be the case for wild animals in remote places), you would instrumentally care less about their welfare (since when you act to increase their welfare, this may only have effects in basement reality as well as the more expensive simulations that do simulate such wild animals) . At the extreme is your suggestion, where you are the only person in the simulation and so you may act as a hedonist! Given some uncertainty over the distribution of “resolution of simulations”, it seems likely that one should still act altruistically.
I disagree with the claim that if we do not pursue longtermism, then no simulations of observers like us will be created. For example, I think an Earth-originating unaligned AGI would still have instrumental reasons to run simulations of 21st century Earth. Further, alien civilizations may have interest to learn about other civilizations.
Under your assumptions, I don’t think this is a Newcomb-like problem. I think CDT & EDT would agree on the decision,[1] which I think depends on the number of simulations and the degree to which the existence of a good longterm future hinges your decisions. Supposing humanity only survives if you act as a longtermist and simulations of you are only created if humanity survives, then you can’t both act hedonistically and be in a simulation.
This looks great, thanks for creating it! I could see it becoming a great ‘default’ place for EAs to meet for coworking or social things.
I think there are benefits to thinking about where to give (fun, having engagement with the community, skill building, fuzzies)[1] but I think that most people shouldn’t think too much about it and—if they are deciding where to give—should do one of the following.
1 Give to the donor lottery
I primarily recommend giving through a donor lottery and then only thinking about where to give in the case you win. There are existing arguments for the donor lottery.
2 Deliberately funge with funders you trust
Alternatively I would recommend deliberately ‘funging’ with other funders (e.g. Open Philanthropy), such as through GiveWell’s Top Charities Fund.
However, if you have empirical or value disagreements with the large funder you funge with or believe they are mistaken, you may be able to do better by doing your own research.[2]
3 If you work at an ‘effective’[3] organisation, take a salary cut
Finally, if you work at an organisation whose mission you believe effective, or is funded by a large funder (see previous point on funging), consider taking a salary cut[4].
(a) Saving now to give later
I would say to just give to the donor lottery and if you win: first, spend some time thinking and decide whether you want to give later. If you conclude yes, give to something like the Patient Philanthropy Fund, set-up some new mechanism for giving later or (as you always can) enter/create a new donor lottery.
(b) Thinking too long about it—unless it’s rewarding for you
Where rewarding could be any of: fun, interesting, good for the community, gives fuzzies, builds skills or something else. There’s no obligation at all in working out your own cost effectiveness estimates of charities and choosing the best.
(c) Thinking too much about funging, counterfactuals or Shapley values
My guess is that if everyone does the ‘obvious’ strategy of “donate to the things that look most cost effective[5]” and you’re broadly on board with the values[6], empirical beliefs[7] and donation mindset[8] of the other donors in the community[9], it’s not worth considering how counterfactual your donation was or who you’ve funged with.
Thanks to Tom Barnes for comments.
Consider the goal factoring the activity of “doing research about where to give this year”. It’s possible there are distinct tasks that achieve your goals better (e.g. “give to the donor lottery” and “do independent research on X” that better achieve your goals).
For example, I write here how—given Metaculus AGI timelines and a speculative projection of Open Philanthropy’s spending strategy—small donors donations’ can go further when not funging with them.
A sufficient (but certainly not necessary) condition could be “receives funding from an EA-aligned funded, such as Open Philanthropy” (if you trust the judgement and the share values of the funder)
This is potentially UK specific (I don’t know about other countries) and for people on relatively high salaries (>£50k, the point at which the marginal tax rate is greater than Gift Aid one can claim back).
With the caveat of making sure opportunities doesn’t get overfunded
I’d guess there is a high degree of values overlap in your community: if you donate to a global health organisation and another donor—as a result of your donation—decides to donate elsewhere, it seems reasonably likely they will donate to another global health organisation.
I’d guess this overlap is relatively high for niche EA organisations. I’ve written about how to factor in funging as a result of (implicit) differences of AI timelines. Other such empirical beliefs could include: beliefs about the relative importance of different existential risks among longtermists or the value of some global health interventions (e.g. Strong Minds)
For particularly public charitable organisations and causes, I’d guess there is less mindset overlap. That is, whether the person you’ve funged with shares the effectiveness mindset (and so their donation may be to a charity you would judge as less cost effectiveness than where you would donate if-accounting-for-funging.
The “community” is roughly the set of people who donate—or would donate—to the charities you are donating to.
Thanks for putting this together!
The list of people on the google form and the list in this post don’t match (e.g. Seren Kell is on the post but not on the form and vice versa for David Manheim and Zachary Robinson)
The consequence of this for the “spend now vs spend later” debate is crudely modeled in The optimal timing of spending on AGI safety work, if one expects automated science to directly & predictably precede AGI. (Our model does not model labor, and instead considers [the AI risk community’s] stocks of money, research and influence)
We suppose that after a ‘fire alarm’ funders can spend down their remaining capital, and that the returns to spending on safety research during this period can be higher than spending pre-fire alarm (although our implementation, as Phil Trammell points out, is subtly problematic, and I’ve not computed the results with a corrected approach).
Thanks for the post! I thought it was interesting and thought-provoking, and I really enjoy posts like this one that get serious about building models.
Thanks :-)
One thought I did have about the model is that (if I’m interpreting it right) it seems to assume a 100% probability of fast takeoff (from strong AGI to ASI/the world totally changing), which isn’t necessarily consistent with what most forecasters are predicting. For example, the Metaculus forecast for years between GWP growth >25% and AGI assigns a ~25% probability that it will be at least 15 years between AGI and massive resulting economic growth.
Good point! The model does assume that the funder’s spending strategy never changes. And if there was a slow takeoff the funder might try and spend quickly before their capital becomes useless etc etc.
I think I’m pretty sold on fast-takeoff that this consideration didn’t properly cross my mind :-D
I would enjoy seeing an expanded model that accounted for this aspect of the forecast as well.
Here’s one very simple way of modelling it
write for the probability of a slow takeoff
call the interventions available during the slow take-off and write as the (average) cost effectiveness of interventions as as fraction of , the cost effectiveness of intervention .[1]
Conditioning on AGI at :
spends fraction of any saved capital on
spends fraction ofof any saved capital on
Hence the cost effectiveness of a small donor’s donation to this year is times the on-paper cost effectiveness of donating to .
Taking
truncated to (0,1)
the distribution for in the post and Metaculus AGI timelines
gives the following result, around a 5pp increase compared to the results not factoring this in.
I think this extension better fits faster slow-takeoffs (i.e. on the order of 1-5 years). In my work on AI risk spending I considered a similar model feature, where after an AGI ‘fire alarm’ funders are able to switch to a new regime of faster spending.
I think almost certainly that for GHD giving. Both because
(1) the higher spending rate requires a lower bar
(2) many of the best current interventions benefit people over many years (and so we have to truncate only consider the benefit accrued before full on AGI, something that I consider here).
Increasing/decreasing one’s AGI timelines decrease/increase the importance [1] of non-AGI existential risks because there is more/less time for them to occur[2].
Further, as time passes and we get closer to AGI, the importance of non-AI x-risk decreases relative to AI x-risk. This is a particular case of the above claim.
When LessWrong posts are crossposted to the EA Forum, there is a link in EA Forum comments section:
This link just goes to the top of the LessWrong version of the post and not to the comments. I think either the text should be changed or the link go to the comments section.
(minor point that might help other confused people)
I had to google CMO (which I found to mean Chief Marketing Officer) and also thought that BOAS might be an acronym—but found on your website
BOAS means good in Portuguese, clearly explaining what we do in only four letters!
Epistemic status: I’ve done work suggesting that AI risk funders be spending at a higher rate, and I’m confident in this result. The other takes are less informed!
I discuss
Whether I think we should be spending less now
Useful definitions of patient philanthropy
Being specific about empirical beliefs that push for more patience
When patient philanthropy is counterfactual
Opportunities for donation trading between patient and non-patient donors
In principle I think the effective giving community could be in a situation where we should marginally be saving/investing more than we currently do (being ‘patient’).
However, I don’t think we’re in such a situation and in fact believe the opposite. My main crux is AI timelines; if I thought that AGI was less likely than not to arrive this century, then I would almost certainly believe that the community should marginally be spending less now.
I think patient philanthropy could be thought of as saying one of:
The community is spending at the optimal rate - let’s create a place to save/invest so ensure we don’t (mistakenly) overspend and keep our funds secure.
The community is spending above the optimal rate—let’s push for more savings on the margin, and create a place to save/invest and give later
I don’t think we should call (1) patient philanthropy. Large funders (e.g. Open Philanthropy) already do some form of (1) by just not spending all their capital all this year. Doing (1) is instrumentally useful for the community and is necessary in any case where the community is not spending all of its capital this year.
I like (2) a lot more. This definition is relative to the community’s current spending rate and could be intuitively ‘impatient’. Throughout, I’ll use ‘patient’ to refer to (2): thinking the community’s current spending rate is too high (and so we do better by saving more now and spending later).
As an aside, thinking that the most ‘influential’ time ahead is not equivalent to being patient. Non-patient funders can also think this but believe their last spending this year goes further than in any other year.
A potential third definition could be something like “patience is spending 0 to ~2% per year” but I don’t think it is useful to discuss.
Of course, the large funders and the patient philanthropist may have different beliefs that lead them to disagree on the community’s optimal spending rate. If I believes one of the following, I’d like decrease my guess of the community’s optimal spending rate (and becoming more patient):
Thinking that there are not good opportunities to spend lots on now (i.e. higher diminishing returns to spending)
Thinking that TAI / AGI is further away.
Thinking that the rate of non-AI global catastrophic risk (e.g. nuclear war, biorisk) is lower
Thinking that there’ll be great spending opportunities in the run-up to AGI
Thinking that capital will be useful post-AGI
Thinking that the existing large funders’s capital is less secure or the large funders’ future effective giving less likely for other reasons
Since it seems likely that there are multiple points of disagreement leading to different spending rates, ‘‘patient philanthropy’ may be a useful term for the cluster of empirical beliefs that imply the community should be spending less. However, it seems better to be more specific about which particular beliefs are driving this the most.
For example “AI skeptical patient philanthropists” and “better-AI-opportunities-now patient philanthropists” may agree that the community’s current spending rate is too high, but disagree on the optimal (rate of) future spending.
Patient philanthropists can be considered as funders with a very high ‘bar’. That is, they will only spend down on opportunities better than utils per $ and if none currently exist, they will wait.
Non-patient philanthropists also operate similarly but with a lower bar . While the non-patient philanthropist has funds (and funds anything above utils per dollar, including the opportunities that the patient philanthropist would otherwise fund) the patient philanthropist spends nothing. The patient philanthropist reasons that the counterfactual value of funding something the non-patient philanthropist would fund is zero and so chooses to save.
In this setup, the patient philanthropist is looking to fund and take credit for the ‘best’ opportunities and—while the large funder is around—the patient philanthropist is just funging with them. Once the large funder runs out of funds, the patient philanthropist’s funding is counterfactual.[1]
If the large funder and patient philanthropist have differences in values or empirical beliefs, it is unsurprising they have different guesses of the optimal spending rate and ‘bar’.
However, this should not happen with value and belief-aligned funders and patient philanthropists; if the funder is acting ‘rationally’ and spending at the optimal rate, then (by definition) there are no type-2 patient patient philanthropists that have the same beliefs.
There are some opportunities for trade between patient philanthropists and non-patient philanthropists, similar to how people can bet on AI timelines.
Let’s say Alice pledges to give $/year from her income and thinks that the community should be spending more now. Let’s say that Bob thinks the community should be spending less and and saves $/year from his income in order to give it away later. There’s likely an agreement possible (dependent on many factors) where they both benefit. A simple setup could involve:
Bob, for the next years gives away their $/year to Alice’s choice of giving opportunity
Alice, after years, giving $/year to Bob’s preferred method of investing/saving or giving
This example closely follows similar setups suggested for betting on AI timelines.
Unless the amazing opportunity of utils/$ appears just after the large funder runs out of funds. Where ‘just after’ is the time that the large funder would have kept going with their existing spending strategy of funding everything about utils/$ by using the patient philanthropist’s funds.
Thanks for running the survey, I’m looking forward to seeing results!
I’ve filled out the form but find some of the potential arguments problematic. It could be worth to seeing how persuasive others find these arguments but I would be hesitant to promote arguments that don’t seem robust. In general, I think more disjunctive arguments work well.
For example, (being somewhat nitpicky):
Everyone you know and love would suffer and die tragically.
Some existential catastrophes could happen painlessly and quickly .
We would destroy the universe’s only chance at knowing itself...
Aliens (maybe!) or (much less likely imo) another intelligent species evolving on Earth
There are co-benefits to existential risk mitigation: prioritizing these risks means building better healthcare infrastructure, better defense against climate change, etc.
It seems that work on biorisk prevention does involve “building better healthcare infrastructure” but is maybe misleading to characterise it in this way since I imagine people think of something different when they hear the term. There are also drawbacks to some (proposed) existential risk mitigation interventions.
A diagram to show possible definitions of existential risks (x-risks) and suffering risks (s-risks)
The (expected) value & disvalue of the entire world’s past and future can be placed on the below axes (assuming both are finite).
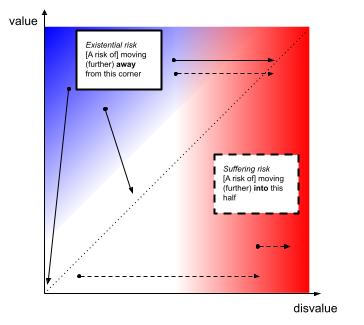
By these definitions:
Some x-risks are s-risks
Not all s-risks are x-risks
Thanks for such a detailed and insightful response Gregory.
Your archetypal classical utilitarian is also committed to the OC as ‘large increase in suffering for one individual’ can be outweighed by a large enough number of smaller decreases in suffering for others—aggregation still applies to negative numbers for classical utilitarians. So the negative view fares better as the classical one has to bite one extra bullet.
Thanks for pointing this out. I think I realised this extra bullet biting after making the post.
There’s also the worry in a pairwise comparison one might inadvertently pick a counterexample for one ‘side’ that turns the screws less than the counterexample for the other one.
This makes a lot of sense, and not something I’d considered at all and seems pretty important when playing counterxample-intuition-tennis.
By my lights, it seems better to have some procedure for picking and comparing cases which isolates the principle being evaluated. Ideally, the putative counterexamples share counterintuitive features both theories endorse, but differ in one is trying to explore the worst case that can be constructed which the principle would avoid, whilst the other the worst case that can be constructed with its inclusion.
Again, this feels really useful and something I want to think about further.
The typical worry of the (absolute) negative view itself is it fails to price happiness at all—yet often we’re inclined to say enduring some suffering (or accepting some risk of suffering) is a good deal at least at some extreme of ‘upside’.
I think my slight negative intuition comes from that fact that although I may be willing to endure some suffering for some upside, I wouldn’t endorse inflicting suffering (or risk or suffering) on person A for some upside for person B. I don’t know how much work the differences of fairness personal identity (i.e. the being that suffered gets the upside) between the examples are doing, and it what direction my intuition is ‘less’ biased.
Yet with this procedure, we can construct a much worse counterexample to the negative view than the OC—by my lights, far more intuitively toxic than the already costly vRC. (Owed to Carl Shulman). Suppose A is a vast but trivially-imperfect utopia—Trillions (or googleplexes, or TREE(TREE(3))) lives lives of all-but-perfect bliss, but for each enduring an episode of trivial discomfort or suffering (e.g. a pin-prick, waiting a queue for an hour). Suppose Z is a world with a (relatively) much smaller number of people (e.g. a billion) living like the child in Omelas
I like this example a lot! and definitely lean A > Z.
Reframing the situation, and my intuition becomes less clear: considering A’, in which TREE(TREE(3))) lives are in perfect bliss, but there are also TREE(TREE(3))) beings that monetarily experience a single pinprick before ceasing to to exist. This is clearly equivalent to A in the axiology but my intuition is less clear (if at all) that A’ > Z. As above, I’m unsure how much work personal identity is doing. In my mind, I find population ethics easier to think about by considering ‘experienced moments’ rather than individuals.
(This axiology is also anti-egalitarian (consider replacing half the people in A with half the people in Z) …
Thanks for pointing out the error. I think think I’m right in saying that the ‘welfare capped by 0’ axiology is non-anti-egalitarian, which I conflated with absolute NU in my post (which is anti-egalitarian as you say). The axiologies are much more distinct than I originally thought.
I think “different timelines don’t change the EV of different options very much” plus “personal fit considerations can change the EV of a PhD by a ton” does end up resulting in an argument for the PhD decision not depending much on timelines. I think that you’re mostly disagreeing with the first claim, but I’m not entirely sure.
Yep, that’s right that I’m disagreeing with the first claim. I think one could argue the main claim either by:
Regardless of your timelines, you (person considering doing a PhD) shouldn’t take it too much into consideration
I (advising you on how to think about whether to do a PhD) think timelines are such that you shouldn’t take timelines too much into consideration
I think (1) is false, and think that (2) should be qualified by how one’s advice would change depending on timelines. (You do briefly discuss (2), e.g. the SOTA comment).
To put my cards on the table, on the object level, I have relatively short timelines and that fewer people should be doing PhDs on the margin. My highly speculative guess is that this post has the effect of marginally pushing more people towards doing PhDs (given the existing association of shorter timelines ⇒ shouldn’t do a PhD).
I was also not sure how the strong votes worked, but found a description from four years ago here. I’m not sure if the system’s in date.
If you create a search then edit it to become empty on the Forum, you can see a list of the highest karma users. The first two pages: