GWWC lists StrongMinds as a “top-rated” charity. Their reason for doing so is because Founders Pledge has determined they are cost-effective in their report into mental health.
I could say here, “and that report was written in 2019 - either they should update the report or remove the top rating” and we could all go home. In fact, most of what I’m about to say does consist of “the data really isn’t that clear yet”.
I think the strongest statement I can make (which I doubt StrongMinds would disagree with) is:
“StrongMinds have made limited effort to be quantitative in their self-evaluation, haven’t continued monitoring impact after intervention, haven’t done the research they once claimed they would. They have not been vetted sufficiently to be considered a top charity, and only one independent group has done the work to look into them.”
My key issues are:
Survey data is notoriously noisy and the data here seems to be especially so
There are reasons to be especially doubtful about the accuracy of the survey data (StrongMinds have twice updated their level of uncertainty in their numbers due to SDB)
One of the main models is (to my eyes) off by a factor of ~2 based on an unrealistic assumption about depression (medium confidence)
StrongMinds haven’t continued to publish new data since their trials very early on
StrongMinds seem to be somewhat deceptive about how they market themselves as “effective” (and EA are playing into that by holding them in such high esteem without scrutiny)
What’s going on with the PHQ-9 scores?
In their last four quarterly reports, StrongMinds have reported PHQ-9 reductions of: −13, −13, −13, −13. In their Phase II report, raw scores dropped by a similar amount:
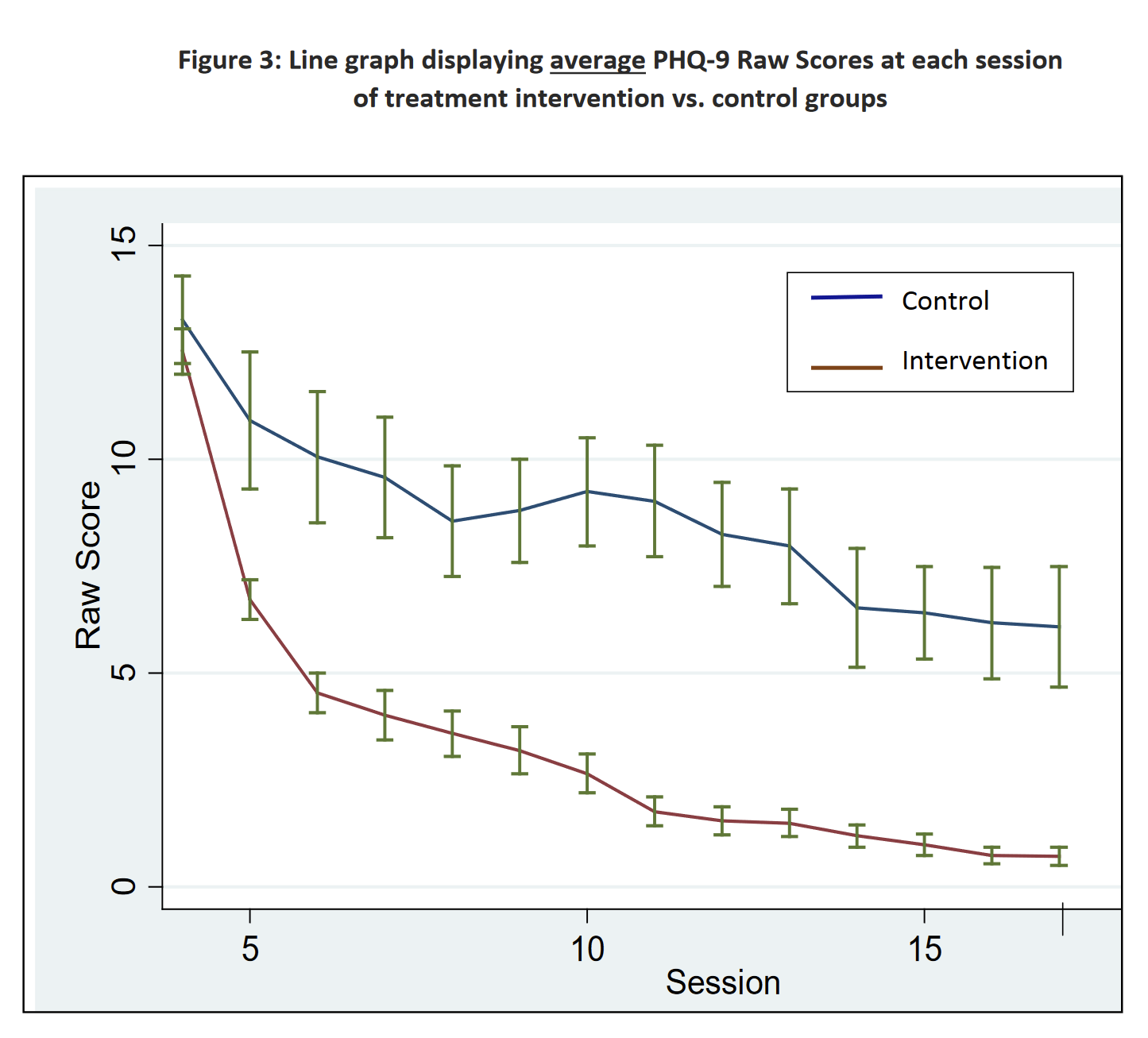
However, their Phase II analysis reports (emphasis theirs):
As evidenced in Table 5, members in the treatment intervention group, on average, had a 4.5 point reduction in their total PHQ-9 Raw Score over the intervention period, as compared to the control populations. Further, there is also a significant visit effect when controlling for group membership. The PHQ-9 Raw Score decreased on average by 0.86 points for a participant for every two groups she attended. Both of these findings are statistically significant.
Founders Pledge’s cost-effectivenes model uses the 4.5 reduction number in their model. (And further reduces this for reasons we’ll get into later).
Based on Phase I and II surveys, it seems to me that a much more cost-effective intervention would be to go around surveying people. I’m not exactly sure what’s going on with the Phase I / Phase II data, but the best I can tell is in Phase I we had a ~7.5 vs ~5.1 PHQ-9 reduction from “being surveyed” vs “being part of the group” and in Phase II we had ~3.0 vs ~7.1 PHQ-9 reduction from “being surveyed” vs “being part of the group”. [an earlier version of this post used the numbers ‘~5.1 vs ~4.5 PHQ-9’ but Natalia pointed out the error in this comment] For what it’s worth, I don’t believe this is likely the case, I think it’s just a strong sign that the survey mechanism being used is inadequate to determine what is going on.
There are a number of potential reasons we might expect to see such large improvements in the mental health of the control group (as well as the treatment group).
Mean-reversion—StrongMinds happens to sample people at a low ebb and so the progression of time leads their mental health to improve of its own accord
“People in targeted communities often incorrectly believe that StrongMinds will provide them with cash or material goods and may therefore provide misleading responses when being diagnosed.” (source) Potential participants fake their initial scores in order to get into the program (either because they (mistakenly) think there is some material benefit to being in the program or because they think it makes them more likely to get into a program they think would have value for them.
What’s going on with the ‘social-desirability bias’?
Both the Phase I and Phase II trials discovered that 97% and 99% of their patients were “depression-free” after the trial. They realised that these numbers were inaccurate during their Phase II trial. They decided on the basis of this, to reduce their numbers from 99% in Phase II to 92% on the basis of the results two weeks prior to the end.
In their follow-up study of Phases I and II, they then say:
While both the Phase 1 and 2 patients had 95% depression-free rates at the completion of formal sessions, our Impact Evaluation reports and subsequent experience has helped us to understand that those rates were somewhat inflated by social desirability bias, roughly by a factor of approximately ten percentage points. This was due to the fact that their Mental Health Facilitator administered the PHQ-9 at the conclusion of therapy. StrongMinds now uses external data collectors to conduct the post-treatment evaluations. Thus, for effective purposes, StrongMinds believes the actual depression-free rates for Phase 1 and 2 to be more in the range of 85%.
I would agree with StrongMinds that they still had social-desirability bias in their Phase I and II reports, although it’s not clear to me they have fully removed it now. This also relates to my earlier point about how much improvement we see in the control group. If pre-treatment are showing too high levels of depression and the post-treatment group is too low how confident should we be in the magnitude of these effects?
How bad is depression?
Severe depression has a DALY weighting of 0.66.
(Founders Pledge report, via Global Burden of Disease Disability Weights)
The key section of the Disability Weights table reads as follows:

My understanding (based on the lay descriptions, IANAD etc) is that “severe depression” is not quite the right way to describe the thing which has a DALY weighting of 0.66. “severe depression during an episode has a DALY weighting of 0.66” would be more accurate.
Assuming linear decline in severity on the PHQ-9 scale.
(Founders Pledge model)
Furthermore whilst the disability weights are linear between “mild”, “moderate” and “severe” the threshold for “mild” in PHQ-9 terms is not ~1/3 of the way up the scale. Therefore there is a much smaller change in disability weight for going 12 points from 12 − 0 than for 24-12. (One takes you from ~mild to asymptomatic ~.15 and one takes you from “severe episode” to “mild episode” ~0.51 which is a much larger change).
This change would roughly halve the effectiveness of the intervention, using the Founders Pledge model.
Lack of data
My biggest gripe with StrongMinds is they haven’t continued to provide follow-up analysis for any of their cohorts (aside from Phase I and II) despite saying they would in their 2017 report:
Looking forward, StrongMinds will continue to strengthen our evaluation efforts and will continue to follow up with patients at 6 or 12 month intervals. We also remain committed to implementing a much more rigorous study, in the form of an externally-led, longitudinal randomized control trial, in the coming years.
As far as I can tell, based on their conversation with GiveWell:
StrongMinds has decided not pursue a randomized controlled trial (RCT) of its program in the short term, due to:
High costs – Global funding for mental health interventions is highly limited, and StrongMinds estimates that a sufficiently large RCT of its program would cost $750,000 to $1 million.
Sufficient existing evidence – An RCT conducted in 2002 in Uganda found that weekly IPT-G significantly reduced depression among participants in the treatment group. Additionally, in October 2018, StrongMinds initiated a study of its program in Uganda with 200 control group participants (to be compared with program beneficiaries)—which has demonstrated strong program impact. The study is scheduled to conclude in October 2019.
Sufficient credibility of intervention and organization – In 2017, WHO formally recommended IPT-G as first line treatment for depression in low- and middle-income countries. Furthermore, the woman responsible for developing IPT-G and the woman who conducted the 2002 RCT on IPT-G both serve as mental health advisors on StrongMinds’ advisory committee.
I don’t agree with any of the bullet points. (Aside from the first, although I think there should be ways to publish more data within the context of their current data).
On the bright side(!) as far as I can tell, we should be seeing new data soon. StrongMinds and Berk Ozler should have finished collecting their data for a larger RCT on StrongMinds. It’s a shame it’s not a direct comparison between cash transfers and IPT-G, (the arms are: IPT-G, IPT-G + cash transfers, no-intervention) but it will still be very valuable data for evaluating them.
Misleading?

(from the StrongMinds homepage)
This implies Charity Navigator thinks they are one of the world’s most effective charities. But in fact Charity Navigator haven’t evaluated them for “Impact & Results”.

WHO: There’s no external validation here (afaict). They just use StrongMinds own numbers and talk around the charity a bit.
I’m going to leave aside discussing HLI here. Whilst I think they have some of the deepest analysis of StrongMinds, I am still confused by some of their methodology, it’s not clear to me what their relationship to StrongMinds is. I plan on going into more detail there in future posts. The key thing to understand about the HLI methodology is that follows the same structure as the Founders Pledge analysis and so all the problems I mention above regarding data apply just as much to them as FP.
The “Inciting Altruism” profile, well, read it for yourself.
Founders Pledge is the only independent report I’ve found—and is discussed throughout this article.
GiveWell Staff Members personal donations:
I plan to give 5% of my total giving to StrongMinds, an organization focused on treating depression in Africa. I have not vetted this organization anywhere nearly as closely as GiveWell’s top charities have been vetted, though I understand that a number of people in the effective altruism community have a positive view of StrongMinds within the cause area of mental health (though I don’t have any reason to think it is more cost-effective than GiveWell’s top charities). Intuitively, I believe mental health is an important cause area for donors to consider, and although we do not have GiveWell recommendations in this space, I would like to learn more about this area by making a relatively small donation to an organization that focuses on it.
This is not external validation.
The EA Forum post is also another HLI piece.
I don’t have access to the Stanford piece, it’s paywalled.
Another example of them being misleading is in all their reports they report the headline PHQ-9 reduction numbers, but everyone involve knows (I hope) that those aren’t really a relevant metric without understanding the counterfactual reduction they actually think is happening. It’s either a vanity metric or a bit deceptive.
Conclusion
What I would like to happen is:
Founders Pledge update or withdraw their recommendation of StrongMinds
GWWC remove StrongMinds as a top charity
Ozler’s study comes out saying it’s super effective
Everyone reinstates StrongMinds as a top charity, including some evaluators who haven’t done so thus far
Hi Simon, thanks for writing this! I’m research director at FP, and have a few bullets to comment here in response, but overall just want to indicate that this post is very valuable. I’m also commenting on my phone and don’t have access to my computer at the moment, but can participate in this conversation more energetically (and provide more detail) when I’m back at work next week.
I basically agree with what I take to be your topline finding here, which is that more data is needed before we can arrive at GiveWell-tier levels of confidence about StrongMinds. I agree that a lack of recent follow-ups is problematic from an evaluator’s standpoint and look forward to updated data.
FP doesn’t generally strive for GW-tier levels of confidence; we’re risk-neutral and our general procedure is to estimate expected cost-effectiveness inclusive of deflators for various kinds of subjective consideration, like social desirability bias.
The 2019 report you link (and the associated CEA) is deprecated— FP hasn’t been resourced to update public-facing materials, a situation that is now changing—but the proviso at the top of the page is accurate: we stand by our recommendation.
This is because we re-evaluated StrongMinds last year based on HLI’s research. The new evaluation did things a little bit differently than the old one. Instead of attempting to linearize the relationship between PHQ-9 score reductions and disability weights, we converted the estimated treatment effect into WELLBY-SDs by program and area of operation, an elaboration made possible by HLI’s careful work and using their estimated effect sizes. I reviewed their methodology and was ultimately very satisfied— I expect you may want to dig into this in more detail. This also ultimately allows the direct comparison with cash transfers.
I pressure-tested this a few ways: by comparing with the linearized-DALY approach from our first evaluation, from treating the pre-post data as evidence in a Bayesian update on conservative priors, and by modeling the observed shifts using the assumption of an exponential distribution in PHQ-9 scores (which appears in some literature on the topic). All these methods made the intervention look pretty cost-effective.
Crucially, FP’s bar for recommendation to members is GiveDirectly, and we estimate StrongMinds at roughly 6x GD. So even by our (risk-neutral) lights, StrongMinds is not competitive with GiveWell top charities.
A key piece of evidence is the 2002 RCT on which the program is based. I do think a lot—perhaps too much—hinges on this RCT. Ultimately, however, I think it is the most relevant way to develop a prior on the effectiveness of IPT-g in the appropriate context, which is why a Bayesian update on the pre-post data seems so optimistic: the observed effects are in line with the effect size from the RCT.
The effect sizes observed are very large, but it’s important to place in the context of StrongMinds’ work with severely traumatized populations. Incoming PHQ-9 scores are very, very high, so I think 1) it’s reasonable to expect some reversion to the mean in control groups, which we do see and 2) I’m not sure that our general priors about the low effectiveness of therapeutic interventions are likely to be well-calibrated here.
Overall, I agree that social desirability bias is a very cruxy issue here, and could bear on our rating of StrongMinds. But I think even VERY conservative assumptions about the role of this bias in the effect estimate would cause SM still to clear our bar in expectation.
Just a note on FP and our public-facing research: we’re in the position of prioritizing our research resources primarily to make recommendations to members, but at the same time we’re trying to do our best to provide a public good to the public and the EA community. I think we’re still not sure how to do this, and definitely not sure how to resource for it. We are working on this.
The page doesn’t say deprecated and GWWC are still linking to it and recommending it as a top charity. I do think your statements here should be enough for GWWC to remove them as a top charity.
This is what triggered the whole thing in the first place—I have had doubts about StrongMinds for a long time (I privately shared doubts with many EAs ~a year ago) but I didn’t think it was considered a top charity and think it’s a generally “fine” charity and we should collect more data in the area. Sam Atis’ blog led me to see it was considered a top charity, and that was what finally tipped me over the edge.
I didn’t find this on your website. I have looked into the WELLBY-SDs—I have serious doubts about it and I’m working on a blog explaining why, but I don’t feel confident enough yet explaining publicly why I think they aren’t the right metric. Hopefully this is coming soon. (Although I don’t think the transform really makes much difference to the outcome—this is a GIGO issue, not a modelling issue).
I haven’t seen this model, so I can’t comment. (Is it public somewhere?). I think it’s possible but unlikely it’s 6x more effective although my guess at the moment is that it’s less than 1x as effective.
That isn’t obvious to me, and I would welcome you publishing that analysis.
I think my main takeaway is my first one here. GWWC shouldn’t be using your recommendations to label things top charities. Would you disagree with that?
“I think my main takeaway is my first one here. GWWC shouldn’t be using your recommendations to label things top charities. Would you disagree with that?”
Yes, I think so- I’m not sure why this should be the case. Different evaluators have different standards of evidence, and GWWC is using ours for this particular recommendation. They reviewed our reasoning and (I gather) were satisfied. As someone else said in the comments, the right reference class here is probably deworming— “big if true.”
The message on the report says that some details have changed, but that our overall view is represented. That’s accurate, though there are some details that are more out of date than others. We don’t want to just remove old research, but I’m open to the idea that this warning should be more descriptive.
I’ll have to wait til next week to address more substantive questions but it seems to me that the recommend/don’t recommend question is most cruxy here.
EDIT:
On reflection, it also seems cruxy that our current evaluation isn’t yet public. This seems very fair to me, and I’d be very curious to hear GWWC’s take. We would like to make all evaluation materials public eventually, but this is not as simple as it might seem and especially hard given our orientation toward member giving.
Though this type of interaction is not ideal for me, it seems better for the community. If they can’t be totally public, I’d rather our recs be semi-public and subject to critique than totally private.
I’m afraid that doesn’t make me super impressed with GWWC, and it’s not easy for non-public reasoning to be debunked. Hopefully you’ll publish it and we can see where we disagree.
I think there’s a big difference between deworming and StrongMinds.
Our priors should tell us that “removing harmful parasites substantially improves peoples lives and can be done very cheaply” whereas our priors should also tell us (at least after a small amount of research) “treating severe depression is exceptionally difficult and costly”
If “big if true” is the story then it becomes extremely important to be doing high quality research to find out if it’s true. My impression (again from the outside) is that this isn’t happening with StrongMinds, and all indications seem to point towards them being extremely avoidant of any serious data analysis.
“big if true” might be a good analogy, but if that’s the case StrongMinds needs to be going in a very different direction than what they appear (again from the outside) to be doing.
I agree the recommend / don’t recommend is my contention in this post. I would love to hear GWWC’s reasoning to see why are happy with their recommendation.
Simon, I loved your post!
But I think this particular point is a bit unfair to GWWC and also just factually inaccurate.
For a start GWWC do not “recommend” Strong Minds. They very clearly recommend giving to an expert-managed Fund where an expert grantmaker can distribute the money and they do not recommend giving StrongMinds (or to Deworm the World, or AMF, etc). They say that repeatedly across their website, e.g. here. They then also have some charities that they class as “top rated” which they very clearly say are charities that have been “top rated” by another independent organisation that GWWC trusts.
I think this makes sense. Lets consider GWWC’s goals here. GWWC exist to serve and grow its community of donors. I expect that maintaining a broad list of charities on their website across cause areas and providing a convenient donation platform for those charities is the right call for GWWC to achieve those goals, even if some of those charities are less proven. Personally as a GWWC member I very much appreciate they have such a broad a variety of charities (e.g., this year, I donated to one of ACE’s standout charities and it was great to be able to do so on the GWWC page.) Note again this is a listing for donors convenience and not an active recommendation.
My other though is that GWWC has a tiny and very new research team. So this approach of list all the FP “top rated” charities makes sense to me. Although I do hope that they can grow their team and take more of a role doing research like your critique and evaluating the evaluators / the Funds.
(Note on conflicts of interest: Some what tangential but for transparency I have a role at a different FP recommended charity so this could affect me.)
I suspect this is a reading comprehension thing which I am failing at (I know I have failed at this in the past) but I think there are roughly two ways in which GWWC is either explicitly or implicitly recommending StrongMinds.
Firstly, by labelling it as a “Top Charity” then to all but the most careful reader (and even a careful reader) will see this as some kind of endorsement or “recomendation” to use words at least somewhat sloppily.
Secondly, it does explicitly recommend StrongMinds:
Their #1 recommendation is “Donate to expert-managed funds” and their #2 recommendation is “Donate to charities recommended by trusted charity evaluators”. They say:
At the top of that section, so it is clear to me the recommendation extends across the whole section. I agree with you they advise expert-managed funds above StrongMinds, but I don’t think that’s the same.
I also think it makes sense. My only complaint with GWWC is they aren’t open about what the process is for accepting a recommendation from a trusted advisor and their process doesn’t include some explicit “public details of the recommendation”. (The point is made most eloquently by Jeff here.
I think you are conflating two things here. One is GWWC listing a charity which you can donate to. Another is labelling it as “Top-rated”. For example, I can donate to GiveDirectly, SCI, Deworm the World via GWWC, but none of those are labeled as “Top-rated”:
(Note that StrongMinds is listed 4th in that category, on the very first page)
All I’m asking is for GWWC to remove the “Top-rated” label.
It might not be an active recommendation (although as I pointed out, I believe it is) but it’s clear an implicit recommendation.
All the more reason to have some simple rules for what is included. Allow recommendations to go out of date and don’t recommend things where the reasoning isn’t public. None of those rules are especially arduous for a small team to maintain.
Oh dear, no my bad. I didn’t at all realise “top rated” was a label they applied to Strong Minds but not to Give Directly and SCI and other listed charities, and thought you were suggesting StrongMinds be delisted from the site. I still think it makes sense for GWWC to (so far) be trusting other research orgs, and I do think they have acted sensibly (although have room to grow in providing a checks and balance). But I also seemed to have misundestood your point somewhat, so sorry about that.
I agree that beforemy post GWWC hadn’t done anything wrong.
At this point I think that GWWC should be able to see that their current process for labelling top-rated charities is not optimal and they should be changing it. Once they do that I would fully expect that label to disappear.
I’m disappointed that they don’t seem to agree with me, and seem to think that no immediate action is required. Obviously that says more about my powers of persuasion than them though, and I expect once they get back to work tomorrow and they actually look in more detail they change their process.
Hi Simon,
I’m back to work and able to reply with a bit more detail now (though also time-constrained as we have a lot of other important work to do this new year :)).
I still do not think any (immediate) action on our part is required. Let me lay out the reasons why:
(1) Our full process and criteria are explained here. As you seem to agree with from your comment above we need clear and simple rules for what is and what isn’t included (incl. because we have a very small team and need to prioritize). Currently a very brief summary of these rules/the process would be: first determine which evaluators to rely on (also note our plans for this year) and then rely on their recommendations. We do not generally have the capacity to review individual charity evaluations, and would only do so and potentially diverge from a trusted evaluator’s recommendation under exceptional circumstances. (I don’t believe we have had such a circumstance this giving season, but may misremember)
(2) There were no strong reasons to diverge with respect to FP’s recommendation of StrongMinds at the time they recommended them—or to do an in-depth review of FP’s evaluation ourselves—and I think there still aren’t. As I said before, you make a few useful points in your post but I think Matt’s reaction and the subsequent discussion satisfactorily explain why Founders Pledge chose to recommend StrongMinds and why your comments don’t (immediately) change their view on this: StrongMinds doesn’t need to meet GiveWell-tier levels of confidence and easily clears FP’s bar in expectation—even with the issues you mention having been taken into account—and nearly all the decision-relevant reasoning is already available publicly in the 2019 report and HLI’s recent review. I would of course be very interested and we could reconsider our view if any ongoing discussion brings to light new arguments or if FP is unable to back up any claims they made, but so far I haven’t seen any red or even orange flags.
(3) The above should be enough for GWWC to not prioritize taking any action related to StrongMinds at the moment, but I happen to have a bit more context here than usual as I was a co-author on the 2019 FP report on StrongMinds, and none of the five issues you raise are a surprise/new to me or change my view of StrongMinds very much. Very briefly on each (note: I don’t have much time / will mostly leave this to Matt / some of my knowledge may be outdated or my memory may be off):
I agree the overall quality of evidence is far short from e.g. GiveWell’s standards (cf. Matt’s comments—and would have agreed on this back in 2019. At this point, I certainly wouldn’t take FP’s 2019 cost-effectiveness analysis literally: I would deflate the results by quite a bit to account for quality of evidence, and I know FP have done so internally for the past ~2 years at least. However, AFAIK such accounting—done reasonably—isn’t enough to change the overall conclusion of StrongMinds meeting the cost-effectiveness bar in wellbeing terms. I should also note that HLI’s cost-effectiveness analysis seems to take into account more pieces of evidence, though I haven’t reviewed it; just skimmed it.
As you say yourself, The 2019 FP report already accounted for social desirability bias to some extent, and it further highlights this bias as one of its key uncertainties (section 3.8, p.31).
I disagree with depression being overweighted here for various reasons, including that DALYs plausibly underweight mental health (see section 1, p.8-9 of the FP mental health report. Also note that HLI’s recent analysis—AFAIK—doesn’t rely on DALY’s in any way.
I don’t think the reasons StrongMinds mention for not collecting more evidence (than they already are) are as unreasonable as you seem to think. I’d need to delve more into the specifics to form a view here, but just want to reiterate StrongMinds’s first reason that running high-quality studies is generally very expensive, and may often not be the best decision for a charity from a cost-effectiveness standpoint. Even though I think the sector as a whole could probably still do with more (of the right type of) evidence generation, from my experience I would guess it’s also relatively common charities collect more evidence (of the wrong kind) than would be optimal.
I don’t like what I see in at least some of the examples of communication you give—and if I were evaluating StrongMinds currently I would certainly want to give them this feedback (in fact I believe I did back in 2018, which I think prompted them to make some changes). However, though I’d agree that these provide some update on how thoroughly one should check claims StrongMinds makes more generally, I don’t think they should meaningfully change one’s view on the cost-effectiveness of StrongMinds’s core work.
(4) Jeff suggested (and some others seem to like) the idea of GWWC changing its inclusion criteria and only recommending/top-rating organisations for which an up-to-date public evaluation is available. This is something we discussed internally in the lead-up to this giving season, but we decided against it and I still feel that was and is the right decision (though I am open to further discussion/arguments):
There are only very few charities for which full public and up-to-date evaluations are available, and coverage for some worldviews/promising cause areas is structurally missing. In particular, there are currently hardly any full public and up-to-date evaluations in the mental health/subjective well-being, longtermist and “meta” spaces. And note that - by this standard—we wouldn’t be able to recommend any funds except for those just regranting to already-established recommendations.
If the main reason for this was that we don’t know of any cost-effective places to donate in these areas/according to these worldviews, I would have agreed that we should just go with what we know or at least highlight that standards are much lower in these areas.
However, I don’t think this is the case: we do have various evaluators/grantmakers looking into these areas (though too few yet IMO!) and arguably identifying very cost-effective donation opportunities (in expectation), but they often don’t prioritise sharing these findings publicly or updating public evaluations regularly. Having worked at one of those myself (FP), my impression is this is generally for very good reasons, mainly related to resource constraints/prioritisation as Jeff notes himself.
In an ideal world—where these resource constraints wouldn’t exist—GWWC would only recommend charities for which public, up-to-date evaluations are available. However, we do not live in that ideal world, and as our goal is primarily to provide guidance on what are the best places to give to according to a variety of worldviews, rather than what are the best explainable/publicly documented places to give, I think the current policy is the way to go.
Obviously it is very important that we are transparent about this, which we aim to do by clearly documenting our inclusion criteria, explaining why we rely on our trusted evaluators, and highlighting the evidence that is publicly available for each individual charity. Providing this transparency has been a major focus for us this giving season, and though I think we’ve made major steps in the right direction there’s probably still room for improvement: any feedback is very welcome!
Note that one reason why more public evaluations would seem to be good/necessary is accountability: donors can check and give feedback on the quality of evaluations, providing the right incentives and useful information to evaluators. This sounds great in theory, but in my experience public evaluation reports are almost never read by donors (this post is an exception, which is why I’m so happy with it, even though I don’t agree with the author’s conclusions), and they are a very high resource cost to create and maintain—in my experience writing a public report can take up about half of the total time spent on an evaluation (!). This leaves us with an accountability and transparency problem that I think is real, and which is one of the main reasons for our planned research direction this year at GWWC.
Lastly, FWIW I agree that we actively recommend StrongMinds (and this is our intention), even though we generally recommend donors to give to funds over individual charities.
I believe this covers (nearly) all of the GWWC-related comments I’ve seen here, but please let me know if I’ve missed anything!
This is an excellent response from a transparency standpoint, and increases my confidence in GWWC even though I don’t agree with everything in it.
One interesting topic for a different discussion—although not really relevant to GWWC’s work—is the extent to which recommenders should condition an organization’s continued recommendation status on obtaining better data if the organization grows (or even after a suitable period of time). Among other things, I’m concerned that allowing recommendations that were appropriate under criteria appropriate for a small/mid-size organization to be affirmed on the same evidence as an organization grows could disincentivize organizations from commissioning RCTs where appropriate. As relevant here, my take on an organization not having a better RCT is significantly different in the context of an organization with about $2MM a year in room for funding (which was the situation when FP made the recommendation, p. 31 here) than one that is seeking to raise $20MM over the next two years.
Thanks for the response!
FWIW I’m not asking for immediate action, but a reconsideration of the criteria for endorsing a recommendation from a trusted evaluator.
I’m not proposing changing your approach to recommending funds, but for recommending charities. In cases where a field has only non-public or stale evaluations then fund managers are still in a position to consider non-public information and the general state of the field, check in with evaluators about what kind of stale the current evaluations are at, etc. And in these cases I think the best you can do is say that this is a field where GWWC currently doesn’t have any recommendations for specific charities, and only recommends giving via funds.
I wasn’t suggesting you were, but Simon certainly was. Sorry if that wasn’t clear.
As GWWC gets its recommendations and information directly from evaluators (and aims to update its recommendations regularly), I don’t see a meaningful difference here between funds vs charities in fields where there are public up-to-date evaluations and where there aren’t: in both cases, GWWC would recommend giving to funds over charities, and in both cases we can also highlight the charities that seem to be the most cost-effective donation opportunities based on the latest views of evaluators. GWWC provides a value-add to donors here, given some of these recommendations wouldn’t be available to them otherwise (and many donors probably still prefer to donate to charities over donating to funds / might not donate otherwise).
Sorry, yes, I forgot your comment was primarily a response to Simon!
I’m generally comfortable donating via funds, but this requires a large degree of trust in the fund managers. I’m saying that I trust them to make decisions in line with the fund objectives, often without making their reasoning public. The biggest advantage I see to GWWC continuing to recommend specific charities is that it supports people who don’t have that level of trust in directing their money well. This doesn’t work without recommendations being backed by public current evaluations: if it just turns into “GWWC has internal reasons to trust FP which has internal reasons to recommend SM” then this advantage for these donors is lost.
Note that this doesn’t require that most donors read the public evaluations: these lower-trust donors still (rightly!) understand that their chances of being seriously misled are much lower if an evaluator has written up a public case like this.
So in fields where there are public up-to-date evaluations I think it’s good for GWWC to recommend funds, with individual charities as a fallback. But in fields where there aren’t, I think GWWC should recommend funds only.
What to do about people who can’t donate to funds is a tricky case. I think what I’d like to see is funds saying something like, if you want to support our work the best thing is to give to the fund, but the second best is to support orgs X, Y, Z. This recommendation wouldn’t be based on a public evaluation, but just on your trust in them as a funder.
I especially think it’s important to separate when someone would be happy giving to a fund if not for the tax etc consequences vs when someone wants the trust/public/epistemic/etc benefits of donating to a specific charity based on a public case.
I think trust is one of the reasons why a donor may or may not decide to give to a fund over a charity, but there are others as well, e.g. a preference for supporting more specific causes or projects. I expect donors with these other reasons (who trust evaluators/fund managers but would still prefer to give to individual charities (as well)) will value charity recommendations in areas for which there are no public and up-to-date evaluations available.
Note that this is basically equivalent to the current situation: we recommend funds over charities but highlight supporting charities as the second-best thing, based on recommendations of evaluators (who are often also fund managers in their area).
Thinking more, other situations in which a donor might want to donate to specific charities despite trusting the grantmaker’s judgement include:
Preference adjustments. Perhaps you agree with a fund in general, but you think they value averting deaths too highly relative to improving already existing lives. By donating to one of the charities they typically fund that focuses on the latter you might shift the distribution of funds in that direction. Or maybe not; your donation also has the effect of decreasing how much additional funding the charity needs, and the fund might allocate more elsewhere.
Ops skepticism. When you donate through a fund, in addition to trusting the grantmakers to make good decisions you’re also trusting the fund’s operations staff to handle the money properly and that your money won’t be caught up in unrelated legal trouble. Donating directly to a charity avoids these risks.
Yeah agreed. And another one could be as a way of getting involved more closely with a particularly charity when one wants to provide other types of support (advice, connections) in addition to funding. E.g. even though I don’t think this should help a lot, I’ve anecdotally found it helpful to fund individual charities that I advise, because putting my personal donation money on the line motivates me to think even more critically about how the charity could best use its limited resources.
Thanks again for engaging in this discussion so thoughtfully Jeff! These types of comments and suggestions are generally very helpful for us (even if I don’t agree with these particular ones).
Fair enough. I think one important thing to highlight here is that though the details of our analysis have changed since 2019, the broad strokes haven’t — that is to say, the evidence is largely the same and the transformation used (DALY vs WELLBY), for instance, is not super consequential for the rating.
The situation is one, as you say, of GIGO (though we think the input is not garbage) and the main material question is about the estimated effect size. We rely on HLI’s estimate, the methodology for which is public.
I think your (2) is not totally fair to StrongMinds, given the Ozler RCT. No matter how it turns out, it will have a big impact on our next reevaluation of StrongMinds.
Edit: To be clearer, we shared updated reasoning with GWWC but the 2019 report they link, though deprecated, still includes most of the key considerations for critics, as evidenced by your observations here, which remain relevant. That is, if you were skeptical of the primary evidence on SM, our new evaluation would not cause you to update to the other side of the cost-effectiveness bar (though it might mitigate less consequential concerns about e.g. disability weights).
And with deworming, there are stronger reasons to be willing to make moderately significant funding decisions on medium-quality evidence: another RCT would cost a lot and might not move the needle that much due to the complexity of capturing/measuring the outcomes there, while it sounds like a well-designed RCT here would be in the ~ $1MM range and could move the needle quite a bit (potentially in either direction from where I think the evidence base is currently).
Thanks for this! Useful to get some insight into the FP thought process here.
(emphasis added)
Minor nitpick (I haven’t personally read FP’s analysis / work on this):
Appendix C (pg 31) details the recruitment process, where they teach locals about what depression is prior to recruitment. The group they sample from are groups engaging in some form of livelihood / microfinance programmes, such as hairdressers. Other groups include churches and people at public health clinic wait areas. It’s not clear to me based on that description that we should take at face value that the reason for very very high incoming PHQ-9 scores is that these groups are “severely traumatised” (though it’s clearly a possibility!)
RE: priors about low effectiveness of therapeutic interventions—if the group is severely traumatised, then while I agree this might make us feel less skeptical about the astounding effect size, it should also make us more skeptical about the high success rates, unless we have reason to believe that severe depression in severely traumatised populations in this context is easier to treat than moderate / mild depression.
Thank you for linking to that appendix describing the recruitment process. Could the initial high scores be driven by demand effects from SM recruiters describing depression symptoms and then administering the PHQ-9 questionnaire? This process of SM recruiters describing symptoms to participants before administering the tests seems reminiscent of old social psychology experiments (e.g. power posing being driven in part by demand effects).
No worries! Yeah, I think that’s definitely plausible, as is something like this (“People in targeted communities often incorrectly believe that StrongMinds will provide them with cash or material goods and may therefore provide misleading responses when being diagnosed”). See this comment for another perspective.
I think the main point I was making is just that it’s unclear to me that high PHQ-9 scores in this context necessarily indicate a history of severe trauma etc.
While StrongMinds runs a programme that explicitly targets refugees, who’re presumably much more likely to be traumatized, this made up less than 8% of their budget in 2019.
However, some studies seem to find very high rates of depression prevalence in Uganda (one non-representative meta-analysis found a prevalence of 30%). If a rate like this did characterise the general population, then I wouldn’t be surprised that the communities they work in (which are typically poorer / rural / many are in Northern Uganda) have very high incoming PHQ scores for reasons genuinely related to high psychological distress.
Whether they are a hairdresser or an entrepreneur living in this context seems like it could be pulling on our weakness to the conjunction fallacy. I.e., it seems less likely that someone has a [insert normal sounding job] and trauma while living in an ex-warzone than what we’d guess if we only knew th at someone was living in an ex-warzone.
Oh that’s interesting RE: refugees! I wonder what SM results are in that group—do you know much about this?
Iirc, the conjunction fallacy iirc is something like:
For the following list of traits / attributes, is it more likely that “Jane Doe is a librarian” or “Jane Doe is a librarian + a feminist”? And it’s illogical to pick the latter because it’s a perfect subset of the former, despite it forming a more coherent story for system 1.
But in this case, using the conjunction fallacy as a defence is like saying “i’m going to recruit from the ‘librarian + feminist’ subset for my study, and this is equivalent to sampling all librarians”, which I think doesn’t make sense to me? Clearly there might be something about being both a librarian + feminist that makes you different to the population of librarians, even if it’s more likely for any given person to be a librarian than a ‘librarian + feminist’ by definition.
I might be totally wrong and misunderstanding this though! But also to be clear, I’m not actually suggesting that just because someone’s a hairdresser or a churchgoer that they can’t have a history of severe trauma. I’m saying when Matt says “The effect sizes observed are very large, but it’s important to place in the context of StrongMinds’ work with severely traumatized populations”, I’m interpreting this to mean that due to the population having a history of severe trauma, we should expect larger effect sizes than other populations with similar PHQ-9 scores. But clearly there are different explanations for high initial PHQ-9 scores that don’t involve severe trauma, so it’s not clear that I should assume there’s a history of severe trauma based on just the PHQ-9 score or the recruitment methodology.
The StrongMinds pre-post data I have access to (2019) indicates that the Refugee programme has pre-post mean difference in PHQ9 of 15.6, higher than the core programme of 13.8, or their peer / volunteer-delivered or youth programmes (13.1 and 12). They also started with the highest baseline PHQ: 18.1 compared to 15.8 in the core programme.
Is there any way we can get more details on this? I recently made a blogpost using Bayesian updates to correct for post-decision surprise in GiveWell’s estimates, which led to a change in the ranking of New Incentives from 2nd to last in terms of cost effectiveness among Top Charities. I’d imagine (though I haven’t read the studies) that the uncertainty in the Strong Minds CEA is / should be much larger.
For that reason, I would have guessed that Strong Minds would not fare well post-Bayesian adjustment, but it’s possible you just used a different (reasonable) prior than I did, or there is some other consideration I’m missing?
Also, even risk neutral evaluators really should be using Bayesian updates (formally or informally) in order to correct for post-decision surprise. (I don’t think you necessarily disagree with me on this, but it’s worth emphasizing that valuing GW-tier levels of confidence doesn’t imply risk aversion.)
“we estimate StrongMinds at roughly 6x GD”—this seems to be about 2⁄3 what HLI estimate the relative impact to be (https://forum.effectivealtruism.org/posts/zCD98wpPt3km8aRGo/happiness-for-the-whole-household-accounting-for-household) - it’s not obvious to me how and why your estimates differ—are you able to say what is the reason for the difference? (Edited to update to a more recent analysis by HLI)
FP’s model doesn’t seem to be public, but CEAs are such an uncertain affair that aligning even to 2⁄3 level is a pretty fair amount of convergence.
Thanks for writing this post!
I feel a little bad linking to a comment I wrote, but the thread is relevant to this post, so I’m sharing in case it’s useful for other readers, though there’s definitely a decent amount of overlap here.
TL; DR
I personally default to being highly skeptical of any mental health intervention that claims to have ~95% success rate + a PHQ-9 reduction of 12 points over 12 weeks, as this is is a clear outlier in treatments for depression. The effectiveness figures from StrongMinds are also based on studies that are non-randomised and poorly controlled. There are other questionable methodology issues, e.g. surrounding adjusting for social desirability bias. The topline figure of $170 per head for cost-effectiveness is also possibly an underestimate, because while ~48% of clients were treated through SM partners in 2021, and Q2 results (pg 2) suggest StrongMinds is on track for ~79% of clients treated through partners in 2022, the expenses and operating costs of partners responsible for these clients were not included in the methodology.
(This mainly came from a cursory review of StrongMinds documents, and not from examining HLI analyses, though I do think “we’re now in a position to confidently recommend StrongMinds as the most effective way we know of to help other people with your money” seems a little overconfident. This is also not a comment on the appropriateness of recommendations by GWWC / FP)
(commenting in personal capacity etc)
Edit:
Links to existing discussion on SM. Much of this ends up touching on discussions around HLI’s methodology / analyses as opposed to the strength of evidence in support of StrongMinds, but including as this is ultimately relevant for the topline conclusion about StrongMinds (inclusion =/= endorsement etc):
StrongMinds should not be a top-rated charity (yet)
Comments (1, 2) about outsider perception of HLI as an advocacy org
Comment about ideal role of an org like HLI, as well as trying to decouple the effectiveness of StrongMinds with whether or not WELLBYs / subjective wellbeing scores are valuable or worth more research on the margin.
Twitter exchange between Berk Özler and Johannes Haushofer, particularly relevant given Özler’s role in an upcoming RCT of StrongMinds in Uganda (though only targeted towards adolescent girls)
Evaluating StrongMinds: how strong is the evidence? and the comment section. In particular:
Thread 1
Thread 2
James Snowden’s analysis of household spillovers
GiveWell’s Assessment of Happier Lives Institute’s Cost-Effectiveness Analysis of StrongMinds
Comments in the post: The Happier Lives Institute is funding constrained and needs you!
Greg claims “study registration reduces expected effect size by a factor of 3”
Topline finding weighted 13% from StrongMinds RCT, where d = 1.72
“this is a very surprising mistake for a diligent and impartial evaluator to make”
Greg commits to: “donat[ing] 5k USD if the [Baird] RCT reports an effect size greater than d = 0.4 − 2x smaller than HLI’s estimate of ~ 0.8, and below the bottom 0.1% of their monte carlo runs.”
Comment thread on discussion being harsh and “epistemic probation”
James and Alex push back on some claims they consider to be misleading.
Learning from our mistakes: how HLI plans to improve
Update on the Baird RCT
I want to second this! Not a mental health expert, but I have depression and so have spent a fair amount of time looking into treatments / talking to doctors / talking to other depressed people / etc.
I would consider a treatment extremely good if it decreased the amount of depression a typical person experienced by (say) 20%. If a third of people moved from the “depression” to “depression-free” category I would be very, very impressed. Ninety-five percent of people moving from “depressed” to “depression free” sets off a lot of red flags for me, and makes me think the program has not successfully measured mental illness.
(To put this in perspective: 95% of people walking away depression-free would make this far effective than any mental health intervention I’m aware of at any price point in any country. Why isn’t anyone using this to make a lot of money among rich American patients?)
I think some adjustment is appropriate to account for the fact that people in the US are generally systematically different from people in (say) Uganda in a huge range of ways which might lead to significant variation in the quality of existing care, or the nature of their problems and their susceptibility to treatment. As a general matter I’m not necessarily surprised if SM can relatively easily achieve results that would be exceptional or impossible among very different demographics.
That said, I don’t think these kinds of considerations explain a 95% cure rate, I agree that sounds extreme and intuitively implausible.
Thank you. I’m a little ashamed to admit it, but in an earlier draft I was much more explicit about my doubts about the effectiveness of SM’s intervention. I got scared because it rested too much on my geneal priors about intervention and I hadn’t finished enough of a review of the literature in which to call BS. (Although I was comfortable doing so privately, which I guess tells you that I haven’t learned from the FTX debacle)
I also noted the SM partners issue, although I couldn’t figure out whether or not it was the case re: costs so I decided to leave it out. I would definitely like to see SM address that concern.
HLI do claim to have seen some private data from SM, so it’s unlikely (but plausible) that HLI do have enough confidence, but everyone else is still in the dark.
I’m a researcher at SoGive conducting an independent evaluation of StrongMinds which will be published soon. I think the factual contents of your post here are correct. However, I suspect that after completing the research, I would be willing to defend the inclusion of StrongMinds on the GGWC list, and that the SoGive write-up will probably have a more optimistic tone than your post. Most of our credence comes from the wider academic literature on psychotherapy, rather than direct evidence from StrongMinds (which we agree suffers from problems, as you have outlined).
Regarding HLI’s analysis, I think it’s a bit confusing to talk about this without going into the details because there are both “estimating the impact” and “reframing how we think about moral-weights” aspects to the research. Ascertaining what the cost and magnitude of therapy’s effects are must be considered separately from the “therapy will score well when you use subjective-well-being as the standard by which therapy and cash transfers and malaria nets are graded” issue. As of now I do roughly think that HLI’s numbers regarding what the costs and effect sizes of therapy are on patients are in the right ballpark. We are borrowing the same basic methodology for our own analysis. You mentioned being confused by the methodology - there are a few points that still confuse me as well, but we’ll soon be publishing a spreadsheet model with a step by step explainer on the aspects of the model that we are borrowing, which may help.
If you ( @Simon_M or anyone else wishing to work at a similar level of analysis) is planning on diving into these topics in depth, I’d love to get in touch on the Forum and exchange notes.
Regarding the level of evidence: SoGive’s analysis framework outlines a “gold standard” for high impact, with “silver” and “bronze” ratings assigned to charities with lower-but-still-impressive cost-effectiveness ratings. However, we also distinguish between “tentative” ratings and “firm” ratings, to acknowledge that some high impact opportunities are based on more speculative estimates which may be revised as more evidence comes in. I don’t want to pre-empt our final conclusions on StrongMinds, but I wouldn’t be surprised if “Silver (rather than Gold)” and/or “Tentative (rather than Firm)” ended up featuring in our final rating. Such a conclusion still would be a positive one, on the basis of which donation and grant recommendations could be made.
There is precedent for effective altruists recommending donations to charities for which the evidence is still more tentative. Consider that Givewell recommends “top charities”, but also recommends less proven potentially cost-effective and scalable programs (formerly incubation grants). Identifying these opportunities allows the community to explore new interventions, and can unlock donations that counterfactually would not have been made, as different donors may make different subjective judgment calls about some interventions, or may be under constraints as to what they can donate to.
Having established that there are different criteria that one might look at in order to determine when an organization should be included in a list, and that more than one set of standards which may be applied, the question arises: What sort of standards does the GWWC top charities list follow, and is StrongMinds really out of place with the others? Speaking the following now personally, informally and not on behalf of any current or former employer: I would actually say that StrongMinds has much more evidence backing than many of the other charities on this list (such as THL, Faunalytics, GFI, WAI, which by their nature don’t easily lend themselves to RCT data). Even if we restrict our scope to the arena of direct (excluding e.g. excluding pandemic research orgs) global health interventions, I wouldn’t be surprised if bright and promising potential stars such as Suvita and LEEP are actually at a somewhat similar stage as StrongMinds—they are generally evidence-based enough to deserve their endorsement on this list, but I’m not sure they’ve been as thoroughly vetted by external evaluators the way more established organizations such as Malaria Consortium might be. Because of all this, I don’t think StrongMinds seems particularly out of place next to the other GWWC recommendations. (Bearing in mind again that I want to speak casually as an individual for this last paragraph, and I am not claiming special knowledge of all the orgs mentioned for the purposes of this statement).
Finally, it’s great to see posts like this on the EA forum, thanks for writing it!
I might be being a bit dim here (I don’t have the time this week to do a good job of this), but I think of all the orgs evaluating StrongMinds, SoGive’s moral weights are most likely to find favourably for StrongMinds. Given that, I wonder what you expect you’d rate them at if you altered your moral weights to be more inline with FP and HLI?
(Source)
This is a ratio of 4:1 for averting a year of severe depression vs doubling someone’s consumption.
For context Founders Pledge who have a ratio somewhere around 1.3:1. Income doubling : DALY is 0.5 : 1. And severe depression corresponds to a DALY weighting of 0.658 in their CEA. (I understand they are shifting to a WELLBY framework like HLI, but I don’t think it will make much difference).
HLI is harder to piece together, but roughly speaking they see doubling income as having 1.3 WELLBY and severe depression has having a 1.3 WELLBY effect. A ratio of 1.3:1 (similar to FP)
Thanks for your question Simon, and it was very eagle-eyed of you to notice the difference in moral weights. Good sleuthing! (and more generally, thank you for provoking a very valuable discussion about StrongMinds)
I run SoGive and oversaw the work (then led by Alex Lawsen) to produce our moral weights. I’d be happy to provide further comment on our moral weights, however that might not be the most helpful thing. Here’s my interpretation of (the essence of) your very reasonable question:
I have a simple answer to this: no, it isn’t.
Let me flesh that out. We have (at least) two sources of information:
Academic literature
Data from StrongMinds (e.g. their own evaluation report on themselves, or their regular reporting)
And we have (at least) two things we might ask about:
(a) How effective is the intervention that StrongMinds does, including the quality of evidence for it?
(b) How effective is the management team at StrongMinds?
I’d say that the main crux is the fact that our assessment of the quality of evidence for the intervention (item (a)) is based mostly on item 1 (the academic literature) and not on item 2 (data from StrongMinds).
This is the driver of the comments made by Ishaan above, not the moral weights.
And just to avoid any misunderstandings, I have not here said that the evidence base from the academic literature is really robust—we haven’t finished our assessment yet. I am saying that (unless our remaining work throws up some surprises) it will warrant a more positive tone than your post, and that it may well demonstrate a strong enough evidence base + good enough cost-effectiveness that it’s in the same ballpark as other charities in the GWWC list.
I don’t understand how that’s possible. If you put 3x the weight on StrongMind’s cost-effectiviness viz-a-vis other charities, changing this must move the needle on cost-effectiveness more than anything else. It’s possible to me it could have been “well into the range of gold-standard” and now it’s “just gold-standard” or “silver-standard”. However if something is silver standard, I can’t see any way in which your cost-effectivness being adjusted down by 1/3rd doesn’t massively shift your rating.
I feel like I’m being misunderstood here. I would be very happy to speak to you (or Ishaan) on the academic literature. I think probably best done in a more private forum so we can tease out our differences on this topic. (I can think of at least one surprise you might not have come across yet).
Ishaan’s work isn’t finished yet, and he has not yet converted his findings into the SoGive framework, or applied the SoGive moral weights to the problem. (Note that we generally try to express our findings in terms of the SoGive framework and other frameworks, such as multiples of cash, so that our results are meaningful to multiple audiences).
Just to reiterate, neither Ishaan nor I have made very strong statements about cost-effectiveness, because our work isn’t finished yet.
That sounds great, I’ll message you directly. Definitely not wishing to misunderstand or misinterpret—thank you for your engagement on this topic :-)
To expand a little on “this seems implausible”: I feel like there is probably a mistake somewhere in the notion that anyone involves thinks that <doubling income as having 1.3 WELLBY and severe depression has having a 1.3 WELLBY effect.>
The mistake might be in your interpretation of HLI’s document (it does look like the 1.3 figure is a small part of some more complicated calculation regarding the economic impacts of AMF and their effect on well being, rather than intended as a headline finding about the cash to well being conversion rate). Or it could be that HLI has an error or has inconsistencies between reports. Or it could be that it’s not valid to apply that 1.3 number to “income doubling” SoGive weights for some reason because it doesn’t actually refer to the WELLBY value of doubling.
I’m not sure exactly where the mistake is, so it’s quite possible that you’re right, or that we are both missing something about how the math behind this works which causes this to work out, but I’m suspicious because it doesn’t really fit together with various other pieces of information that I know. For instance - it doesn’t really square with how HLI reported Psychotherapy is 9x GiveDirectly when the cost of treating one person with therapy is around $80, or how they estimated that it took $1000 worth of cash transfers to produce 0.92 SDs-years of subjective-well-being improvement (“totally curing just one case of severe depression for a year” should correspond to something more like 2-5 SD-years).
I wish I could give you a clearer “ah, here is where i think the mistake is” or perhaps a “oh, you’re right after all” but I too am finding the linked analysis a little hard to follow and am a bit short on time (ironically, because I’m trying to publish a different piece of Strongminds analysis before a deadline). Maybe one of the things we can talk about once we schedule a call is how you calculated this and whether it works? Or maybe HLI will comment and clear things up regarding the 1.3 figure you pulled out and what it really means.
Replied here
Good stuff. I haven’t spent that much time looking at HLIs moral weights work but I think the answer is “Something is wrong with how you’ve constructed weights, HLI is in fact weighing mental health harder than SoGive”. I think a complete answer to this question requires me checking up on your calculations carefully, but I haven’t done so yet, so it’s possible that this is right.
If if were true that HLI found anything on the order of roughly doubling someone’s consumption improved well being as much as averting 1 case of depression, that would be very important as it would mean that SoGive moral weights fail some basic sanity checks. It would imply that we should raise our moral weight on cash-doubling to at least match the cost of therapy even under a purely subjective-well-being oriented framework to weighting. (why not pay 200 to double income, if it’s as good as averting depression and you would pay 200 to avert depression?) This seems implausible.
I haven’t actually been directly researching the comparative moral weights aspect, personally—I’ve been focusing primarily on <what’s the impact of therapy on depression in terms of effect size> rather than on the “what should the moral weights be” question (though I have put some attention to the “how to translate effect sizes into subjective intuitions” question, but that’s not quite the same thing). That said when I have more time I will look more deeply into this and check if our moral weights are failing some sort of sanity check on this order, but, I don’t think that they are.
Regarding the more general question of “where would we stand if we altered our moral weights to be something else”, ask me again in a month or so when all the spreadsheets are finalized, moral weights should be relatively easy to adjust once the analysis is done.
(as sanjay alludes to in the other thread, I do think all this is a somewhat separate discussion from the GWWC list—my main point with the GWWC list was that StrongMinds is not in the big picture actually super out of place with the others, in terms of how evidence-backed it is relative to the others, especially when you consider the big picture of the background academic literature about the intervention rather than their internal data. But I wanted to address the moral weights issue directly as it does seem like an important and separate point.)
I would recommend my post here. My opinion is—yes—SoGive’s moral weights do fail a basic sanity check.
1 year of averted depression is 4 income doublings
1 additional year of life (using GW life-expectancies for over 5s) is 1.95 income doublings.
ie SoGive would thinks depression is worse than death. Maybe this isn’t quite a “sanity check” but I doubt many people have that moral view.
I think cost-effectiveness is very important for this. StrongMinds isn’t so obviously great that we don’t need to consider the cost.
Yes, this is a great point which I think Jeff has addressed rather nicely in his new post. When I posted this it wasn’t supposed to be a critique of GWWC (I didn’t realise how bad the situation there was at the time) as much as a critique of StrongMinds. Now I see quite how bad it is, I’m honestly at a loss for words.
I replied in the moral weights post w.r.t. “worse than death” thing. (I think that’s a fundamentally fair, but fundamentally different point from what I meant re: sanity checks w.r.t not crossing hard lower bounds w.r.t. the empirical effects of cash on well being vs the empirical effect of mental health interventions on well being)
This is a great, balanced post which I appreciate thanks. Especially the point that there is a decent amount of RCT data for strongminds compared to other charities on the list.
Edit 03-01-23: I have now replied more elaborately here
Hi Simon, thanks for this post! I’m research director at GWWC, and we really appreciate people engaging with our work like this and scrutinising it.
I’m on holiday currently and won’t be able to reply much more in the coming few days, but will check this page again next Tuesday at the latest to see if there’s anything more I/the GWWC team need to get back on.
For now, I’ll just very quickly address your two key claims that GWWC shouldn’t have recommended StrongMinds as a top-rated charity and that we should remove it now, both of which I disagree with.
Our process and criteria for making charity recommendations are outlined here. Crucially, note that we generally don’t do (and don’t have capacity to do) individual charity research: we almost entirely rely on our trusted evaluators—including Founders Pledge—for our recommendations. As a research team, we plan to specialize in providing guidance on which evaluators to rely rather than in doing individual charity evaluation research.
In the case of StrongMinds, they are a top-rated charity primarily because Founders Pledge recommended them to us, as you highlight. There were no reasons for us to doubt the quality of FP’s research supporting this recommendation at the time, and though you make a few good points on StrongMinds that showcase some of the uncertainties/caveats/counterarguments involved in this recommendation, I think Matt Lerner adequately addresses these in his reply above, so I don’t see reason for us to consider diverging from FP’s recommendation now either.
I do have a takeaway from your post on our communication. On our website we currently state
“StrongMinds meets our criteria to be a top-rated charity because one of our trusted evaluators, Founders Pledge, has conducted an extensive evaluation highlighting its cost-effectiveness as part of its report on mental health.”
We then also highlight HLI’s recent report as evidence supporting this recommendation. However, I think we should have been/be clearer on the fact that it’s not only FP’s 2019 report that supports this recommendation, but their ongoing research, some of which isn’t public yet (even though the report still represents their overall view, as Matt Lerner mentions above). I’ll make sure to edit this.
Thanks again for your post, and I look forward to engaging more next week at the latest if there are any other comments/questions you or anyone else have.
I just want to add my support for GWWC here. I strongly support the way they have made decisions on what to list to date:
As a GWWC member who often donates through the GWWC platform I think it is great that they take a very broad brush and have lots of charities that people might see as top on the platform. I think if their list got to small they would not be able to usefully serve the GWWC donor community (or other donors) as well.
I would note that (contrary to what some of the comments suggest) that GWWC recommend giving to Funds and do recommend giving to these charities (so they do not explicitly recommend Strong Minds). In this light I see the listing of these charities not as recommendations but as convenience for donors who are going to be giving there.
I find GWWC very transparent. Simon says ideally “GWWC would clarify what their threshold is for Top Charity”. On that specific point I don’t see how GWWC could be any more clear. Every page explains that a top charity is one that has been listed as top by an evaluator GWWC trust. Although I do agree with Simon more description of how GWWC choose certain evaluators could be helpful.
That said I would love it if going forwards GWWC could find the time. To evaluate the evaluators and the Funds and their recommendations (for example I have some concerns about the LTFF and know others do too, I know there have been concerns about ACE in the past etc).
I would not want GWWC to unlist Strong Minds from their website but I could imagine them adding a section on the Strong Minds page saying “The GWWC team views” that says: “this is listed as it is a FP top but our personal views are that …. meaning this might or might not be a good place to give especially if you care about … etc”
(Conflict of interest note: I don’t work at GWWC or FP but I do work at a FP recommended charity and at a charity who’s recommendations make it into the GWWC criteria so I might be bias).
I agree, and I’m not advocating removing StrongMinds from the platform, just removing the label “Top-rated”. Some examples of charities on the platform which are not top-rated include: GiveDirectly, SCI, Deworm the World, Happier Lives Institute, Fish Welfare Initiative, Rethink Priorities, Clean Air Task Force...
I’m afraid to say I believe you are mistaken here, as I explained in my other comment. The recommendations section clearly includes top-charities recommended by trusted evaluators and explicitly includes StrongMinds. There is also a two-tier labelling of “Top-rated” and not-top-rated and StrongMinds is included in the former. Both of these are explicit recommendations afaic.
I’m not really complaining about transparency as much as I would like the threshold to include requirements for trusted evaluators to have public reasoning and a time-threshold on their recommendations.
Again, to repeat myself. Me either! I just want them to remove the “Top-rated” label.
Ah. Good point. Replied to the other thread here: https://forum.effectivealtruism.org/posts/ffmbLCzJctLac3rDu/strongminds-should-not-be-a-top-rated-charity-yet?commentId=TMbymn5Cyqdpv5diQ .
Recognizing GWWC’s limited bandwidth for individual charity research, what would you think of the following policy: When GWWC learns of a charity recommendation from a trusted recommender, it will post a thread on this forum and invite comments about whether the candidate is in the same ballpark as the median top-rated organization in that cause area (as defined by GWWC, so “Improving Human Well-Being”). Although GWWC will still show significant deference to its trusted evaluators in deciding how to list organizations, it will include one sentence on the organization’s description linking to the forum notice-and-comment discussion. It will post a new thread on each listed organization at 2-3 year intervals, or when there is reason to believe that new information may materially affect the charity’s evaluation.
Given GWWC’s role and the length of its writeups, I don’t think it is necessary for GWWC to directly state reasons why a donor might reasonably choose not to donate to the charity in question. However, there does need to be an accessible way for potential donors to discover if those reasons might exist. While I don’t disagree with using FP as a trusted evaluator, its mission is not primarily directed toward producing public materials written with GWWC-type donors in mind. Its materials do not meet the bar I suggested in another comment for advisory organizations to GWWC-type donors: “After engaging with the recommender’s donor-facing materials about the recommended charity for 7-10 minutes, most potential donors should have a solid understanding of the quality of evidence and degree of uncertainty behind the recommendation; this will often include at least a brief mention of any major technical issues that might significantly alter the decision of a significant number of donors.” That is not a criticism of FP because it’s not trying to make recommendations to GWWC-type donors.
So giving the community an opportunity to state concerns/reservations (if any) and link to the community discussion seems potentially valuable as a way to meet this need without consuming much in the way of limited GWWC research resources.
Thanks for the suggestion Jason, though I hope the longer comment I just posted will clarify why I think this wouldn’t be worth doing.
edited (see bottom)
I’d like to flag that I think it’s bad that my friend (yes I’m biased) has done a lot of work to criticise something (and I haven’t read pushback against that work) but won’t affect the outcome because of work that he and we cannot see.
Is there a way that we can do a little better than this?
Some thoughts:
Could he be allowed to sign an NDA to read Founder’s pledge’s work?
Would you be interested in forecasts that Stronger Minds wont be a GWWC top charity by say 2025?
Could I add this criticism and a summary of your response to Stronger Minds EA wiki page so that others can see this criticism and it doesn’t get lost?
Can anyone come up with other suggestions?
edits:
Changed “disregarded” the sentence with “won’t affect the outcome”
Tbh I think this is a bit unfair: his criticism isn’t being disregarded at all. He received a substantial reply from FP’s research director Matt Lerner—even while he’s on holiday—within a day, and Matt seems very happy to discuss this further when he’s back to work.
I should also add that almost all of the relevant work is in fact public, incl. the 2019 report and HLI’s analysis this year. I don’t think what FP has internally is crucial to interpreting Matt’s responses.
I do like the forecasting idea though :).
I am sure there is a better word than “disregarded”. Apologies for being grumpy, have edited.
This seems like legitimate criticism. Matt says so. But currently, it feels like nothing might happen as a result. You have secret info, end of discussion. This is a common problem within charity evaluation, I think—someone makes some criticism, someone disagrees and so it gets lost to the sands of time.
I guess my question is, how can this work better? How can this criticism be stored and how can your response of “we have secret info, trust us” be a bit more costly for you now (with appropriate rewards later).
If you are interested in forecasting, would you prefer a metaculus or manifold market?
Eg if you like manifold, you can bet here (there is a lot of liquidity and the market currently heavily thinks GWWC will revoke its recommendation. If you disagree you can win money that can be donated to GWWC and status. This is one way to tax and reward you for your secret info)
Is this form of the market the correct wording? If so I’ll write a metaculus version.
As I tried to clarify above, this is not a case of secret info having much—if any—bearing on a recommendation. As far as I’m aware, nearly all decision-relevant information is and has been available publicly, and where it isn’t Matt has already begun clarifying things and has offered to provide more context next week (see discussion between him and Simon above). I certainly can’t think of any secret info that is influencing GWWC’s decision here.
FWIW my personal forecast wouldn’t be very far from the current market forecast (probably closer to 30%), not because I think the current recommendation decision is wrong but for a variety of reasons, incl. StrongMinds’ funding gaps being filled to a certain extent by 2025; new data from the abovementioned RCT; the research community finding even better funding opportunities etc.
I’m fine with the wording: it’s technically “top-rated charity” currently but both naming and system may change over the coming years, as we’ll hopefully be ramping up research efforts.
Hmmmm this still feels like a bit of a dodge. If the work is all public, what specific thing has Simon missed or misunderstood or what are you going to change? Let’s give it two weeks, but if there is no secret info there ought to be an answer to that question.
Also, what do you expect the results of the RCT to be? And if you think they will be negative shouldn’t you remove the recommendation now?
Props for engaging here.
Hi Nathan, I don’t think the results of the RCT will be negative, just that they could cause us to update (in either direction) which adds uncertainty, though I’d admit that at a <50% forecast this could plausibly increase my forecast rather than lower it (though this isn’t immediately clear; depends on the interactions with the other reasons).
And I hope the more elaborate reply I just wrote to Simon answers your remaining question.
meta-comment: If you’re going to edit a comment, it would be useful to be specific and say how you edited the comment e.g. in this case, I think you changed the word “disregarded” to something weaker on further reflection.
Unfortunately that wouldn’t help, because the part of the point of looking at FP’s work would be to evaluate it. Another person saying “I looked at some work privately and I agree/disagree with it” doesn’t seem helpful to people trying to evaluate StrongMinds.
I sense it would be better than the status quo.
What do you think would be better outcome here?
Ideally from my point of view:
GWWC would clarify what their threshold is for Top Charity
GWWC would explain how they decide what is a Trusted Evaluator and when their evaluations count to be a Top Charity (this decision process would include evaluators publishing their reasoning)
FP would publish their reasoning
Reading comments from Matt (FP) and Sjir (GWWC), it sounds like the situation is:
FP performed a detailed public evaluation of SM, which they published in 2019.
This was sufficient for FP to recommend giving to SM.
Because FP is one of GWWC’s trusted evaluators, this was sufficient for GWWC to designate SM as top rated.
The public FP evaluation is now stale, though FP has additional unpublished information that is sufficient for them to still recommend SM. Due to resource constraints they haven’t been able to update their public evaluation.
It’s not clear to me what FP should have done differently: resource constraints are hard. The note at the top of the evaluation (which predates this post) is a good start, though it would be better if it included something like “As of fall 2022, we have continued to follow StrongMinds and still recommend them. We are planning a full update before the 2023 giving season.”
In the case of GWWC, I think one of the requirements they should have for endorsing recommendations from their trusted evaluators is that they be supported by public evaluations, and that those evaluations be current. I think in this case GWWC would ideally have moved SM from “top rated” to “listed” sometime in the past ~18m.
(As a practical matter, one way this could be implemented is that any time GWWC imports a charity recommendation from a trusted evaluator it includes the date of evaluation, and the import is only valid for, say, 2.5y from that date.)
Thanks Jeff, I think your summary is helpful and broadly correct, except for two (somewhat relevant) details:
GWWC didn’t recommend SM based on FP’s recommendation in 2019 but based on FP’s decision to still recommend SM as of this giving season (which is based on FP’s internal re-evaluation of SM).
I don’t expect there to be any new, decision-relevant information in FP’s recent internal re-evaluation that isn’t captured by the 2019 report + the recent HLI analysis (but I’m not sure about this—Matt can correct me if I’m wrong, though also see his comment here). Obviously the internal re-evaluation has extra “information” in the sense that FP has reviewed the HLI analysis, converted metrics to their new system, and run some extra tests, as Matt has explained, so maybe this is just semantics, but I think it’s relevant to the extent that a crux would be “FP is still recommending SM because of something only they know”.
I understand the reasons for your suggestion w.r.t. GWWC’s inclusion criteria—we’ve seriously considered doing this before—but I explain at length why I still think we shouldn’t under (4) here. Would welcome any further comments if you disagree!
Responded above, thanks!
I agree strongly here re: GWWC. I think it is very odd that they endorse a charity without a clear public explanation of why the charity is effective which could satisfy a mildly skeptical outsider. This is a bar that this clearly does not reach in my opinion. They don’t need to have the same evidential requirements as Givewell, but the list of charities they recommend is sufficiently long that they should prefer to have a moderately high bar for charities to make that list.
To admit my priors here: I am very skeptical of Strong Minds effectiveness given the flimsiness of the public evidence, and Peter’s general skeptical prior about cool sounding interventions described below. I think people really want there to be a good “EA approved” mental health charity and this means evaluations are frequently much less cautious and careful than they should be.
I think this is a good idea.
Thank you for taking the time to write this. This is (almost) exactly how I feel.
(I personally do not agree that FP can reasonably still have the view that they do about StrongMinds based on what they’ve said about their reasoning here, but I accept that I will have to wait until I’ve published my thoughts on the HLI analyses before I can expect people who haven’t looked at the HLI work to agree with me)
Hey Simon, I remain slightly confused about this element of the conversation. I take you to mean that, since we base our assessment mostly on HLI’s work, and since we draw different conclusions from HLI’s work than you think are reasonable, we should reassess StrongMinds on that basis. Is that right?
If so, I do look forward to your thoughts on the HLI analysis, but in the meantime I’d be curious to get a sense of your personal levels of confidence here — what does a distribution of your beliefs over cost-effectiveness for StrongMinds look like?
I’m not sure exactly what you’ve done, so it’s hard for me to comment precisely. I’m just struggling to see how you can be confident in a “6x as effective as GD” conclusion.
So there are two sides to this:
Is my confidence in HLI’s philisophical views. I have both spoken to Joel and read all their materials several times and thinkI understand their views. I am sure I do not fully agree with them and I’m not sure how much I believe them. I’d put myself at roughly 30% that I agree with their general philosophy. This is important because how cost-effective you believe StrongMinds are is quite sensitive to philisophical assumptions. (I plan on expanding upon this when discussing HLI)
Under HLI’s philosophical assumptions, I think I’m roughly speaking:
10% SM is 4-8x as good at GiveDirectly
25% SM is 1-4x as good as GiveDirectly
35% SM is 0.5-1x as good as GiveDirectly
30% SM not effective at all
So roughly speaking under HLI’s assumptions I think StrongMinds is roughly as good as GiveDirectly.
I think you will probably say on this basis that you’d still be recommending StrongMinds based on your risk-neutral principle but I think this underestimates quite how uncertain I would expect people to be in the HLI worldview. (I also disagree with being risk-neutral, but I suspect that’s a discussion for another day!)
I think another thing I’d add with StrongMinds is I think people are forgetting:
(1) generally cool-sounding charities usually don’t work out under more intense scrutiny (lets call this the generalized GiveWellian skeptical prior)
(2) StrongMinds really has not yet received GiveWell-style intense scrutiny
(3) there are additional reasons on priors to be skeptical of StrongMinds given that the effect sizes seem unusually large/cheap compared to the baseline of other mental health interventions (which admittedly are in developed world contexts which is why this is more of a prior than a knockdown argument).
~
Update: Alex Lawsen independently makes a similar argument to me on Twitter. See also Bruce expressing skepticism in the comments here.
Another reason is that Berk Özler had a scathing review of StrongMinds on Twitter (archived, tweets are now deleted).
I had not realized that he was running an RCT on StrongMinds (as mentioned in this post), so possibly had access to insider data on the (lack of) effectiveness.
Here’s the full exchange between Özler and Haushofer:
JH: Whenever someone meekly suggests that one might not leave those with the lowest incomes entirely alone with their mental health struggles, the “it’s not that simple” brigade shows up and talks about the therapy-industrial complex and it’s so tiresome.
BO: Thanks, Johannes. That thread & and recommendation is outrageous: there’s no good evidence that Strong Minds is effective, let alone most effective. It’s 20-year old studies combined with pre-post data provided by SM itself. People should pay no attention to this 🧵, whatsoever.
JH: This dismissal seems much too strong to me. I thought HLI’s discussion of the evidence here was fair and reasonable: https://www.happierlivesinstitute.org/report/strongminds-cost-effectiveness-analysis
BO: Show me one good published study of the impact of SM on the ground at some decent scale...
JH: My point is not that SM is the best available intervention. My point is that people who get upset at HLI for caring about wellbeing on the grounds that this ignores structural interventions are mistaken.
BO: I have zero problems with your point. It’s well taken & that’s why I thanked you for your tweet. My issue is w the unequivocal SM recommendation, the evidence presented, & the conviction with which it is advertised. People (unfortunately) donate based on such recommendations...
JH: Ok, one can disagree about that. Do you think the Bolton et al work is good? If yes what dissuades you from thinking that SM is effective? (Regardless of whether it should be top-ranked)
BO: Bolton et al. (2003) is not about SM. Why did you evaluate GD with an RCT when we could have extrapolated from Progresa?
JH: Of course there’s always room for more studies. But if someone had said at the time that GD is likely to be effective for certain outcomes based on work on Progresa, I wouldn’t have considered that claim outrageous. (Side point, I think IPT/SM more similar than Progresa/GD.)
JH: (Addendum: I’ve always been a bit uneasy with the hype around GD and our study in light of all the other evidence on cash transfers.)
BO: You would have if someone was claiming that it was exactly 6 times more effective per $ than the most promising alternative. Also, no one (give or take) would have donated to GD on the basis of previous evidence, say our study in Malawi...(which is much closer).
JH: GD definitely emphasized early on that cash transfers were very well-researched! Of course not sure if that helped, but I don’t recall any “how can you say that!” reactions. 1⁄2
JH: On the “6 times” claim: I think orgs like Givewell and HLI are in the business of providing guesstimates given limited and mixed-quality evidence. I have much more tolerance for extrapolation in that context than in an academic paper. 2⁄2
BO: I think smt got lost in translation here: my point is you can’t claim your NGO is best because it works on something promising. You have to show it—effectiveness at scale. That was true for GD and it remains true for SM. /1
BO: And you definitely should not make forest plots like that with guesstimates. It’s misleading.../FIN.
BO: I’m going to leave it at this. I don’t care for that type of hype right before the giving season, with shaky evidence. We all know the dangers of assuming effectiveness at scale from efficacy studies, especially 20-year-old ones...
JH: I definitely see that. I also think this shaky evidence is leagues better than what most people base their giving decisions on, so if someone listens, it’s a net improvement.
Just to clarify, Berk has deleted his entire Twitter profile rather than these specific tweets. Will be interesting to the results from the upcoming RCT.
I’m belatedly making an overall comment about this post.
I think this was a valuable contribution to the discussion around charity evaluation. We agree that StrongMinds’ figures about their effect on depression are overly optimistic. We erred by not pointing this out in our previous work and not pushing StrongMinds to cite more sensible figures. We have raised this issue with StrongMinds and asked them to clarify which claims are supported by causal evidence.
There are some other issues that Simon raises, like social desirability bias, that I think are potential concerns. The literature we reviewed in our StrongMinds CEA (page 26) doesn’t suggest it’s a large issue, but I only found one study that directly addresses this in a low-income country (Haushofer et al., 2020), so the evidence appears very limited here (but let me know if I’m wrong). I wouldn’t be surprised if more work changed my mind on the extent of this bias. However, I would be very surprised if this alone changed the conclusion of our analysis. As is typically the case, more research is needed.
Having said that, I have a few issues with the post and see it as more of a conversation starter than the end of the conversation. I respond to a series of quotes from the original post below.
If there’s confusion about our methodology, that’s fair, and I’ve tried to be helpful in that regard. Regarding our relationship with StrongMinds, we’re completely independent.
This is false. As we’ve explained before, our evaluation of StrongMinds is primarily based on a meta-analysis of psychological interventions in LMICs, which is a distinction between our work and Founders Pledge that means that many of the problems mentioned apply less to our work.
I also have some issues with the claims this post makes. I’ll focus on Simon’s summary of his argument:
Next, I remark on the problem with each line.
I think StrongMinds would disagree with this argument. This strikes me as overconfident.
If quantitative means “RCTs”, then sure, but until very recently, they surveyed the depression score before and after treatment for every participant (which in 2019 meant an n = 28,294, unpublished data shared with me during their evaluation). StrongMinds also followed up 18 months after their initial trial and in 2019 they followed up with 300 participants six months after they received treatment (again, unpublished data). I take that as at least a sign they’re trying to quantitatively evaluate their impact – even if they could do much better (which I agree they could).
I’m a bit confused by this point. It sounds more like the appropriate claim is, “they didn’t do the research they once claimed they would do fast enough.” As Simon pointed out, there’s an RCT whose results should be released soon by Baird et al. From conversations we’ve had with StrongMinds, they’re also planning on starting another RCT in 2023. I also know that they completed a controlled trial in 2020 (maybe randomised, still unsure) with a six-month and year follow-up. However, I agree that StrongMinds could and should invest in collecting more causal data. I just don’t think the situation is as bleak as it has been made out to be, as running an RCT can be an enormous undertaking.
This either means (a) only Founders Pledge has evaluated StrongMinds, which is wrong, or (b) HLI doesn’t count because we are not independent, which would be both wrong and uncharitable.
I think this could have a pretty simple explanation. StrongMinds used a linear model to estimate: depression reduction = group + sessions. This will lead to a non-zero intercept if the relationship between sessions and depression reduction is non-linear, which we see in the graphs provided in the post.
Thanks for writing this Simon. I’m always pleased to see people scrutinising StrongMinds because it helps us all to build a better understanding of the most cost-effective ways to address the huge (and severely neglected) burden of disease from mental health conditions.
HLI’s researchers are currently enjoying some well-deserved holiday but they’ll be back next week and will respond in more detail then. In the meantime, I want to recommend the following resources (and discussion) for people reading this post:
HLI’s 2022 charity recommendation
HLI’s cost-effectiveness analysis of StrongMinds
AMA with Sean Mayberry (Founder & CEO of StrongMinds)
I also want to clarify two things related to the quote above:
HLI’s relationship with StrongMinds is no different to GiveWell’s relationship with the charities they recommend. We are separate organisations and HLI’s evaluation of StrongMinds is entirely independent.
HLI’s methodology follows a meta-analytic approach. We don’t take the results from StrongMinds’ own trials at face value. We explain this further here.
From an outside view, I see Happier Lives Institute as an advocacy organisation for mental health interventions, although I can imagine HLI see themselves as a research organisation working on communicating the effectiveness of mental health interventions. Ultimately, I am not sure there’s a lot distinguishing these roles.
Givewell however, is primarily a research and donor advisory organisation. Unlike HLI, it does not favour a particular intervention, or pioneer new metrics in support of said interventions.
Some things that HLI does that makes me think HLI is an advocacy org:
Recommend only 1 charity (StrongMinds)
Appear publicly on podcasts ect., and recommend StrongMinds
Write to Effective Giving platforms, requesting they add Strong Minds to their list of recommended organisations
Edit: Fixed acronym in first paragraph
I agree with all of these reasons. My other reasons for being unclear as to the relationship is the (to my eye) cynical timing and aggressive comparisons published annually during peak giving season.
StrongMinds vs Worms (Dec 22)
StrongMinds vs Betnets (Nov 22)
StrongMinds vs Cash transfers 2 (Nov 21)
StrongMinds vs Cash transfers (Oct 21)
Last year when this happened I thought it was a coincidence, twice is enemy action.
(Edit: I didn’t mean to imply that HLI is an “enemy” in some sense, it’s just a turn-of-phrase)
Simon,
It’s helpful to know why you thought the relationship was unclear.
But I don’t think us (HLI) publishing research during the giving season is “cynical timing” any more than you publishing this piece when many people from GWWC, FP, and HLI are on vacation is “cynical timing”.
When you’re an organization without guaranteed funding, it seems strategic to try to make yourself salient to people when they reach for their pocketbooks. I don’t see that as cynical.
FWIW, the explanation is rather mundane: the giving season acts as hard deadline which pushes us to finish our reports.
To add to this, even if it were timed, I don’t think that timing the publication outputs to coincide with peak giving season will necessarily differentiate between a funding-constrained research organisation and a funding-constrained advocacy organisation, if both groups think that peak giving season will lead to more donations that are instrumentally useful for their goals.
I think the reason I’m publishing it now is because it’s when I’m on vacation! (But yes, that’s a fair point).
I think the timing makes sense for HLI, but given how adverserial the articles come across (to me) it seems like they are trying to shift funding away from [generic top charity] to StrongMinds, which is why it seems to me it’s more about StrongMinds than HLI. I expect HLI could get just as much salence publishing about bednets on their own at that time than adding the comparison to StrongMinds. (Not sure about this though, but it does seem like the strategy seems to involve generating lots of heat rather than light)
Yes, that does make sense (and probably is about as mundane as my reason for publishing whilst GWWC, FP and HLI are on vacation)
To be clear, that’s what I meant to imply—I assumed you published this when you had time, not because the guards were asleep.
Everything is compared to StrongMinds because that’s what our models currently say is best. When (and I expect it’s only a matter of when) something else takes StrongMinds’ place, we will compare the charities we review to that one. The point is to frame the charities we review in terms of how they compare to our current best bet. I guess this is an alternative to putting everything in terms of GiveDirectly cash transfers—which IMO would generate less heat and light.
GW compares everything to GiveDirectly (which isn’t considered their best charity). I like that approach because:
Giving people cash is really easy to understand
It’s high capacity
It’s not a moving target (unlike say worms or betnets which changes all the time based on how the charities are executing)
I think for HLI (at their current stage) everthing is going to be a moving target (because there’s so much uncertainty about the WELLBY effect of every action) but I’d rather have only one moving target rather than two.
FWIW, I’m not unsympathetic to comparing everything to GiveDirectly CTs, and this is probably something we will (continue to) discuss internally at HLI.
I’m seeing a lot of accusations flying around in this thread (e.g. cynical, aggressive, enemy action, secret info etc.). This doesn’t strike me as a ‘scout mindset’ and I was glad to see Bruce’s comment that “it’s important to recognise that everyone here does share the same overarching goal of “how do we do good better”.
HLI has always been transparent about our goals and future plans. The front page of our website seems clear to me:
Our research agenda is also very clear about our priorities:
And our 2022 charity recommendation post makes it clear that we plan to investigate a wider range of interventions and charities in 2023:
My role as Communications Manager is to communicate the findings from our research to decision-makers to help them allocate their resources more effectively. There’s nothing suspicious about doing that in Giving Season. That’s what all the charity evaluators do.
We only recommend one charity because StrongMinds is the most cost-effective charity we’ve identified (so far) and they have a $20m funding gap which is very unlikely to be filled in this giving season. GiveWell has a lot more money to allocate so they have to find multiple charities with room for more funding. I hope that HLI will face (and solve) that problem in the future too!
In my personal opinion, GiveWell has been hugely successful and inspirational but it’s clear that their methodology cannot handle interventions that have benefits beyond health and wealth. That’s why HLI is bringing the WELLBY methodology from the academic and policy world into the global health field. It’s the same reason that Open Philanthropy ran an essay prize to find suggestions for measuring non-health, non-pecuniary benefits. Our entry to that competition set out the pros AND the cons of the WELLBY approach as well as our plans for further foundational research on subjective wellbeing measures.
There’s a lot more I could say, but this comment is already getting too long. The key thing I want to get across is that if you (the reader) are confused about HLI’s mission, strategy, or research findings, then please talk to us. I’m always happy to talk to people about HLI’s work on a call or via email.
This is helpful to know how we come across. Id encourage people to disagree or agree with Elliots comment as a straw poll on how readers perceptions of HLI accord with that characterization.
p.s. I think you meant to write “HLI” instead of “FHI”.
I agreed with Elliott’s comment, but for a somewhat different reason that I thought might be worth sharing. The “Don’t just give well, give WELLBYs” post gave me a clear feeling that HLI was trying to position itself as the Happiness/Well-Being GiveWell, including by promoting StrongMinds as more effective than programs run by classic GW top charities. A skim of HLI’s website gives me the same impression, although somewhat less strongly than that post.
The problem as I see it is that when you set GiveWell up as your comparison point, people are likely to expect a GiveWell-type balance in your presentation (and I think that expectation is generally reasonable). For instance, when GiveWell had deworming programs as a top charity option, it was pretty clear to me within a few minutes of reading their material that the evidence base for this intervention had some issues and its top-charity status was based on a huge potential upside-for-cost. When GiveWell had standout charities, it was very clear that the depth of research and investigation behind those programs was roughly an order of magnitude or so less than for the top charities. Although I didn’t read everything on HLI’s website, I did not walk away with the impression that the methodological weaknesses discussed in this and other threads were disclosed and discussed very much (or nearly as much as I would expect GiveWell to have done in analogous circumstances).
The fact that HLI seems to be consciously positioning itself as in the GiveWellian tradition yet lacks this balance in its presentations is, I think, what gives off the “advocacy organisation” vibes to me. (Of course, its not reasonable for anyone to expect HLI to have done the level of vetting that GiveWell has done for its top charities—so I don’t mean to suggest the lesser degree of vetting at this point is the issue.)
“Happiness/Wellbeing GiveWell” is a fair description of HLI in my opinion. However, I want to push back on your claim that GiveWell is more open and balanced.
As far as I can tell, there is nothing new in Simon’s post or subsequent comments that we haven’t already discussed in our psychotherapy and StrongMinds cost-effectiveness analyses. I’m looking forward to reading his future blog post on our analysis and I’m glad it’s being subjected to external scrutiny.
Whereas, GiveWell acknowledge they need to improve their reasoning transparency:
That’s just my opinion though and I don’t want to get into a debate about it here. Instead, I think we should all wait for GWWC to complete their independent evaluation of evaluators before drawing any strong conclusions about the relative strengths and weaknesses of the GiveWell and HLI methodologies.
To clarify, the bar I am suggesting here is something like: “After engaging with the recommender’s donor-facing materials about the recommended charity for 7-10 minutes, most potential donors should have a solid understanding of the quality of evidence and degree of uncertainty behind the recommendation; this will often include at least a brief mention of any major technical issues that might significantly alter the decision of a significant number of donors.”
Information in a CEA does not affect my evaluation of this bar very much. For qualify in my mind as “primarily a research and donor advisory organisation” (to use Elliot’s terminology), the organization should be communicating balanced information about evidence quality and degree of uncertainty fairly early in the donor-communication process. It’s not enough that the underlying information can be found somewhere in 77 pages of the CEAs you linked.
To analogize, if I were looking for information about a prescription drug, and visited a website I thought was patient-advisory rather than advocacy, I would expect to see a fair discussion of major risks and downsides within the first ten minutes of patient-friendly material rather than being only in the prescribing information (which, like the CEA, is a technical document).
I recognize that meeting the bar I suggested above will require HLI to communicate more doubt about that GiveWell needs to communicate about its four currently recommended charities; that is an unavoidable effect of the fact that GiveWell has had many years and millions of dollars to target the major sources of doubt on those interventions as applied to their effectiveness metrics, and HLI has not.
I want to close by affirming that HLI is asking important questions, and that there is real value in not being too tied to a single evaluator or evaluation methodology. That’s why I (and I assume others) took the time to write what I think is actionable feedback on how HLI can better present itself as a donor-advisory organization and send off fewer “advocacy group” vibes. So none of this is intended as a broad criticism of HLI’s existence. Rather, it is specifically about my perception that HLI is not adequately communicating information about evidence quality and degree of uncertainty in medium-form communications to donors.
I read this comment as implying that HLI’s reasoning transparency is currently better than Givewell’s, and think that this is both:
False.
Not the sort of thing it is reasonable to bring up before immediately hiding behind “that’s just my opinion and I don’t want to get into a debate about it here”.
I therefore downvoted, as well as disagree voting. I don’t think downvotes always need comments, but this one seemed worth explaining as the comment contains several statements people might reasonably disagree with.
Thanks for explaining your reasoning for the downvote.
I don’t expect everyone to agree with my comment but if you think it is false then you should explain why you think that. I value all feedback on how HLI can improve our reasoning transparency.
However, like I said, I’m going to wait for GWWC’s evaluation before expressing any further personal opinions on this matter.
TL;DR
I think an outsider may reasonably get the impression that HLI thinks its value is correlated with their ability to showcase the effectiveness of mental health charities, or of WELLBYs as an alternate metric to cause prioritisation. It might also be the case that HLI believes this, based on their published approach, which seems to assume that 1) happiness is what ultimately matters and 2) subjective wellbeing scores are the best way of measuring this. But I don’t personally think this is the case—I think the main value of an organisation like HLI is to help the GH research community work out the extent to which SWB scores are valuable in cause prioritisation, and how we best integrate these with existing measures (or indeed, replace them if appropriate). In a world where HLI works out that WELLBYs actually aren’t the best way of measuring SWB, or that actually we should weigh DALYs to SWB at a 1:5 ratio or a 4:1 ratio instead of replacing existing measures wholesale or disregarding them entirely, I’d still see these research conclusions as highly valuable (even if the money shifted metric might not be similarly high). And I think these should be possibilities that HLI remain open to in its research and considers in its theory of change going forward—though this is based mainly from a truth-seeking / epistemics perspective, and not because I have a deep knowledge of the SWB / happiness literature to have a well-formed view on this (though my sense is that it’s also not a settled question). I’m not suggesting that HLI is not already considering this or doing this, just that from reading the HLI website / published comments, it’s hard to clearly tell that this is the case (and I haven’t looked through the entire website, so I may have missed it).
======
Longer:
I think some things that may support Elliot’s views here:
HLI was founded with the mission of finding something better than GiveWell top charities under a subjective wellbeing (SWB) method. That means it’s beneficial for HLI in terms of achieving its phase 1 goal and mission that StrongMinds is highly effective. GiveWell doesn’t have this pressure of finding something better than it’s current best charities (or not to the same degree).
HLI’s investigation of various mental health programmes lead to its strong endorsement for StrongMinds. This was in part based on StrongMinds being the only organisation on HLI’s shortlist (of 13 orgs) to respond and engage with HLI’s request for information. Two potential scenarios for this:
HLI’s hypothesis that mental health charities are systematically undervalued is right, and thus, it’s not necessarily that StrongMinds is uniquely good (acknowledged by HLI here), but the very best mental health charities are all better than non-mental health charities under WELLBYs measurements, which is HLI’s preferred approach RE: “how to do the most good”. However this might bump up against priors or base rates or views around how good mental health charities on HLI’s shortlist might be vs existing GiveWell charities are as comparisons, whether all of global health prioritisation, aid or EA aid has been getting things wrong and we are in need of a paradigm shift, as well as whether WELLBYs and SWB scores alone should be a sufficient metric for “doing the most good”.
Mental health charities are not systematically undervalued, and current aid / EA global health work isn’t in need of a huge paradigm shift, but StrongMinds is uniquely good, and HLI were fortunate that the one that responded happened to be the one that responded. However, if an outsider’s priors on the effectiveness of good mental health interventions generally are much lower than HLI’s, it might seem like this result is very fortuitous for HLI’s mission and goals. On the other hand, there are some reasons to think they might be at least somewhat correlated:
well-run organisations are more likely to have capacity to respond to outside requests for information
organisations with good numbers are more likely to share their numbers etc
HLI have never published any conclusions that are net harmful for WELLBYs or mental health interventions. Depending on how much an outsider thinks GiveWell is wrong here, they might expect GiveWell to be wrong in different directions, and not only in one direction. Some pushback: HLI is young, and would reasonably focus on organisations that is most likely to be successful and most likely to change GiveWell funding priorities. These results are also what you’d expect if GiveWell IS in fact wrong on how charities should be measured.
I think ultimately the combination could contribute to an outsider’s uncertainty around whether they can take HLI’s conclusions at face value, or whether they believe these are the result of an unbiased search optimising for truth-seeking, e.g. if they don’t know who HLI researchers are or don’t have any reason to trust them beyond what they see from HLI’s outputs.
Some important disclaimers:
-All of these discussions are made possible because of HLI (and SM)’s transparency, which should be acknowledged.
-It seems much harder to defend against claims that paints HLI as an “advocacy org” or suggests motivated reasoning etc than to make the claim. It’s also the case that these findings are consistent with what we would expect if the claims 1) “WELLBYs or subjective wellbeing score alone is the best metric for ‘doing the most good’” and 2) “Existing metrics systematically undervalue mental health charities” are true, and HLI is taking a dispassionate, unbiased view towards this. All I’m saying is that an outsider might prefer to not default to believing this.
-It’s hard to be in a position to be challenging the status quo, in a community where reputation is important, and the status quo is highly trusted. Ultimately, I think this kind of work is worth doing, and I’m happy to see this level of engagement and hope it continues in the future.
-Lastly, I don’t want this message (or any of my other messages) to be interpreted to be an attack on HLI itself. For example, I found HLI’s Deworming and decay: replicating GiveWell’s cost-effectiveness analysis to be very helpful and valuable. I personally am excited about more work on subjective wellbeing measures generally (though I’m less certain if I’d personally subscribe to HLI’s founding beliefs), and I think this is a valuable niche in the EA research ecosystem. I also think it’s easy for these conversations to accidentally become too adversarial, and it’s important to recognise that everyone here does share the same overarching goal of “how do we do good better”.
(commenting in personal capacity etc)
I like that idea!
Edited, thanks
Thanks—I had looked at the HLI research and I do have a bunch of issues with the analysis (both presentation and research). My biggest issue at the moment is I can’t join up the dots between:
“a universal metric called wellbeing-adjusted life years (WELLBYs). One WELLBY is equivalent to a 1-point increase on a 0-10 life satisfaction scale for one year” (here)
“First, we define a ΔWELLBY to denote a one SD change in wellbeing lasting for one year” (Appendix D here)
In all the HLI research, everything seems to be calculated in the latter terms, which isn’t something meaningful at all (to the best of my understanding). The standard deviations you are using aren’t some global “variance in subjective well-being” but a the sample variance of subjective well-being which going to be materially lower. It’s also not clear to me that this is even a meaningful quantity. Especially when your metric for subjective well-being is a mental health survey in which a mentally healthy person in San Franscisco would answer the same as a mentally healthy person in the most acute poverty.
Hi Simon, I’m one of the authors of HLI’s cost-effectiveness analysis of psychotherapy and StrongMinds. I’ll be able to engage more when I return from vacation next week.
I see why there could be some confusion there. Regarding the two specifications of WELLBYs, the latter was unique to that appendix, and we consider the first specification to be conventional. In an attempt to avoid this confusion, we denoted all the effects as changes in ‘SDs’ or ‘SD-years’ of subjective wellbeing / affective mental health in all the reports (1,2,3,4,5) that were direct results in the intervention comparison.
Regarding whether these changes are “meaningful at all”, -- it’s unclear what you mean. Which of the following are you concerned with?
That standard deviation differences (I.e., Cohen’s d or Hedges g effect sizes) are reasonable ways to do meta-analyses?
Or is your concern more that even if SDs are reasonable for meta-analyses, they aren’t appropriate for comparing the effectiveness of interventions? We flag some possible concerns in Section 7 of the psychotherapy report. But we haven’t found sufficient evidence after several shallow dives to change our minds.
Or, you may be concerned that similar changes in subjective wellbeing and affective mental health don’t represent similar changes in wellbeing? (We discuss this in Appendix A of the psychotherapy report).
Or is it something else I haven’t articulated?
Most of these issues are technical, and we recognise that our views could change with further work. However, we aren’t convinced there’s a ready-to-use method that is a better alternative for use with subjective wellbeing analyses.
I also welcome further explanation of your issues with our analysis, public or private. If you’d like to have low stakes chat about our work, you can schedule a time here. If that doesn’t work, email or message me, and we can make something work.
This is exactly what confused me. In all the analytical pieces (and places linked to in the reports defining WELLBY on the 0-10 scale) you use SD but then there’s a chart which uses WELLBY and I couldn’t find where you convert from one to another.
I think this is a very reasonable way to do meta-analyses
Yes. This is exactly my confusion, specifically:
In the absence of evidence my prior is very strong that a group of people selected to have a certain level of depression is going to have a lower SD than a group of randomly sampled people. This is exactly my confusion. Furthermore, I would expect the SD of “generally healthy people” to be quite low and interventions to have low impact. For example, giving a health person an PS5 for Christmas might massively boost their subjective well-being, but probably doen’t do much for mental health. (This is related to your third point, but is more about the magnitude of changes I’d expect to see rather than anything else)
So I also have issues with this, although it’s not the specific issue I’m raising here.
Nope—it’s pretty much exactly point 2.
Well, my contention is subjective wellbeing analyses shouldn’t be the sole basis for evaluation (but again, that’s probably a separate point).
Thanks! I’ve (hopefully) signed up to speak to you tomorrow
Thanks for writing this. I have to admit to confirmation bias here, but SM’s effects are so stupidly large that I just don’t believe they are possible. I hadn’t seen the control group also having a sharp decline but that raises even more alarm bells.
This is also very important for organizations trying to follow SM’s footsteps, like the recently incubated Vida Plena.
I anticipate that SM could enter a similar space as deworming now, where the evidence is shaky but the potential impacts are so high and the cost of delivery so low that it might be recommended/worth doing anyway.
Thanks for this Simon! I have an additional concern which it would be interesting to get other people’s views on: While I’m sympathetic to the importance of subjective well-being, I have additional concerns about how spillovers are sometimes incorporated into the cost-effectiveness comparisons between Strongminds and Givewell (like in this comparison with deworming). Specifically, I can see plausible cases where Givewell-type improvements in health/income allow an individual to make choices that sacrifice some of their own subjective well-being, in service of their family/relatives. These could include:
Migrating to a city or urban area for job opportunities. For the migrant, the move may lead to more social isolation and loss of community. But those receiving remittances could benefit substantially.
Choosing to work in manufacturing rather than e.g. subsistence agriculture, and so having a better security net (for oneself and ones’ family) but sacrificing day-to-day autonomy.
Similarly, choosing a long commute for a better opportunity
Any long-term investments in e.g. children’s education, specifically if these investments are ‘lumpy’ (the sacrifice is only possible once income exceeds a certain threshold)
While some CEAs are making adjustments for spillovers, and HLI have made a considerable effort to measure spillovers (e.g. in this post), they seem to rely on limited studies and those studies don’t seem (based on my quick reading) to measure longer term effects (e.g. >4 years), while longer-term is when some sacrifices may start to pay-off for some household members. I hope in the future intelligent study designs will start to consider subjective well-being spillovers more deliberately, but for now I’m concerned that the cost-effectiveness of Givewell-type interventions could be underestimated if models are using the available subjective well-being data (which to my knowledge usually focuses on the main recipient).
Note: I haven’t reviewed the literature in-depth so I may have missed resources that help resolve these issues.
I’m also pretty skeptical about the astronomical success rate SM professes, particularly because of some pretty serious methodology issues. Very significant confounding factors due to the recruitment method is, I think, the most important (recruitment from microfinance and employment training programs, to me, means that their sample would be predisposed to having improvements in depression symptoms because of improvement or even the possibility of improvement in material conditions), but the lackluster follow through with control groups and long-term assessment are also significant. I would love for them to have a qualitative study with participants to understand the mechanisms of improvement and what the participants feel has been significant in alleviating their depressive symptoms.
That being said, I think it’s worth mentioning that SM is not the first to try this method of treatment, and that there are a considerable amount of studies that have similar results (their methods also leave something to be desired, in my opinion, but not so much so that I think they should be disregarded). Meta-analyses for IPT have found that IPT is effective in treating depression and noteworthy as an empirically tested treatment [1]. The original Bolton et al. study that I believe SM takes as a model for its intervention and six-month follow up study claims that benefits have held for that long. Another study in Uganda that Bolton and some other members of initial research team conducted 10 years later gives some more insight in how it actually works through a qualitative study (to be clear, though, this is not a follow up with the participants from the initial papers). There are more than a dozen other studies implementing GIPT in a variety of different context and for different target groups, and they all point to high decreases in symptoms of depression, although they all suffer from confounding factors and either lack of long-term follow ups or lack of meaningfully tracked control groups.
This is not to say that SM’s estimates are probably correct, or that they for sure deserve their spot as top rated charity—I do think that they’re doing valuable work overall, and I have some confidence that providing this type of intervention that is somewhat self-sustaining with its focus on treating symptoms of depression by focusing on managing them and creating in-community support groups that are able to continue after the initial intervention is probably cost-effective for mental health treatment, and moreso in underserved communities, but I remain doubtful about the size and means of impact until I see some more evidence backing it up. That being said, I was surprised to see that SM’s purported results weren’t as out of left field as I initially assumed, so I wanted to share this for context.
Two of these studies (1, 2) are for IPT and not GIPT, and are notably conducted by a group led by the same person; the third focuses on postpartum depression specifically.
I am not doubting that IPT-G is an effective method for treating depression. (I hope that came across in my article). I am doubting the data (and by extension the effect size) which they are seeing vs other methods.
They are somewhere between 1.4-3.7x higher than the meta-analyses from HLI where I would expect them to be lower than the meta-analysis effects. (It’s not clear to me that Cohen’s-d is the right metric here, which I want to say more about in future posts). tl;dr Cohen’s-d is more about saying “there is an effect” than how big the effect is.
Could you clarify your comment about Cohen’s d? In my experience with experimental work, p-values are used to establish the ‘existence’ of an effect. But (low/>0.05) p-values do not inherently mean an effect size is meaningful. Cohen’s d are meant to gauge effect sizes and meaningfulness (usually in relation to Cohen’s heuristics of 0.2, 0.5, and 0.8 for small, medium, and large effect sizes). However, Cohen argued it was lit and context dependent. Sometimes tiny effects are meaningful. The best example I can think of are the Milkman et al megastudy on text-based vaccine nudges.
Does this comment answer your question or not?
I wasn’t taking issue with your skepticism of SM. I was just confused about your comments about Cohen’d given they are not typically used to demonstrate the existence of an effect. I’m just curious about your reasons as to why it might not be an ideal metric !
Yes - it was a fair question and what I wrote was phrased badly. I was just wondering if my explanation there was sufficient? (Basically my issue is that Cohen’s d only gives you information in SD terms, and it’s not easy to say whether or not SDs are a useful in this context or not)
Like with you and many other commenters here, I also find the large effect sizes quite puzzling. It definitely gives me “Hilgard’s Lament” vibes—“there’s no way to contest ridiculous data because ‘the data are ridiculous’ is not an empirical argument”. On the usefulness of Cohen’s d/SD, I’m not sure. I guess it has little to no meaning if there seems to be issues surrounding the reliability and validity of the data. Bruce linked to their recruitment guidelines and it doesn’t look very good.
Edit: Grammar and typos.
I agree—that’s essentially the thing I want to resolve. I have basically thrown out a bunch of potential reasons:
The data is dubious
The data isn’t dubious, but isn’t saying what we think it’s saying—for example, it might be easy to move 1-SD of [unclear metric] might notbe that surprising depending on what [unclear metric] is.
The data isn’t dubious and StrongMinds really is a great charity
For option 3 to be compelling we certainly need a whole lot more than what’s been given. Many EA charities have a lot of RCT/qual work buttressing them while this doesn’t. It seems fundamentally strange then that EA orgs are pitching SM as the next greatest thing without the strong evidence that we expect from EA causes.
I strongly agree—hence my title
Oh no, I wasn’t trying to imply that that’s what you were doing. I wanted to comment on it because I was extremely doubtful that any kind of intervention could have very high impact (not even as high as SM claims, even something around 70-75% would have been surprising to me) when I first came across it and considered it very implausible until seeing the evidence base for GIPT, which made me think it’s not quite so outlandish as to be totally implausible (although, as I said, I still have my doubts and don’t think SM makes a strong enough case for their figures). Just wanted to share this for anyone else who was in my position.
If SM’s intervention is as effective as it reports, then presumably that effect would be demonstrated not only on the PHQ-9 but also on more “objective” measures like double-blinded observer ratings of psychomotor agitation/retardation between treatment and control groups. Although psychomotor effects are only a fairly small part of the disease burden of depression, their improvement or non-improvement vs. controls would update my assessment of the methodological concerns expressed in this post. Same would be true of tests of concentration, etc.
I agree that would be a big improvement. I guess the only metrics in the big RCT is their “competency tests” but I don’t think that’s sufficient and I doubt we are going to see anything along those lines soon.
100% agree, at least some objectve measure could be added—wouldn’t cost mch extra
SoGive is working on a review of StrongMinds. Our motivations for working on this included the expectation that the community might benefit from having more in-depth, independent scrutiny on the StrongMinds recommendation—an expectation which appears to be validated by this post.
I’m sorry we’re not in a position to provide substantive comment at this stage—this is partly because the main staff member working on this is on holiday right now, and also because our work is not finished yet.
We will likely publish more updates within the next 2-3 months.
For anyone who wants to bet on what action will happen here, this market has $90 of liquidity. which is a lot by manifold standards. If you think the market is wrong, correct it and make mana that you can give to charity!
As promised, I am returning here with some more detail. I will break this (very long) comment into sections for the sake of clarity.
My overview of this discussion
It seems clear to me that what is going on here is that there are conflicting interpretations of the evidence on StrongMinds’ effectiveness. In particular, the key question here is what our estimate of the effect size of SM’s programs should be. There are other uncertainties and disagreements, but in my view, this is the essential crux of the conversation. I will give my own (personal) interpretation below, but I cannot stress enough that the vast majority of the relevant evidence is public—compiled very nicely in HLI’s report—and that neither FP’s nor GWWC’s recommendation hinges on “secret” information. As I indicate below, there are some materials that can’t be made public, but they are simply not critical elements of the evaluation, just quotes from private communications and things of that nature.
We are all looking at more or less the same evidence and coming to different conclusions.
I also think there is an important subtext to this conversation, which is the idea that both GWWC and FP should not recommend things for which we can’t achieve bednet-level levels of confidence. We simply don’t agree, and accordingly this is not FP’s approach to charity evaluation. As I indicated in my original comment, we are risk-neutral and evaluate charities on the basis of expected cost-effectiveness. I think GiveWell is about as good as an organization can be at doing what GiveWell does, and for donors who prioritize their giving conditional on high levels of confidence, I will always recommend GiveWell top charities over others, irrespective of expected value calculations. It bears repeating that even with this orientation, we still think GiveWell charities are around twice as cost-effective as StrongMinds. I think Founders Pledge is in a substantially different position, and from the standpoint of doing the most possible good in the world, I am confident that risk-neutrality is the right position for us.
We will provide our recommendations, along with any shareable information we have to support them, to anyone who asks. I am not sure what the right way for GWWC to present them is.
How this conversation will and won’t affect FP’s position
What we won’t do is take immediate steps (like, this week) to modify our recommendation or our cost-effectiveness analysis of StrongMinds. My approach to managing FP’s research is to try to thoughtfully build processes that maximize the good we do over the long term. This is not a procedure fetish; this is a commonsensical way to ensure that we prioritize our time well and allocate important questions the resources and systematic thought they deserve.
What we will do is incorporate some important takeaways from this conversation during StrongMinds’ next re-evaluation, which will likely happen in the coming months. To my eye, the most important takeaway is that our rating of StrongMinds may not sufficiently account for uncertainty around effect size. Incorporating this uncertainty would deflate SM’s rating and may bring it much closer to our bar of 1x GiveDirectly.
More generally, I do agree with the meta-point that our evaluations should be public. We are slowly but surely moving in this direction over time, though resource constraints make it a slow process.
FP’s materials on StrongMinds
A copy of our CEA. I’m afraid this may not be very elucidating, as essentially all we did here is take HLI’s estimates and put them into a format that works better with our ratings system. One note is that we don’t apply any subjective discounts in this CEA—this is the kind of thing I expect might change in future.
Some exploration I did in R and Stan to try to test various components of the analysis. In particular, this contains several attempts to use SM’s pre-post data (corrected for a hypothesized counterfactual) to update on several different more general priors. Of particular interest are this review from which I took a prior on psychosocial interventions in LMICs and this one which offers a much more outside view-y prior.
Crucially, I really don’t think this type of explicit Bayesian update is the right way to estimate effects here; I much prefer HLI’s way of estimating effects (it leaves a lot less data on the table).
The main goal of this admittedly informal analysis was to test under what alternate analytic conditions our estimate of SM’s effectiveness would fall below our recommendation bar.
We have an internal evaluation template that I have not shared, since it contains quotes from private communications with StrongMinds. There’s nothing mysterious or particularly informative here; we just don’t share details of private communications that weren’t conducted with the explicit expectation that they’d be shared. This is the type of template that in future we hope to post publicly with privileged communications excised.
How I view the evidence about StrongMinds
Our task as charity evaluators is, to the extent possible, to quantify the important considerations in estimating a charity’s impact. When I reviewed HLI’s work on StrongMinds, I was very satisfied that they had accounted for many different sources of uncertainty. I am still pretty satisfied, though I am now somewhat more uncertain myself.
A running theme in critiques of StrongMinds is that the effects they report are unbelievably large. I agree that they are very large. I don’t agree that the existence of large-seeming effects is itself a knockdown argument against recommending this charity. It is, rather, a piece of evidence that we should consider alongside many other pieces of evidence.
I want to oversimplify a bit by distinguishing between two different views of how SM could end up reporting very large effect sizes.
The reported effects are essentially made-up. The intervention has no effect at all, and the illusion of an effect is driven by fraud at worst and severe confirmation bias at best.
The reported effects are severely inflated by selection bias, social desirability bias, and other similar factors.
I am very satisfied that (1) is not the case here. There are two reasons for this. First, the intervention is well-supported by a fair amount of external evidence. This program is not “out of nowhere”; there are good reasons to believe it has some (possibly small) effect. Second, though StrongMinds’ recent data collection practices have been wanting, they have shown a willingness to be evaluated (the existence of the Ozler RCT is a key data point here). With FP, StrongMinds were extremely responsive to questions and forthcoming and transparent with their answers.
Now, I think (2) is very likely to be the case. At FP, we increasingly try to account for this uncertainty in our CEAs. As you’ll note in the link above, we didn’t do that in our last review of StrongMinds, yielding a rating of roughly 5-6xGiveDirectly (per our moral weights, we value a WELLBY at about $160). So the question here is how much of the observed effect is due to bias? If it’s 80%, we should deflate our rating to 1.2x at StrongMinds’ net review. In this scenario it would still clear our bar (though only just).
In the absence of prior evidence about IPT-g, I think we might likely conclude that the observed effects are overwhelmingly due to bias. But I don’t think this is a Pascal’s Mugging-type scenario. We are not seeing a very large, possibly dubious effect that remains large in expectation even after deflating for dubiousness. We are seeing a large effect that is very broadly in line with the kind of effect we should expect on priors.
What I expect for the future
In my internal forecast attached to our last evaluation, I gave an 80% probability to us finding that SM would have an effectiveness of between 5.5x and 7x GD at its next evaluation. I would lower this significantly, to something like 40%, and overall I would say that I think there’s a 70-80% chance we’ll still be recommending SM after its next re-evaluation.
During the re-evaluation, it would be great if FP could also check the partnership programme by StrongMinds—e.g. whether this is an additional source of revenue for them, and what the operational costs of the partners who help treat additional patients for them are. At the moment these costs are not incorporated into HLI’s CEA, but partners were responsible for ~50 and ~80% of the clients treated in 2021 and 2022 respectively. For example, if we crudely assume costs of treatment per client are constant regardless of whether it’s treated by StrongMinds or by a StrongMinds partner, then:
Starting with 5x GiveDirectly, and using 2021 figures, if >~60% of the observed effect is due to bias it will be <1x GiveDirectly.
Starting with 5x GiveDirectly, and using 2022 figures, if >~0% of the observed effect is due to bias, it will be at <1x GiveDirectly.
(Thanks again for all your work, looking forward to the re-evaluation!)
Thanks, bruce — this is a great point. I’m not sure if we would account for the costs in the exact way I think you have done here, but we will definitely include this consideration in our calculation.
Out of interest what do your probabilities correspond to in terms of the outcome from the Ozler RCT? (Or is your uncertainty more in terms of what you might find when re-evaluating the entire framwork?)
I haven’t thought extensively about what kind of effect size I’d expect, but I think I’m roughly 65-70% confident that the RCT will return evidence of a detectable effect.
But my uncertainty is more in terms of rating upon re-evaluating the whole thing. Since I reviewed SM last year, we’ve started to be a lot more punctilious about incorporating various discounts and forecasts into CEAs. So on the one hand I’d naturally expect us to apply more of those discounts on reviewing this case, but on the other hand my original reason for not discounting HLI’s effect size estimates was my sense that their meta-analytic weightings appropriately accounted for a lot of the concerns that we’d discount for. This generates uncertainty that I expect we can resolve once we dig in.
This post has made me realize that it’s pretty hard to quickly find information about recommended charities that includes the number of interventions assessed, the sample size, and a note on the evidence quality, something like this comes from a RCT that was carried out well or this was pre- post- data with no randomization. I’d expect this in a summary or overview type presentation but I’m not sure how valuable this would be for everyone. At least for me personally it is, and it’s something that I would use to be more tentative to give or would give less where evidence is limited.
Thanks so much for this
Like I’ve said before, I really like strong minds, but we need an adequately powered RCT vs. cash. This should be a priority, not just a down-the-line thing to do. That their current RCT doesn’t have a purely cash arm is borderline negligence- I could barely believe it when I read the protocol. I wonder how the Strongminds team justified this, especially when the study involves cash anyway.
And the cash transfer should be about as much as the therapy costs (100-150 dollars)
An RCT with both HLI approved subjective wellbeing measures and a couple of other traditional measures would surely answer this question to the level that we would have a very good indication on just how highly to rate strongminds.
[This is a more well-thought-out version of the argument I made on Twitter yesterday.]
I think the Phase II numbers were not meant to be interpreted quite that way. For context, this is line chart of scores over time for Phase I, and this is the corresponding chart for Phase II. We can see that in the Phase II chart, the difference between the control and treatment groups is much larger than that in the Phase I chart. Eyeballing, it looks like the difference between the control and treatment groups in Phase II eventually reaches ~10 points, not 4.5.
The quote from the Phase II report in your post says:
What this seems to be saying is they ran a linear regression model to fit a non-linear line, and the regression says that PHQ-9 scores decreased by 4.5 points in the treatment group, plus 0.86 points for every 2 sessions attended. So, for example, someone in the treatment group who attended 12 sessions (as 91% of women in the treatment group did) would get a 4.5 + 6*0.86 = 9.66 point drop over someone in the control group who attended 0 sessions.
A bit confusingly, the Phase I report described the result with the same kind of linear regression model:
But for Phase I, the effect associated with being in the treatment group controlling for sessions attended (5.1 points) is what matches the treatment-control gap eyeballed from the Phase I line chart.
It looks like there are differences between Phase I and Phase II regarding how the control group was handled. In the Phase I line chart, there are several PHQ-9 datapoints for the control group; in the Phase II chart there are only two, one at the beginning and one at the end. It looks like in Phase I, women in the control group took the PHQ-9 weekly, and this was counted as a “visit” in the regression model. In contrast, in Phase II, only the treatment group had visits that were counted that way (except perhaps for the beginning and end of the trial).
So I think it makes more sense to say that Phase II ended up finding a ~10 point decrease between the treatment and control groups, and Phase I a 5.1-point decrease, but with the obvious caveat that the difference was due to Phase II control group members not being surveyed as much. It doesn’t seem like you can answer the question “how much of the effect is due to the treatment, and how much due to being surveyed multiple times?” using Phase II data.
Yes, I agree with this—editing the post to make this correction
I think posts of this kind are incredibly useful, and I’m also impressed by the discussion in the comments. Discussions like this are a key part of what EA is about. I’m curating the post.[1]
Assorted things I appreciated:
Clear claims and actionable takeaways, aimed at specific organizations
The author really digs into the different models (e.g. the Founders Pledge model) and writeups (the list of independent evaluations)
The structure: there’s a summary and there are sections
Note: I don’t want to say that I endorse all of the post’s conclusions. I don’t think I’m qualified to say that with confidence, and I’m worried that people might defer to me thinking that I am in fact confident.
Personally, I have been confused about how to understand the various reports that were coming out about StrongMinds, and the discussion here (both in the post and in the comments) has helped me with this.
I think the discussion in these comments has been impressively direct, productive, and polite. I’ve enjoyed following it and want to give props to everyone involved. Ya’ll make me proud to be part of this community.
I noticed there’s no reference for this quote. Where did you find it? What is the evidence for this claim?
Sean Mayberry, Founder and Executive Director, and Rasa Dawson, Director of Development on May 23, 2019.
From the Givewell discussion linked.
Thanks for clarifying. I think it would be helpful for readers if you edited the post to make that clear.
I did that at the same time as replying to you? Or do you mean something different?
It’s still not clear who is making the claim unless you click on the link. Here’s my suggested wording (feel free to ignore).
Re:
As anecdotal evidence, I’ve been tracking my mental health with a similar inventory (the Becket Depression inventory, which is similar but has 21 items rather than 9) for a few years now, and this tracks.
On your comment about what exactly the 0.66 QALY means, there is extensive public discussion about how to assign a QALY weighting to moderate-to-severe depression in the NICE guidance on esketamine
https://www.nice.org.uk/guidance/ta854/history
(Download the ‘Committee Papers’ published on 28th Jan 2020)
I’m not sure if any of that is helpful, but it might give some useful upper and lower bounds
Thank you! It’s 876 pages long—could you provide a page reference too please